An 8-stage vulnerability-discovery agent, driven by your Claude Pro / Max subscription through the official Claude Code Agent SDK. Many narrow agents, deliberate disagreement, and an explicit reachability gate.
MIT-licensed. No API key needed if you already use claude login.
This project is a from-scratch reimplementation of the pipeline described in Cloudflare's Project Glasswing post, which tested Anthropic's Mythos preview LLM against Cloudflare's own codebase. The blog argues that real-world vulnerability discovery does not come from asking one big model "find bugs here" — it comes from:
- Many narrow agents working in parallel on tightly-scoped questions ("Look for command injection in this specific function, with this trust boundary above it") rather than one exhaustive agent.
- Deliberate disagreement — a second agent, on a different model, that tries to disprove the first agent's findings.
- A reachability trace as the gating step — most "is this code buggy?" findings are noise unless an attacker-controlled input can actually reach the sink from outside the system.
- A feedback loop so reachable bugs in one place automatically seed hunts for the same pattern elsewhere.
This repo packages that pipeline into a runnable agent. The Cloudflare post showed the architecture; this codebase ships the prompts, schemas, state store, and orchestrator.
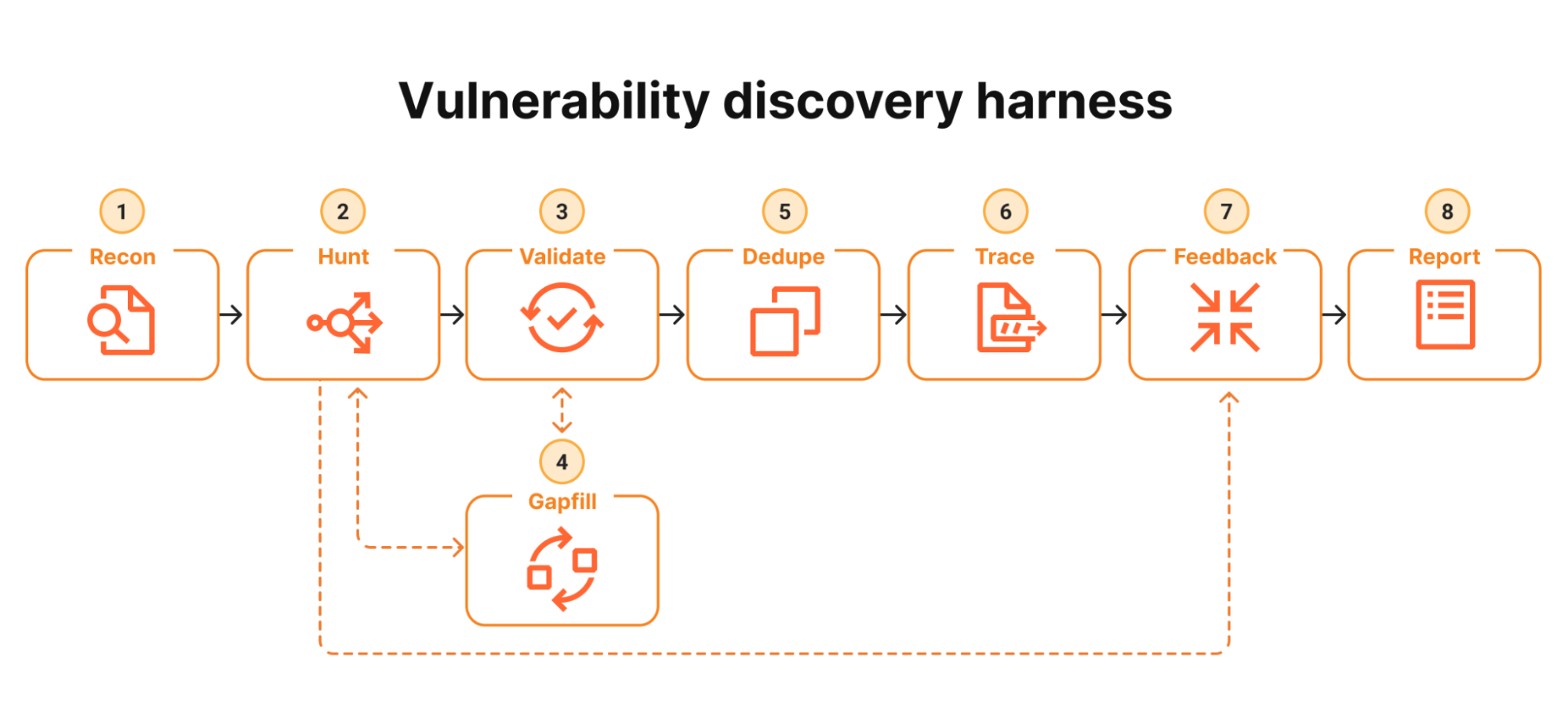
Diagram from Cloudflare's Project Glasswing post, reproduced here for reference.
