

![]()
![]()
![]()
Flash-ANSR is a library for amortized neural symbolic regression: load a pretrained model, call fit(X, y), and recover a symbolic expression for your tabular data, or train your own model. It is built for fast, ready-to-use inference.
- Saegert & Köthe 2026, Breaking the Simplification Bottleneck in Amortized Neural Symbolic Regression (preprint, under review) https://arxiv.org/abs/2602.08885
Requires Python >= 3.12.
pip install flash-ansrimport torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Import flash_ansr
from flash_ansr import (
FlashANSR,
SoftmaxSamplingConfig,
install_model,
get_path,
)
# Select a model from Hugging Face
# https://huggingface.co/models?search=flash-ansr-v23.0
MODEL = "psaegert/flash-ansr-v23.0-120M"
# Download the latest snapshot of the model
# By default, the model is downloaded to the directory `./models/` in the package root
install_model(MODEL)
# Load the model (KV-cache, auto-batching and static decoding are on by default; see "Inference speed")
model = FlashANSR.load(
directory=get_path('models', MODEL),
generation_config=SoftmaxSamplingConfig(choices=1024), # or BeamSearchConfig / MCTSGenerationConfig
length_penalty=0.05, # prefer shorter expressions when scoring candidates (renamed from `parsimony` in v0.5)
).to(device)
# Define data: a small synthetic example, y = 2.5 * sin(x) + x^2 / 3
X = np.linspace(-5, 5, 100).reshape(-1, 1)
y = 2.5 * np.sin(X[:, 0]) + X[:, 0] ** 2 / 3
# Fit the model to the data
model.fit(X, y, verbose=True)
# Show the best expression
print(model.get_expression())
# Predict with the best expression
y_pred = model.predict(X)Get all candidates at once (infer): instead of fit + read-back, call model.infer(X, y), which returns an InferenceResult carrying the best Candidate, the score-sorted refined candidates, and the full CandidateLedger (the generation pool joined with the refined survivors, each classified FIT_OK / FIT_FAILED / INVALID).
result = model.infer(X, y)
print(result.best.expression_infix, result.best.fvu) # best refined candidate
for c in result.candidates: # score-sorted survivors
print(c.score, c.expression_infix)
print(len(result.ledger)) # all candidates consideredExplore more in the Demo Notebook.
Train your own: see the training guide and browse the pretrained model collection on Hugging Face.
Flash-ANSR v0.5 ships several inference-speed improvements, enabled by default and designed to be quality-neutral, so the quickstart above already runs in the fast regime. The speed-relevant settings live on the generation config:
| Setting | Default | What it does |
|---|---|---|
use_cache |
True |
KV-cache decoding |
batch_size |
'auto' |
candidate-budget-adaptive batching (pass an int to override) |
static_decode |
None |
static decoding, auto-enabled for capable models (set True/False to force) |
from flash_ansr import SoftmaxSamplingConfig
config = SoftmaxSamplingConfig(
choices=1024, # number of candidate expressions to sample
use_cache=True, # KV cache (default)
batch_size='auto', # candidate-budget-adaptive chunking (default)
static_decode=None, # auto for capable models (default)
)Constant refinement runs in parallel; control it via FlashANSR.load(..., refiner_workers=N, persistent_refine_pool=True). By default (refiner_workers=None) the pool uses every available CPU core, which oversubscribes shared machines; pass an explicit integer to cap it (0 disables multiprocessing).
To reproduce v0.4.x inference behavior, opt out of the new defaults:
SoftmaxSamplingConfig(choices=1024, use_cache=False, batch_size=128, static_decode=False)Breaking change (v0.5): the candidate-selection penalty
parsimonywas renamed tolength_penalty. Replace anyparsimony=arguments withlength_penalty=.

