Benchmark matrix: per-target AOI override (latitude studies + 88S stress target)#123
Conversation
 espg
left a comment
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Adversarial review of #123 against the #121 acceptance criteria and CLAUDE.md. Net: meets the acceptance bar. Verified locally on Python 3.12: the 4 new tests pass, full test_benchmark.py is green (23 passed, 3 skipped), the drift test still collects its 4 params, and ruff check / ruff format --check are clean on both touched test files.
Acceptance check:
- Byte-identical fallback (the load-bearing guarantee): holds.
resolve_aoi_temporal_cmrreturnssm_meta.get(key, MANIFEST[key]), so a no-override entry gets the same object by identity. All four existing shard maps intargets.json(healpix_o11,healpix_o10,rect_3km,rect_6km) carry noaoi/temporal/cmroverride, andtest_override_resolution_falls_back_to_defaultsassertsisidentity — NEON resolves exactly as before. - Drift test uses resolved values: the old
cmr, temporal, aoi = MANIFEST[...]top-level reads are replaced byresolve_aoi_temporal_cmr(sm_meta). Correct, and it fixed the previously-reversed unpack order as a side effect. - Runner + CI unchanged: confirmed via
git diff origin/main...HEAD— onlytests/data/benchmark/{README.md,antarctic_88s.geojson},tests/test_benchmark.py,tests/test_benchmark_shardmap.pychanged.run_benchmark.py,lambda-benchmark.yml, andtargets.jsonare untouched. - Coverage: exercises override-used, default-inherited, and partial-override — good.
- README ↔ code: the recipe's key names (
aoi.file,temporal,cmr) and the catalog CLI flags (--config/--short-name/--version/--start-date/--end-date/--polygon/--backend/--output) all match the resolution code andsrc/zagg/catalog/__init__.py. - No CLAUDE.md violations: no deps added, no CI/infra touched, no new
# noqa(the# noqa: E402is pre-existing), both files well under the ~1000-line limit.
Findings are nits only (inline). Nothing blocks.
Generated by Claude Code
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Inline nits attached (4). All non-blocking — see the earlier top-level review for the full acceptance-criteria pass. Verified locally on Python 3.12: new tests green, test_benchmark.py 23 passed / 3 skipped, drift test collects, ruff clean. Byte-identical NEON fallback, resolved-AOI drift test, and untouched runner/CI/targets.json all confirmed.
Generated by Claude Code
| sm_meta.get("aoi", MANIFEST["aoi"]), | ||
| sm_meta.get("temporal", MANIFEST["temporal"]), | ||
| sm_meta.get("cmr", MANIFEST["cmr"]), | ||
| ) |
There was a problem hiding this comment.
🤖 from Claude (review)
Nit (non-blocking): resolve_aoi_temporal_cmr returns the manifest dicts by reference, so a caller that mutated aoi/temporal/cmr would mutate the shared MANIFEST default for every other entry. Current callers (drift test, the three new unit tests) only read, so this is safe today — flagging only so the contract ("returns shared references, treat read-only") is explicit if a future caller mutates the result. No change needed now.
Generated by Claude Code
|
|
||
| ```json | ||
| "shardmaps": { | ||
| "healpix_o11_88s": { "path": "shardmaps/sm_healpix_o11_88s.json", |
There was a problem hiding this comment.
🤖 from Claude (review)
Nit (non-blocking): the override example shows only an aoi override and says "Omit temporal/cmr to inherit." Worth one clarifying line that a cmr override, when used, needs short_name/version/provider/footprint (the keys the drift test reads) but not backend — the drift test reads backend from the committed shard map's metadata.backend, not from cmr. Without this, a future author may copy the top-level cmr (which does carry backend) and assume cmr.backend is consulted. Matches the test fixture in test_override_resolution_uses_overrides, which correctly omits backend.
Generated by Claude Code
| # A shard map with no override inherits the top-level aoi/temporal/cmr | ||
| # *by identity* -- existing NEON entries resolve byte-identically to today. | ||
| import test_benchmark_shardmap as drift | ||
|
|
There was a problem hiding this comment.
🤖 from Claude (review)
Nit (non-blocking): the override-resolution unit tests live in test_benchmark.py but import test_benchmark_shardmap as drift to reach the helper. That cross-imports a slow+skipif(ZAGG_BENCHMARK_DRIFT) module from the fast suite; it works because resolve_aoi_temporal_cmr/MANIFEST are module-level (the pytestmark skip only gates the test functions, not import), and it relies on bench_metrics resolving via the sys.path.insert(.github/scripts) that test_benchmark_shardmap performs at import. Confirmed green locally on 3.12. Just noting the coupling — these three tests would arguably read more naturally co-located with the helper in test_benchmark_shardmap.py (where the AOI-resolution logic lives), but that's a placement preference, not a defect.
Generated by Claude Code
| parts = load_polygon(str(BENCH / "antarctic_88s.geojson")) | ||
| minx, miny, maxx, maxy = polygon_to_bbox(parts) | ||
| assert miny <= -87.5 and maxy <= -87.0 # well into the high-density polar band | ||
| assert -90.0 <= miny < maxy <= -80.0 |
There was a problem hiding this comment.
🤖 from Claude (review)
Confirmed: fixture loads via the real load_polygon and the bbox assertions hold (miny=-88.0, maxy=-87.7). Honest-flagging is good — the docstring states the AOI ships before its built shard map / live target, and targets.json correctly has no healpix_o11_88s entry yet, so the drift test still parametrizes only the four existing NEON maps. One forward-looking note: when the 88°S shard map is added with its aoi override, test_targets_manifest_consistent will re-derive its densest shard from the committed map (AOI-independent, reads metadata), so the override won't perturb that test — but the drift test will then rebuild over the 88°S box, which (per the README) is expected to be a heavy/failing stress target. No action this PR.
