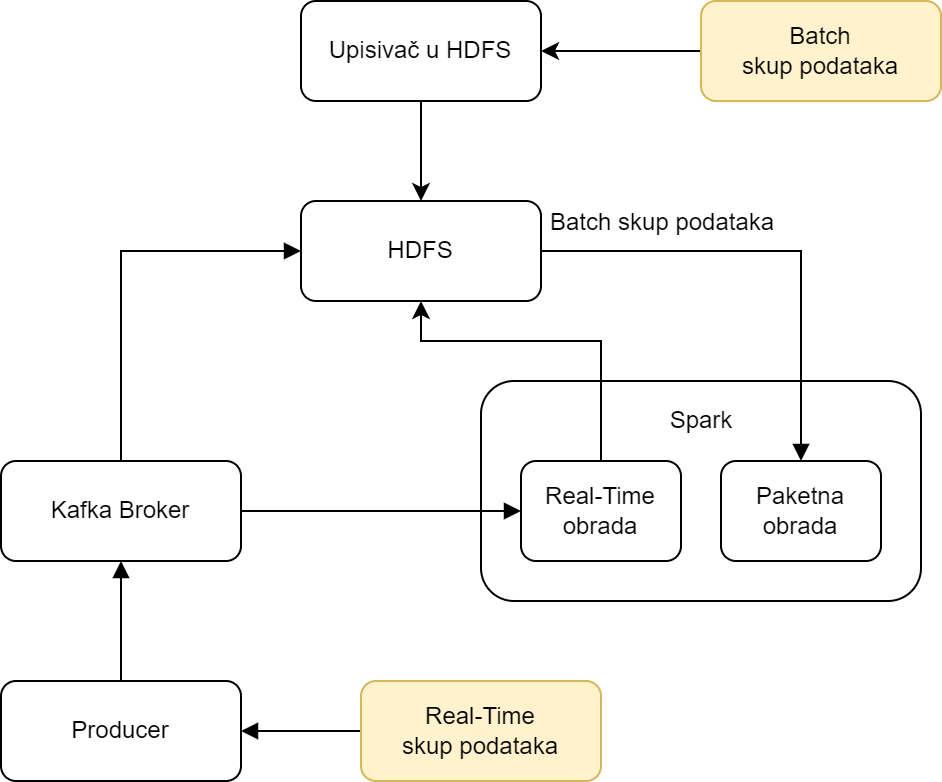
Motivation for this project was to create a system architecture for storing large amount of car data, its efficient batch and streaming processing in order to get useful information from the data.
Technologies used: Apache Hadoop, Apache Spark, Apache Kafka, Metabase, PostgreSQL, Airflow, Druid, Docker
- Create "datasets" directory in the root directory
- Download batch and streaming datasets from these 2 links:
- https://www.kaggle.com/cisautomotiveapi/large-car-dataset
- https://www.kaggle.com/austinreese/craigslist-carstrucks-data
- Download PostgreSQL JDBC Driver v42.3.0 in jar format for saving processed data to database
- Go to "batch" directory and start docker-compose
docker-compose up --build
- Go to "upload_data" directory and run command below to transfer datasets to HDFS
./docker_copy.sh
- Go to Airflow URL http://localhost:8282/ and run "batch-dag"
- All batch queries will be applied to the batch dataset
- Also, 2 tables will be created for data visualization - "price_decline" and "num_of_ads"
- Go to Metabase URL http://localhost:3000/ and run SQL queries for data visualization
- Create SQL query below to visualize car model's price decline per year
SELECT "brandName", "modelName", "vf_ModelYear", "AvgPrice", "PriceDiff", "TotalCars" from price_decline
WHERE "modelName" = {{modelname}}
GROUP BY "modelName", "vf_ModelYear", "brandName", "AvgPrice", "PriceDiff", "TotalCars"
ORDER BY "vf_ModelYear" desc;
- Set "vf_ModelYear" as x-axis and "AvgPrice" for y-axis
- Go to "streaming" directory and run:
./docker-run.sh
- After producer starts filling up Kafka broker with the data, in another terminal run:
./spark-jobs-run.sh