| # | Stage | Default model | Purpose |
|---|---|---|---|
| 1 | Recon | Opus 4.7 | Map the repo, emit narrowly-scoped Hunt tasks |
| 2 | Hunt | Sonnet 4.6 | One attack class per agent; compile/run PoCs |
| 3 | Validate | Opus 4.7 | Adversarial re-read; tries to disprove (different model from Hunt) |
| 4 | Gapfill | Sonnet 4.6 | Re-queue under-covered areas |
| 5 | Dedupe | Sonnet 4.6 | Cluster findings by root cause |
| 6 | Trace | Opus 4.7 | Prove attacker-controlled input reaches the sink |
| 7 | Feedback | Sonnet 4.6 | Turn reachable traces into new Hunt tasks |
| 8 | Report | Sonnet 4.6 | Schema-validated structured report |
Each stage is one markdown prompt in prompts/ + one JSON Schema in
schemas/. The orchestrator passes the schema into the system prompt so
every output is shape-stable on the first try.
# 1. Install
python -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Auth (pick one)
# (a) Already logged in via claude login? You're done.
# (b) Or generate a 1-year OAuth token for CI / non-interactive use:
claude setup-token
echo "CLAUDE_CODE_OAUTH_TOKEN=<paste>" > .env
# 3. Verify
audit auth-check
# 4. Run
audit run --repo /path/to/target --run-id my-run
audit status --run-id my-run
audit report --run-id my-run --format md > report.mdBy default the agent uses subscription billing via your Claude.ai
login — it does not call the metered Anthropic API. The on-disk auth
module scrubs ANTHROPIC_API_KEY from the environment so it can't
silently route around the OAuth flow.
The auth module picks one of three modes, in this order:
- LLM gateway (OpenRouter, custom proxy, etc.) — when
ANTHROPIC_BASE_URLpoints away fromanthropic.comANDANTHROPIC_AUTH_TOKENis set. The gateway env is left intact; onlyANTHROPIC_API_KEYis scrubbed (it would otherwise outrank the gateway token). - Subscription OAuth (headless) —
CLAUDE_CODE_OAUTH_TOKENfromclaude setup-token. Best for CI. - Subscription OAuth (interactive) —
~/.claude/.credentials.jsonfromclaude login. Best for local dev.
OpenRouter exposes Claude-compatible Anthropic-API endpoints behind its own credit system; that lets you spend OpenRouter credits instead of an Anthropic subscription, and gives you access to Sonnet/Opus and other models through the same SDK path. See OpenRouter's Agent SDK guide.
export ANTHROPIC_BASE_URL="https://openrouter.ai/api"
export ANTHROPIC_AUTH_TOKEN="$OPENROUTER_API_KEY"
export ANTHROPIC_API_KEY="" # must be explicitly empty / unset
# optional: pick a non-Anthropic model
export ANTHROPIC_MODEL="anthropic/claude-sonnet-4-6"
# or e.g.: ANTHROPIC_MODEL="openai/gpt-5"
# ANTHROPIC_MODEL="google/gemini-2.5-pro"
# ANTHROPIC_MODEL="qwen/qwen3-coder-480b"
audit auth-check # confirms "using LLM gateway at https://openrouter.ai/api"
audit run --repo /path/to/target --run-id orun --max-cost-usd 30Caveats:
- Per-stage model overrides in
config/stages.yamlare model names (e.g.claude-opus-4-7); OpenRouter accepts slash-prefixed forms likeanthropic/claude-opus-4-7. Edit the YAML if you want different providers per stage. OtherwiseANTHROPIC_MODELforces every stage onto one model. - Non-Claude models may not produce schema-compliant JSON as reliably. The runner's schema-validation + repair turn still applies; quality varies by model.