Generated by Claude Code
|
There's still some warts in our benchmarking, and I'd like to address them and fix them in this PR before it merges:
You can test these changes for me to review so that I can confirm they're working as expected -- with out rerunning any benchmarks, since we can just read the parquet data and re-render the plots. Do that, and post an updated figure for me to review. You can do this by (ideally) posting the figure as a comment in this thread-- or as a (worse) fallback, by adding the png renders as git committed files (which we'll have to git rm from this branch later before merging). |
Lambda benchmark —
|
| target | obs | runtime (s) | cost/shard | cost/100 km² | % timeout | mem (MB) | % cap |
|---|---|---|---|---|---|---|---|
| gain_bias_healpix_o11 | 0 | 201.1 | $0.00536 | $0.05291 | 22% | n/a | n/a |
| tdigest_healpix_o11 | 200,676 | 192.3 | $0.00513 | $0.05060 | 21% | n/a | n/a |
| gain_bias_healpix_o10 | 0 | 280.9 | $0.00749 | $0.01848 | 31% | n/a | n/a |
| tdigest_healpix_o10 | 939,217 | 241.8 | $0.00645 | $0.01591 | 27% | n/a | n/a |
| gain_bias_rect_3km | 0 | 0.0 | $0.00000 | $0.00000 | n/a | n/a | n/a |
| tdigest_rect_3km | 207,911 | 189.7 | $0.00506 | $0.05620 | 21% | n/a | n/a |
| gain_bias_rect_6km | 0 | 241.4 | $0.00644 | $0.01788 | 27% | n/a | n/a |
| tdigest_rect_6km | 0 | 0.0 | $0.00000 | $0.00000 | n/a | n/a | n/a |
arm64 · 2.0 GB · $1.33334e-05/GB-s · one shard/target · pre-merge runs are not retained.
|
