View dev post on my website
RankRat is a distributed ranking app built with Go, HaProxy, Lua, Redis, and React. The application allows users to create personalized ranking 'games' of their choosing. Games are keyed by a game code, allowing global secure access to the game. First and foremost, RankRat is built with reducing latency in mind. We use a backend architecture that consists of three main parts: a reverse HaProxy server to help distribute load, a sink server to handle all non-gameplay requests (creating games and data interaction), and several horizontally scaling game servers. In this post, we'll go through some of the low-level architectural decisions that help us achieve high availability and low-latency for all users.
RankRat allows users to generate rankings about anything with feedback from thousands or even millions of other people. From High School Superlatives to debating what the best Ice Cream flavor is, RankRat can gather feedback from millions of users in a way never seen before. To generate true rankings, we use Microsoft's TrueSkill rating system, which assigns a rating (Mu) and a 'confidence' about the rating (sigma) to each player. Essentially, it treats each player's rating as a Normal distribution.
Games can be created in an instant, and require only a list of questions/superlatives and a list of 'candidates'. We generate a unique rating per candidate per question based on user input - in a given round, a question/superlative pops up along with 4 candidates and the user chooses the best option. This in turn updates the rating system.
This is not the first iteration of this platform. Initially, I created an online superlatives application for a Business Fraternity called Alpha Kappa Psi at Georgia Tech, called AKPsi Versus. While it worked quite well for our use case, there were some glaring issues with the platform:
- Under heavy load, games would take a very long time to load due to initial serverless architecture
- ELO rating system would not capture true ratings at times
- Prone to outages
- etc.
So, when I started thinking about generalizing this platform, there were two clear challenges:
- How do we ensure high availability while keeping latency low?
- How do we truly capture ratings/rankings
The goals of this project were to address the concerns outlined directly above:
- Games should load with low-latency
- Service should have high availability
- Service should be able to scale properly if required
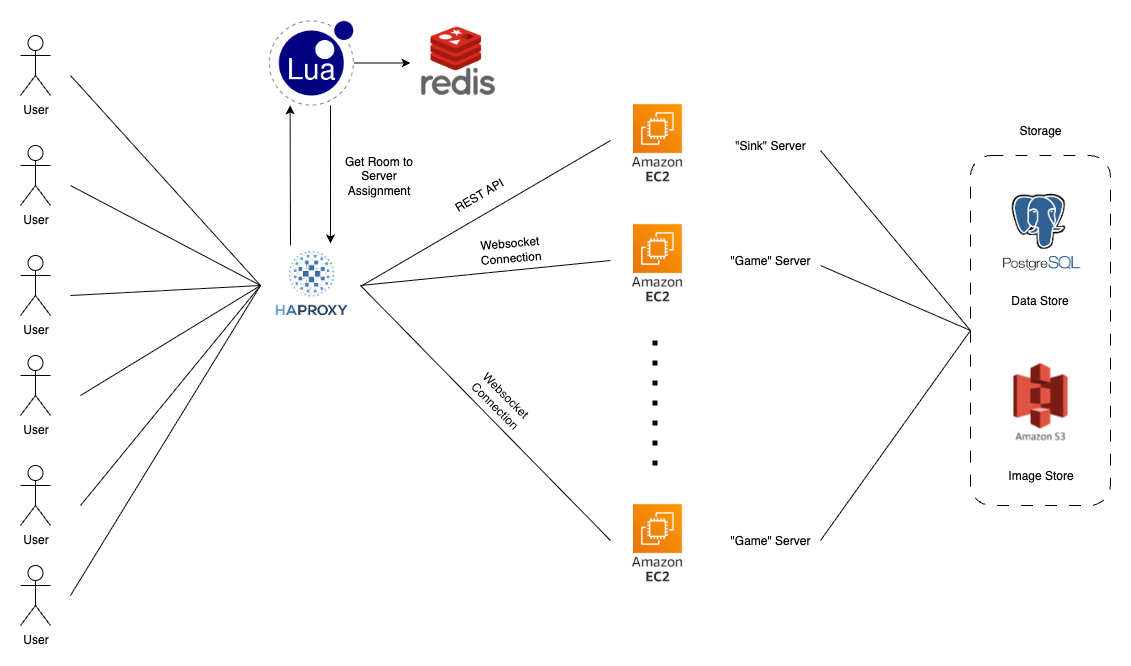
To acheive the goals I outlined, I settled on the architecture above. To motivate the reasoning behind a reverse proxy, the actual 'gameplay' doesn't require a lot of heavy logic - we just need to randomly sample 4 candidates, a question, and write rating updates to the game. So, a critical bottleneck is performing the reads and the writes to our storage device. If we have game handling logic sharded across multiple servers, we'd have to worry about maintaining consistency on a shared data resource as well as the increased latency that is introduced with some external data store.