- Tool-use semantics (Read/Grep/Glob/Bash) are part of the Claude Code CLI, not the model — they work as long as the gateway speaks the Anthropic Messages API.
Same recipe — anything that exposes the Anthropic Messages API at a URL
- a bearer token works:
export ANTHROPIC_BASE_URL="https://your-proxy.example.com"
export ANTHROPIC_AUTH_TOKEN="$YOUR_TOKEN"
unset ANTHROPIC_API_KEYFor Amazon Bedrock / Google Vertex / Microsoft Foundry, Claude Code has
first-class env-var flags (CLAUDE_CODE_USE_BEDROCK=1 etc.) that
outrank everything else. See the Claude Code auth docs.
A real production codebase can produce 15-50 Hunt tasks and 25+ findings to validate. At default concurrency this gets expensive. Flags to keep it sane:
audit run --repo /path/to/target \
--max-concurrency 1 \ # one claude subprocess at a time
--max-recon-tasks 15 \ # cap initial Hunt fanout
--max-cost-usd 30 # abort cleanly if exceededThe budget guard fires between and within stages — a per-task check in Hunt cooperatively aborts rather than running 30 more tasks past the cap.
If the target has a running deployment, point the agents at it. Hunt now reproduces each finding against the live service instead of compiling a local PoC, Validate rejects findings that don't reproduce, and Trace confirms reachability with real HTTP round-trips. The static path remains available — these flags are opt-in.
audit run --repo /path/to/target --run-id live \
--max-concurrency 1 --max-cost-usd 30 \
--target-url http://server.local:8888 \
--target-creds email=admin@system.com \
--target-creds password=changechangemeRules the agents follow when --target-url is set:
- Network egress is restricted to that host +
127.0.0.1. No other external hosts. - A finding that doesn't reproduce against the live target is dropped or rejected (depending on stage) — "no fabrication".
- Credentials flow into every relevant stage's user_input as a dict.
Targets often have intentionally-loose-by-design surfaces that aren't bugs (e.g. plaintext API keys when that's a feature, test-only Mailpit endpoints, anonymous-analytics ingest). Drop them in a text file and pass it in — the notes are appended verbatim to every stage's user_input, and Recon / Hunt / Validate honor exclusions you list.
audit run --repo /path/to/target --scope-notes target_scope.mdExample target_scope.md:
- Mailpit (port 1025) is test-only; ignore.
- Plaintext API keys in the database are a required feature.
- Don't flag rate-limit absence on anonymous /ping endpoints.
- Only consider critical/high severity.Recon greps the git history for past security patches
(CVE, sec:, fix.*auth, sanitize, …) — patched files are hardened,
but sibling files with the same idiom often aren't. Findings get seeded
against the unpatched copies. Adds zero cost on repos without that pattern;
catches real cross-component bugs on repos that have it.
The pipeline's default is one-attack-class-per-task (the Cloudflare paper's
narrow-scope rule). Recon can also emit logic_chain tasks for high-impact
multi-component paths (auth-bypass + IDOR + path-traversal that compose into
RCE, etc.) — one chain per task, with the scope_hint naming the specific
chain. This is the one allowed exception to single-attack-class scoping.
prompts/ 8 stage prompts (markdown, loaded as system prompts)
schemas/ 9 JSON schemas — every agent output is validated
config/ stages.yaml — model + concurrency + tool allowlist per stage
audit/ Python package
auth.py OAuth check + ANTHROPIC_API_KEY scrubbing
state.py SQLite DAO (runs, tasks, findings, traces, dedupe, costs)
runner.py claude-agent-sdk wrapper with schema validation + repair turn
orchestrator.py pipeline driver
stages/ one module per stage
work/ per-Hunt-task scratch dirs (sandbox for PoC compile/run)
results/ JSONL artifacts per stage + final report.json
state.db SQLite (gitignored)
Hunt agents have Bash and run inside per-task scratch dirs. They are not sandboxed at the OS level. Run the audit inside a disposable VM or container when you don't trust the target source — a target with malicious build scripts could otherwise execute on your host during PoC compilation.
The agent reads everything you --add-dir, including any .env or
secrets/ directories in the target. Outputs land in results/<run-id>/
which is .gitignored but not scrubbed of those reads.
MIT. Reuse freely. No warranty.
- The pipeline design is from Cloudflare's Project Glasswing blog post. The credit for the architecture goes there.
- Built on the official Claude Code Agent SDK.