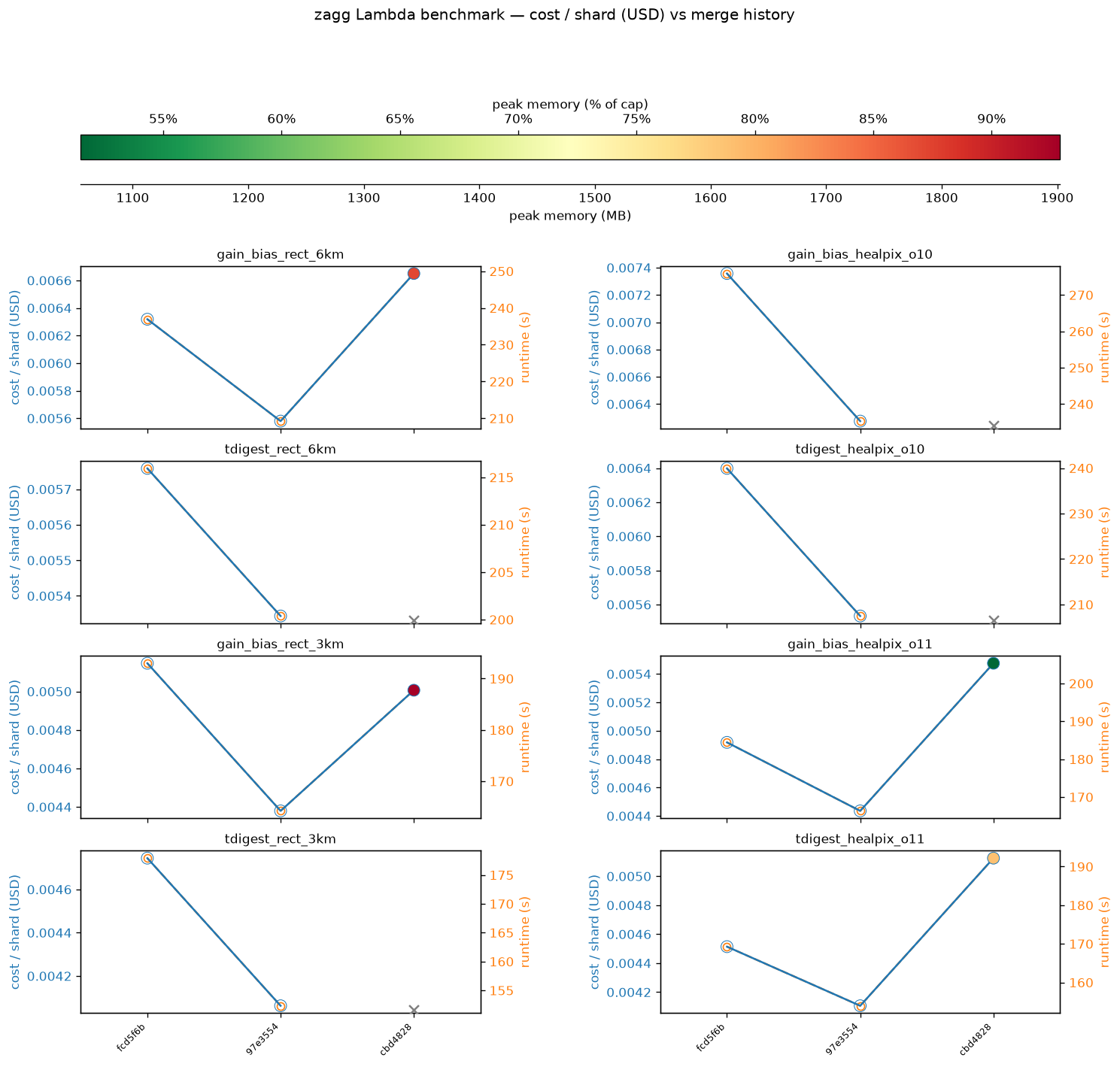
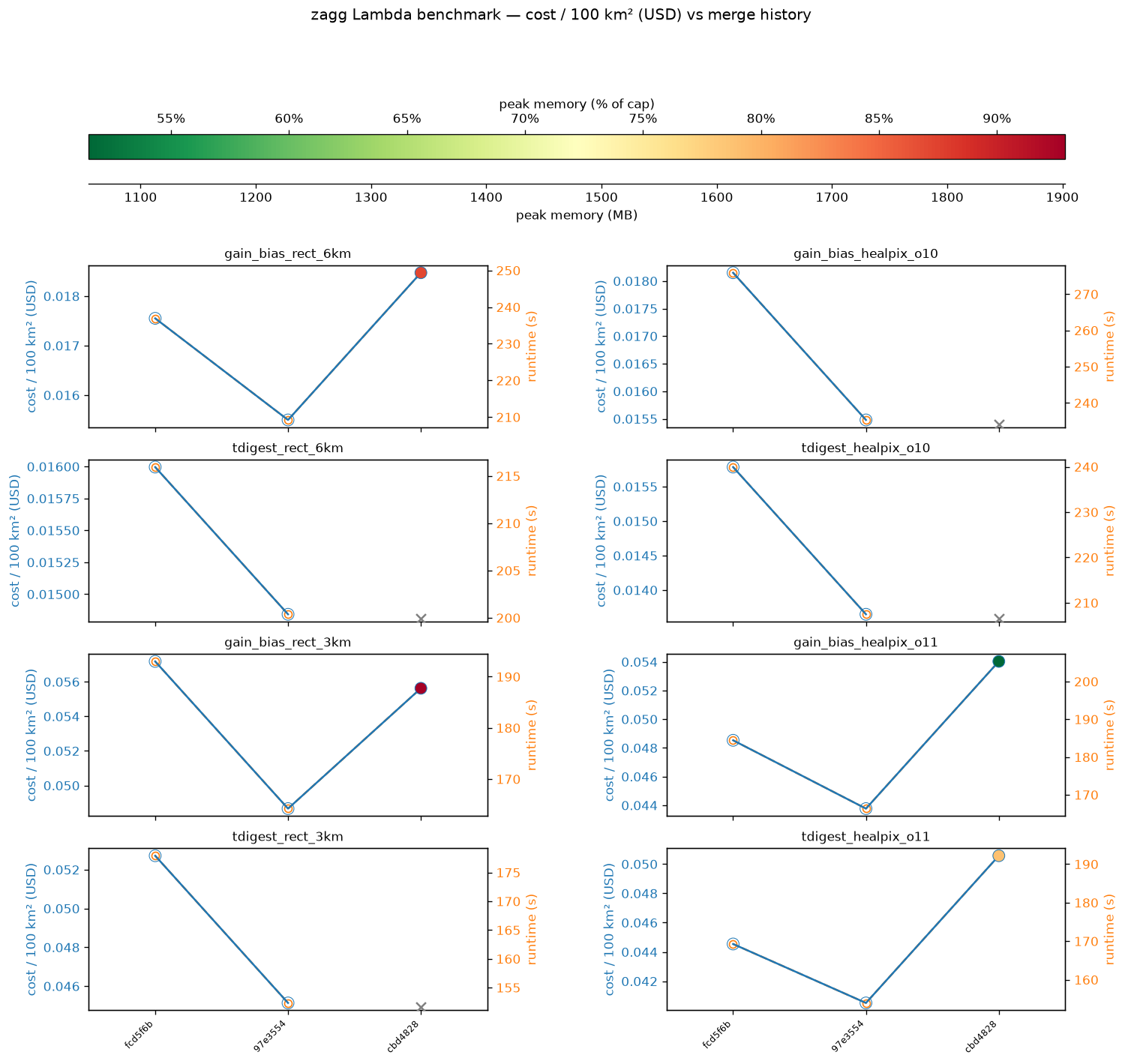
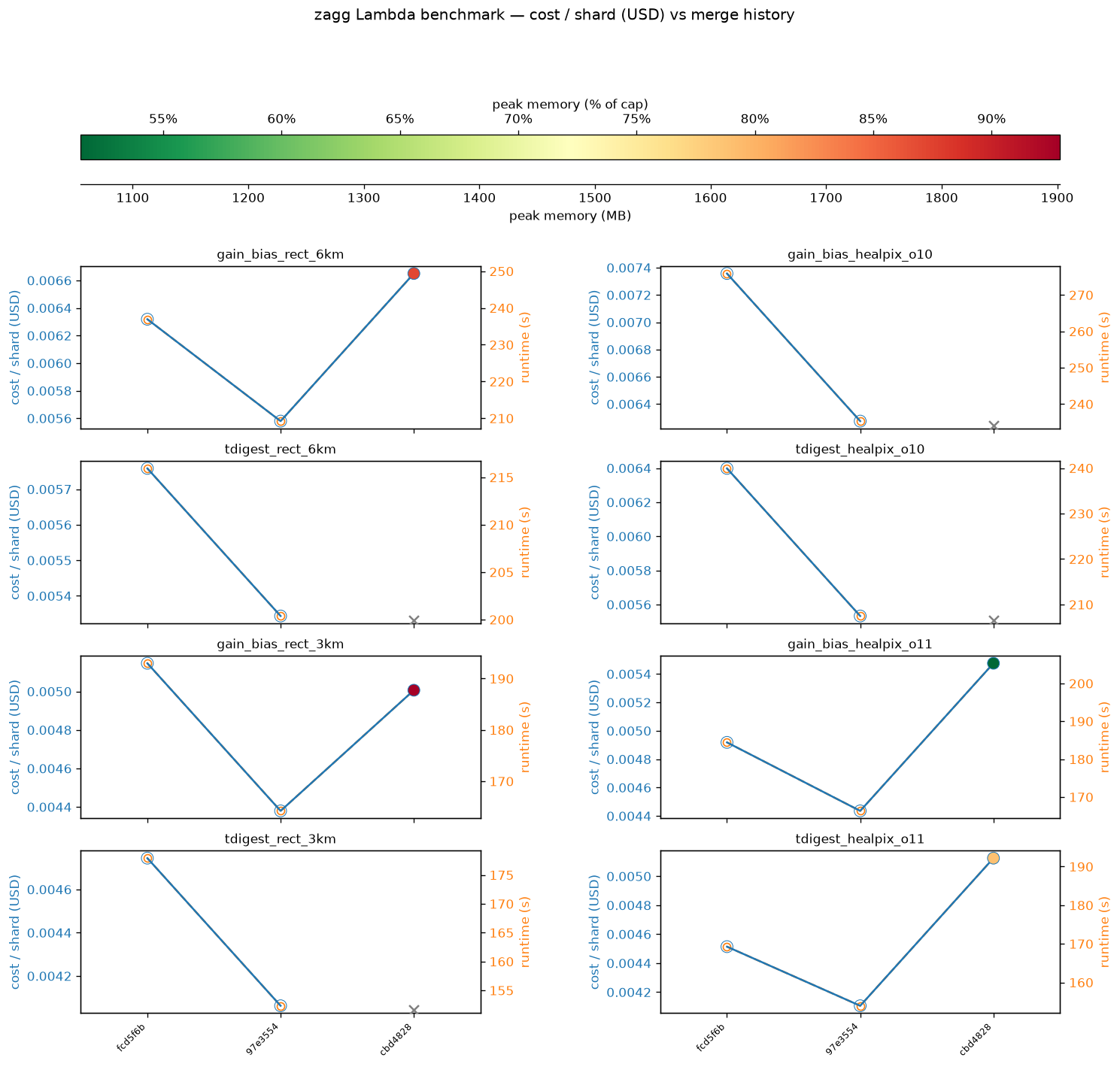
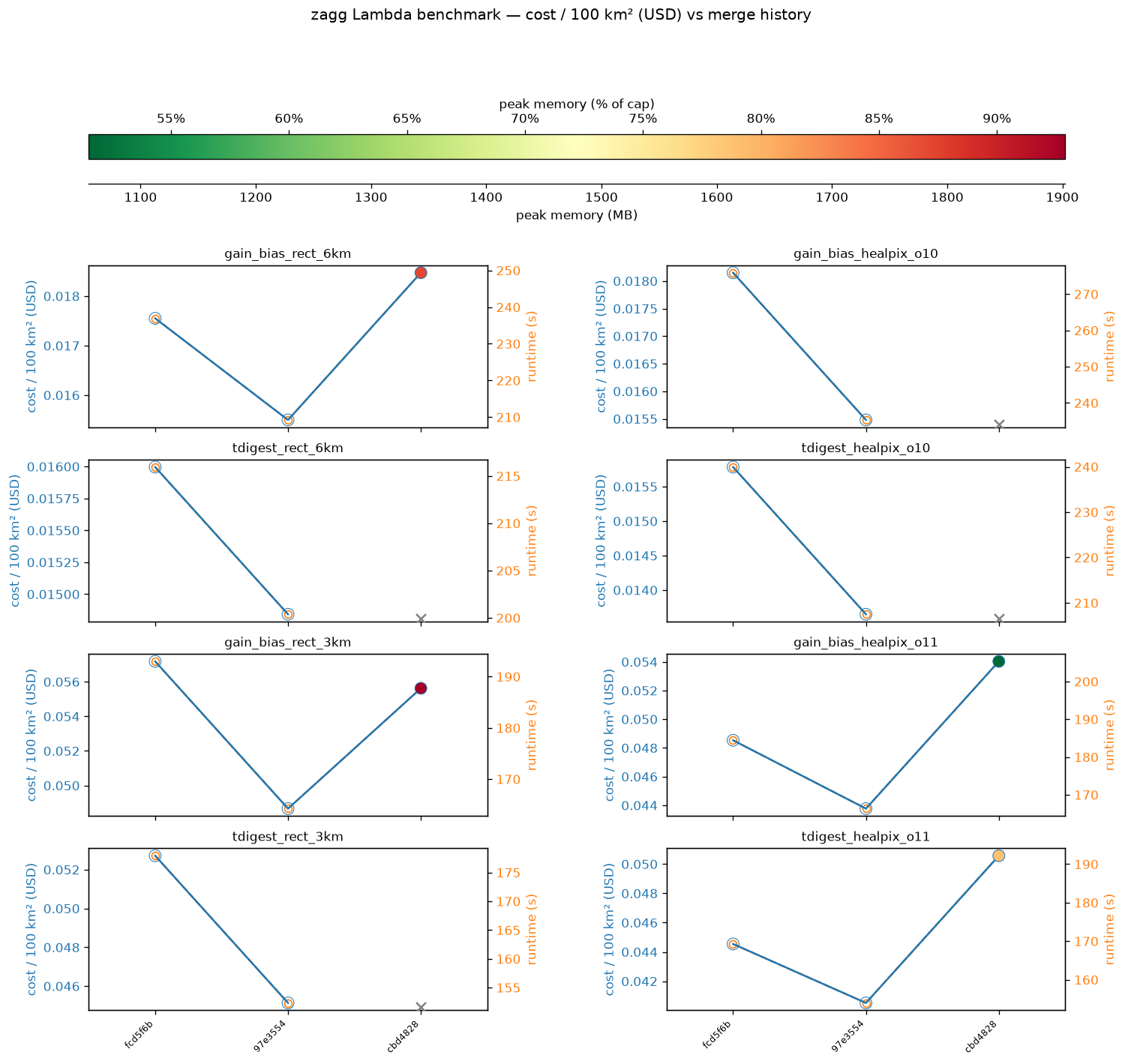
🤖 from Claude Folded the three benchmark-plot fixes from the review comment (4834632174) into this PR. All re-rendered from the committed What changed in
Preview renders (committed temporarily under
Notes:
The live 88S target is still deferred (needs a CMR fetch this routine can't reach) — see the "Questions for review" note in the PR description. Generated by Claude Code |
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Adversarial review of the latest phase (commits 59f35fb benchmark plot fixes + b7c7872 review renders), scoped to plot_series.py + tests/test_benchmark.py.