Results on the SRSD/FastSRB benchmark [Matsubara et al. 2022], [Martinek 2025] Left: Validation Numeric Recovery Rate (vNRR) as a function of inference time (log scale). FLASH-ANSR models (shades of blue) scale monotonically with compute, with the 120M model partially surpassing the PySR baseline (red). Baselines NeSymReS [Biggio et al. 2021] and E2E [Kamienny et al. 2022] fail to generalize to the benchmark. Right: Expression Length Ratio (predicted vs ground truth) versus compute. We observe a parsimony inversion: while PySR [Cranmer 2023] increases complexity to minimize error over time, FLASH-ANSR converges toward simpler, more canonical expressions as the sampling budget increases. Shaded regions denote 95% confidence intervals. |
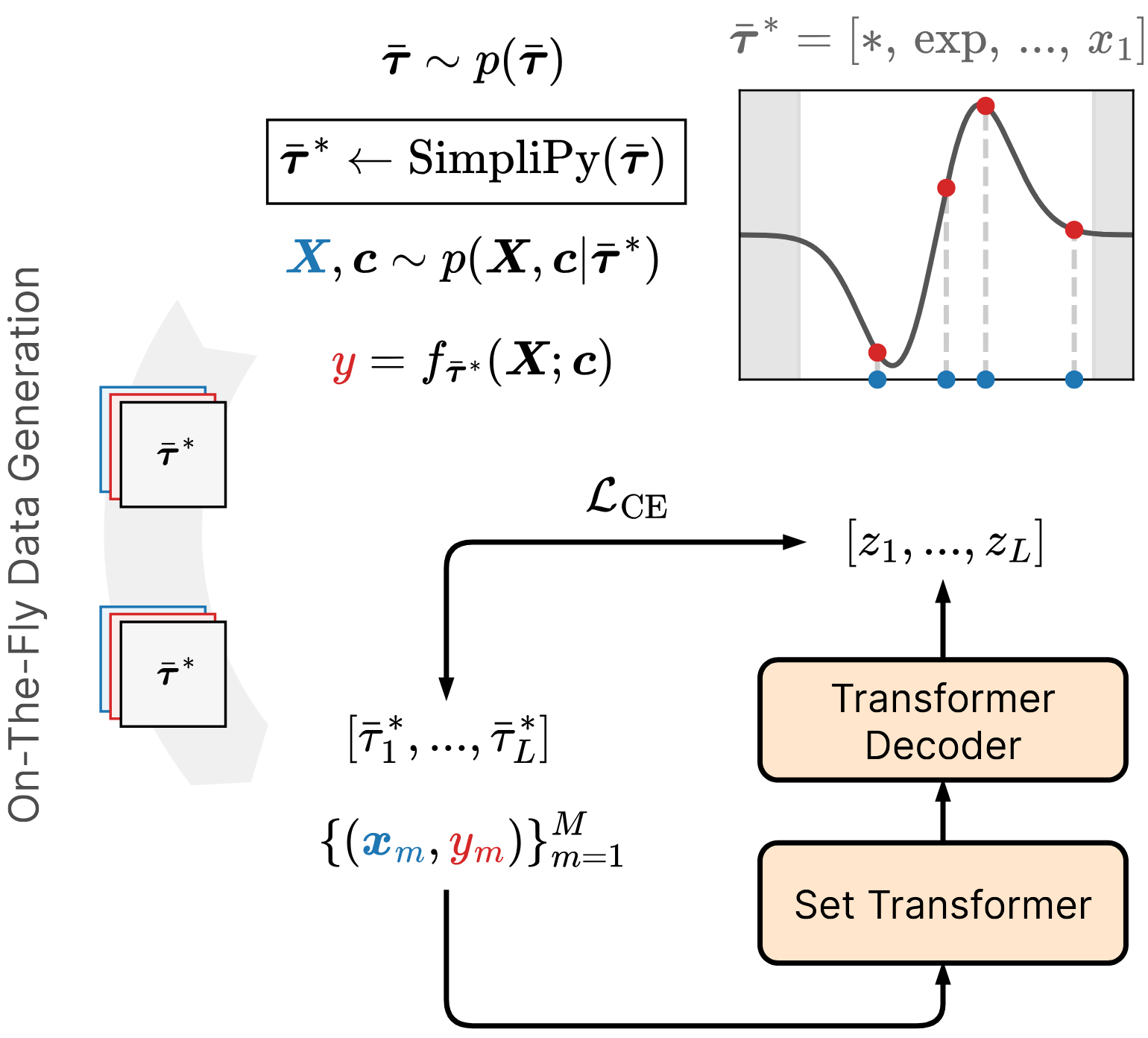
The Flash-ANSR training pipeline. Following the established standard encoder-decoder paradigm, our framework integrates SimpliPy (top center) into the loop for synchronous simplification of on-the-fly generated training expressions. |

Flash-ANSR model architecture. The Set Transformer [Lee et al. 2019] encoder ingests a variable-sized set of input-output pairs and produces a fixed-size latent representation via Induced Set Attention Blocks (ISAB) and Set Attention Blocks (SAB). The Transformer decoder [Vaswani et al. 2017], [Xiong et al. 2020] autoregressively generates a symbolic expression token-by-token, attending to the encoded dataset at each step. |
- SimpliPy: the expression simplification engine integrated into the Flash-ANSR training loop.
- symbolic-data: the model-agnostic symbolic-regression data layer (catalogs,
ProblemSource, holdouts) that feeds Flash-ANSR training. It is an unconditional runtime dependency and the backbone of the training loop. - srbf: the companion symbolic-regression evaluation and benchmarking framework (engine, model adapters, benchmarks, metrics), developed alongside Flash-ANSR.
@misc{saegert2026breakingsimplificationbottleneckamortized,
title = {Breaking the Simplification Bottleneck in Amortized Neural Symbolic Regression},
author = {Paul Saegert and Ullrich Köthe},
year = {2026},
eprint = {2602.08885},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2602.08885},
}
% Optionally
@mastersthesis{flash-ansr2024-thesis,
author = {Paul Saegert},
title = {Flash Amortized Neural Symbolic Regression},
school = {Heidelberg University},
year = {2025},
url = {https://github.com/psaegert/flash-ansr-thesis}
}
@software{flash-ansr2024,
author = {Paul Saegert},
title = {Flash Amortized Neural Symbolic Regression},
year = {2024},
publisher = {GitHub},
version = {0.10.0},
url = {https://github.com/psaegert/flash-ansr}
}