However, instead, we introduce a paradigm: all connections for a given game are handled on the same server. This allows us to first, handle concurrency within the server with better locking primitives and second, avoid writes to the database on the critical path. So, this is exactly what we do. This allows us to scale efficiently and gives us significant performance gains.
Logically, we can separate this into three sections: the Reverse Proxy, the Sink Servers, and the Game Servers.
Note, game requests are websocket connections.
The reverse proxy has the responsibility of routing the game requests to the proper server. If a request is not a game request (creating a game, viewing leaderboard, etc...) we send it to a sink server designed to handle all such requests. It is critical that all of this happens in a time-sensitive manner. For this reason, I chose to use HaProxy for a couple of reasons:
- It's blazing fast
- Easy to setup
- Built in support for websocket connections (most important)
However, there is one big problem - where do we store the mappings and how do we handle the routing logic. This is where the second, and most important, part of the proxy come into play: the Lua script and Redis connection. The script contains the logic that determines if the incoming request is indeed a game connection and routes it to the proper server based on the data from the Redis store. The Redis store contains a simple mapping from the room id to the server (ex: "room123:server1").
This was really annoying but basically connecting to a redis instance via lua requires a specific IP address and a port. The port is easy, but there aren't many (cheap) services that expose a IP for a redis instance. So, I had to essentially bind a dummy port within my HaProxy instance that points to an external service that actually hosts the redis instance. This all leads to increased latency, but it worked so.
The game server presents a unique problem. While the actual logic is very lightweight, and we shard the traffic accross multiple servers, we still have to manage potentially thousands of concurrent websocket connections. The lightweight and numerous nature of the connections put this in an odd spot. It isn't exactly heavyweight enough to be its own process, but it is perfect for threads. This scales well for 10s of threads for most languages, but when we reach the thousands, we need Go: purpose built for concurrency. The Go routine is perfect for this. Go routines are lightweight threads managed by the Go runtime in user space. They run in the same address space, making them perfect for managing shared resources as well.
So, for each websocket connection, we spawn a go routine that manages the rating updates as well as sends new rounds to the users. Critically, it also manages updates to the PostgreSQL database off the critical paths, shaving latency. Obviously, we want to avoid database reads/writes. To avoid pulling in data from the database, we implement an approximate LRU cache to cache game data. Note, the eviction policy is Random Sampled LRU (Run LRU on a sampled subset of entries).
The sink server is relatively simple. It has a few core responsibilities:
Creating games is simple. We must first store the data in PostgreSQL and then store a mapping to the intended server in Redis. However, to determine this mapping, we want to ideally set the mapping to the least busy server. To do this, estimate current traffic from each server by counting the number of go routines in each server and we set the mapping to the least busy one.
Leaderboards are a famously difficult problem in system design. However - it's important to note that the logic is very lightweight due to the number of candidates being relatively low. So, instead of wasting critical server time on this problem, we can offload the actual logic to the frontend client. The backend sends a list of candidates along with their respective ratings, and the frontend handles the sorting.
In the past, I've been too lazy to do this, but I've had enough of public Amazon S3 buckets. The sink server also has the responsibility of presigning uploads and downloads to the S3 bucket that stores images.