One real correctness bug in the shared-x labelling, plus a test that can't catch it. Details inline; summarised here:
-
Per-target x labels are wrong whenever targets don't all share the same commit set (correctness).
make_figurenow builds one global label list —labels = [str(c)[:7] for c in hist.drop_duplicates("commit").sort_values("timestamp")["commit"]]— and applies that same list to every bottom panel viabottom.set_xticklabels(labels), while each panel's data is plotted atxs = range(len(sub))(its own per-target merge count) and ticks are fixed atx = range(nx)withnx = max len over targets. The premise in the comment ("same merge points per target") does not hold in general: targets get added/removed over time, and the densest-shard run for a target can be skipped on a given merge, so per-target commit sets diverge. Two concrete failure modes, both verified by running the pushed code:- Mislabelled ticks. With t1 = merges {c1, c2} and t2 = {c0, c1, c2} (t1 missing the earliest merge), both panels render labelled
c0, c1, c2. t1's leftmost point is itsc1but is labelledc0— every t1 label is shifted by one and wrong. A reader comparing a regression against the wrong commit is the exact failure this chart exists to prevent. - Silent truncation, not the expected crash. With four targets carrying six distinct commits but only two each (
nx = 2,len(labels) = 6),set_xticklabelsdoes not raise (sharex + a later autoscale replaces the FixedLocator, so matplotlib clamps the label list silently); all bottom panels end up showing the last-applied 2 labels. So the length mismatch fails quietly rather than loudly.
The pre-fold code computed
labelsper-target fromsub["commit"]— that was correct. The fix is to keep labels per-target (label each bottom panel from its ownsub["commit"]), or to reindex every target onto a shared, ordered union of commits so position 0..k means the same commit in every panel. As written, "share one label list across panels" is only valid when all targets have identical commit sets. - Mislabelled ticks. With t1 = merges {c1, c2} and t2 = {c0, c1, c2} (t1 missing the earliest merge), both panels render labelled
-
The new test only exercises the uniform-data case, so it can't catch (1) (test strength).
test_make_figure_shared_x_and_circle_runtimebuildsrows = [_rec_row(f"c{i}", t) for i in range(2) for t in ("t1","t2","t3","t4")]— every target has the identical two commits {c0, c1}, which is exactly the one configuration where global labels happen to be correct. Add a case where targets have differing/uneven commit sets (e.g. one target missing an early merge) and assert each bottom panel's tick labels match that panel's commits, in order. That assertion fails on the current code. -
The runtime-marker and top-row-empty assertions themselves look sound.
markerscollects every line's marker across all axes and asserts"o" in markers and "s" not in markers— the cost connecting line uses"-"(markerNone), so"o"uniquely identifies the runtime line; robust. The top-vs-bottom split keys onget_subplotspec().rowspan.startand checksget_xticklabels()text is empty on the top row — that is a genuine assertion (it would catch labels leaking onto the top row), not a false pass, given matplotlib clears shared inner-tick labels. -
Review-render PNGs under
docs/deployment/_review_renders/(commitb7c7872) are binary artifacts that CLAUDE.md §3 says not to commit. Noting this is the authorized fallback ("remove before merge"); flagging only so it isn't forgotten —git rmthem before this PR goes ready/merges.
Everything else in the plot diff (hollow-circle runtime markers, s=60 scatter enlargement, horizontal location="top" colorbar, suptitle moved above the colorbar) matches the stated intent and reads cleanly. ruff passes. No other findings.
Generated by Claude Code
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Phase-3 plot-fix review (only 59f35fb + c7d7080; phases 1–2 already reviewed). I reproduced make_figure's logic with matplotlib on a 2×2 grid and confirmed all three asks land:
- Color show-through (#125): runtime markers are now hollow (
marker="o", markerfacecolor="none") and the cost scatter is enlarged (s=60); the green→red memory color reads through the runtime circle. ✓ - Shared x-axis:
sharex=Trueplus the per-column "last populated panel" labeling produces empty top-row tick labels and populated bottom-row labels — verified empirically. ✓ - Horizontal colorbar below title:
fig.colorbar(..., orientation="horizontal", location="top", ...)returnsorientation == "horizontal"with no error and sits above the panels / belowsuptitle. ✓
No correctness bugs found. The new test is meaningful, not a tautology — "o" in markers and "s" not in markers would fail on the old "s--", and the top-empty / bottom-populated label assertions would fail if labels were applied to all panels or none. Stays well under the ~1000-line limit; no new deps.
Two non-blocking nits inline plus the expected pre-merge cleanup of the authorized docs/deployment/_review_renders/*.png preview images (250 KB each, confirmed committed). None of these block readiness; fold at your discretion.
Generated by Claude Code
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Inline nits for the phase-3 plot diff (both non-blocking, fold at your discretion). Two more standing notes not worth an inline anchor:
- Colorbar args are redundant (cosmetic):
orientation="horizontal"together withlocation="top"—location="top"already implies a horizontal bar above the axes, soorientationis redundant. Harmless (they agree), but you could droporientation=for terseness. - Pre-merge cleanup: the authorized preview renders
docs/deployment/_review_renders/cost_per_shard.pngandcost_per_100km2.png(~250 KB each) are committed on this branch;git rmthem before marking ready/merging, as agreed on the thread.
Generated by Claude Code
| sub["runtime_s"], | ||
| linestyle="--", | ||
| marker="o", | ||
| markerfacecolor="none", |
There was a problem hiding this comment.
🤖 from Claude (review)
Nit (not a bug): I traced this per-column "last populated panel" logic for the odd-grid case (e.g. 3 targets → 2×2 with one blank panel). For column 1 the last populated index is 1, which is the top-row panel — and that's correct, since the panel directly beneath it is blank, so it should carry the labels. The new test only exercises the even (2×2, 4-target) grid, so this trickier odd-grid branch is untested. Consider a small parametrization (e.g. 3 targets) to lock in that the bottom-of-column panel gets labels even when it lands on the top row. Non-blocking.
Generated by Claude Code
| assert plot_series.make_figure( | ||
| update_series.load_series(series), "cost_per_shard_usd", "c", out | ||
| ) | ||
| fig = captured["fig"] |
There was a problem hiding this comment.
🤖 from Claude (review)
Nit on the fixture, not this assertion: _rec_row derives timestamp as ...0{len(commit) % 10}Z, so the two commits here (c0, c1 — both length 2) get the same timestamp ...02Z. The labels are now per-target from sub["commit"] (good — c7d7080 removed the cross-target timestamp ordering), so the tie is harmless today. But if a future assertion ever depends on merge-point ordering, tied timestamps would make this fixture silently unreliable. Cheap fix: key the timestamp off the loop index i instead of len(commit). Non-blocking.
Generated by Claude Code
|
this is getting better, but still needs some tweaking:
|
|
Also, provide updated png previews for me to review as a comment please |
|
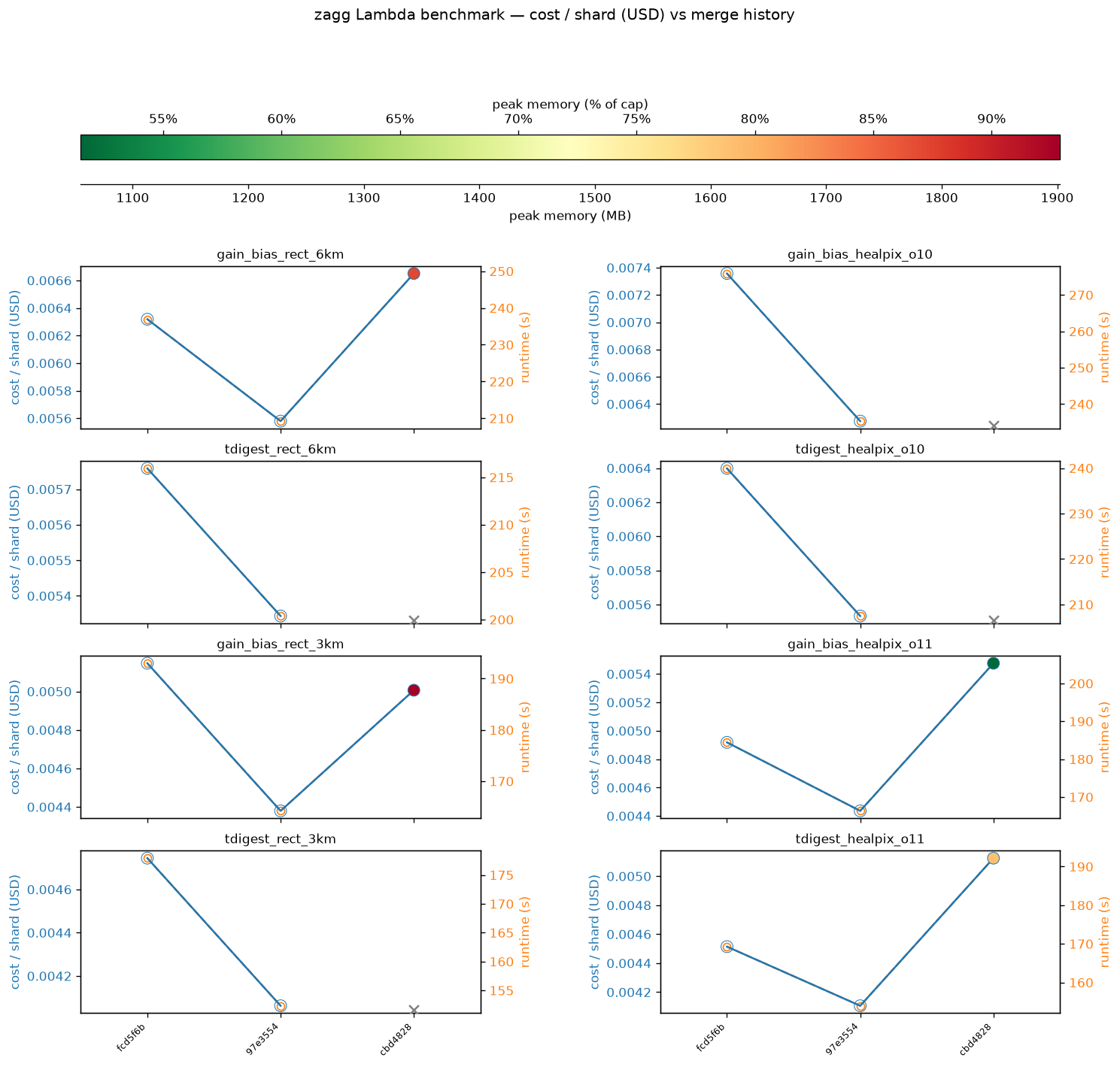
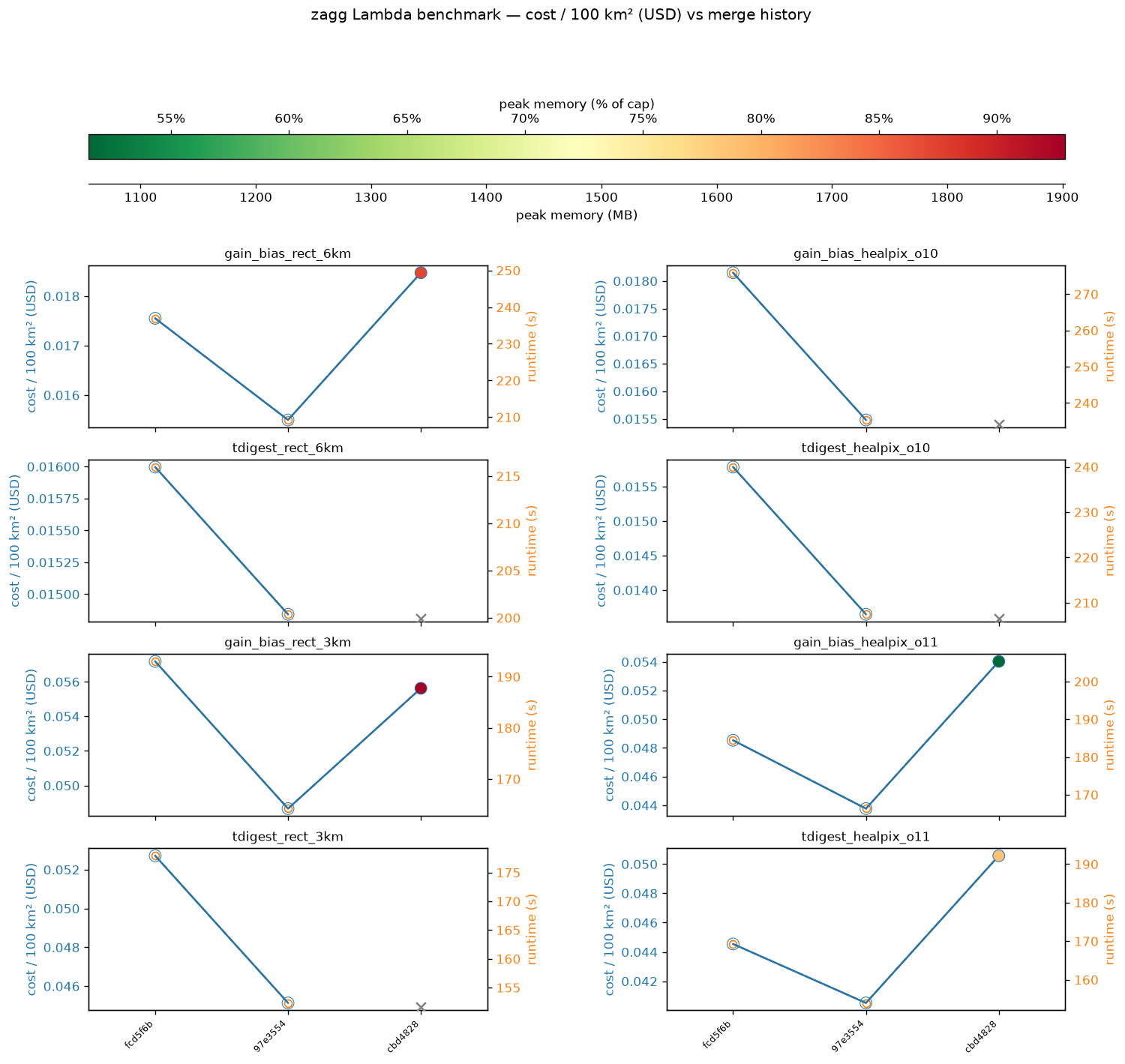
🤖 from Claude Folded the round-3 plot tweaks from the two review comments (4835363044, 4835378682) into What changed: (1) Column padding. Added inter-column (2) Dual-axis colorbar with MB. The bar still encodes peak memory as % of cap on top; a second axis below it now reads the same scale in absolute MB ( (3) Clipped to observed range. The memory normalisation no longer anchors at 0; While in there I also fixed a latent bug the new test surfaced: the global Test added: Updated previews (committed temporarily under
Generated by Claude Code |
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Round 3 (benchmark-plot tweaks), reviewing commit 7332bf9 against parent c7d7080. Verdict: functionally sound and close to mergeable — the matplotlib changes are correct — but there are a few diff-scoped follow-ups worth a fold before ready-for-review.
What's correct (verified, no action):
- Dual-axis colorbar.
secondary_xaxis(-1.0, functions=(f*cap_mb, mb/cap_mb))on alocation="top"bar is right: the bar's x data coords are fraction-of-cap, so the forward/inverse correctly align MB with %. Theset_major_formatter(lambda v, _pos: ...)signature is valid, and the secondary axis sits below the bar (no overlap with the top ticks/label). - Clipped normalisation. Spanning observed non-None min/max (don't anchor at 0),
[0,1]fallback when no memory, and the ±0.01 single-value spread all handle the cases correctly;memory_fractionsreturnsNone(filtered) rather than NaN, and the scatter still usesplotnonfinite=Truefor missing markers. Matches the "don't start at zero; span observed range" ask. - sharex removal + per-column labelling. The
last = max(i for i in range(n) if i%ncols==col)+tick_params(labelbottom=False)logic is correct with no off-by-one;default=Noneis unreachable givenncols=min(2,n). This fixes the real latent shared-x stamping bug. wspace=0.45is reasonable for the 2-wide twin-axis collision and composes fine withbbox_inches="tight".plot_series.pyis well under the ~1000-line limit.
Diff-scoped findings (inline):
- (1)
test_make_figure_shared_x_and_circle_runtime— name and docstring claim "the x-axis is shared," but this same commit removessharex=True. Rename/reword so the test's stated intent matches the manual-hide implementation it now guards. - (2)
test_make_figure_uneven_commit_sets_label_per_panel— the n=2 fixture is a single-row 1x2 grid, so the row-hiding loop (the actual fix, permake_figure's "hide the upper rows" comment) never fires and it's unclear the test would fail on pre-fix code. Bump to 4 uneven targets → 2x2 to truly exercise the stacked-row misalignment. Plus a legibility nit on thelen(commit) % 10ordering trick. - (3) The headline MB twin axis has no test asserting it's populated/correct — a one-line check against
cbar.ax.child_axeswould lock it. Non-blocking.
Out-of-scope / convention flag (no inline — binary files):
- This commit adds two committed PNGs under
docs/deployment/_review_renders/(cost_per_100km2.png,cost_per_shard.png). The_review_renderspath reads like throwaway review aids, i.e. generated artifacts — CLAUDE.md §3 says don't commit generated artifacts. If they're intended permanent doc assets that's fine, but please confirm; otherwise drop them (and add the dir to.gitignore). Raising for the author's decision rather than treating it as a required change.
None of these block the chart rendering; (1) and (2) are the substantive folds (test intent vs. implementation). With those tightened — and the artifact question resolved — this round is good to go.
Generated by Claude Code
| def test_make_figure_shared_x_and_circle_runtime(tmp_path, monkeypatch): | ||
| # The benchmark-plot polish (PR #123 fold of #125's chart): runtime markers | ||
| # are circles (not squares) so the memory-coloured cost marker shows through, | ||
| # and the x-axis is shared so only the bottom-row panels carry commit labels. |
There was a problem hiding this comment.
🤖 from Claude (review)
Name/comment is now stale relative to this same commit. This round's make_figure change removes sharex=True from plt.subplots — the "bottom row only is labelled" effect is now produced by the manual tick_params(labelbottom=False) pass, not by a shared x-axis. But this test is named ..._shared_x_... and its docstring asserts "the x-axis is shared so only the bottom-row panels carry commit labels." That's the property the code deliberately abandoned (precisely because shared-x stamped one target's labels onto all panels). Suggest renaming to something like test_make_figure_circle_runtime_and_bottom_row_labels and rewording the comment to describe the manual hide, so the test's stated intent matches the implementation it guards.
Generated by Claude Code
| def test_make_figure_uneven_commit_sets_label_per_panel(tmp_path, monkeypatch): | ||
| # Regression for the per-target x-label misalignment class (fixed in c7d7080): | ||
| # when targets share x but have *different* commit sets (one missing an early | ||
| # merge), each bottom panel must carry ITS OWN commits in order -- not another | ||
| # panel's labels. A uniform-commit fixture can't catch this; an uneven one can. | ||
| pytest.importorskip("matplotlib") | ||
| import matplotlib | ||
|
|
||
| matplotlib.use("Agg") | ||
| import matplotlib.pyplot as plt | ||
| import plot_series | ||
|
|
||
| captured = {} | ||
| monkeypatch.setattr(plt, "close", lambda fig: captured.setdefault("fig", fig)) | ||
|
|
||
| # Two targets in one column-pair. ``_rec_row`` derives the timestamp from the | ||
| # commit-name length, so name lengths set the merge order. ``early`` has 3 | ||
| # points; ``late`` skipped the first merge and has only 2. | ||
| early = [_rec_row(c, "t_early") for c in ("a", "bb", "ccc")] | ||
| late = [_rec_row(c, "t_late") for c in ("dd", "eee")] # missing the len-1 merge | ||
| series = tmp_path / "series.parquet" | ||
| update_series.save_series(update_series.records_to_frame(early + late), series) | ||
| out = tmp_path / "fig.png" | ||
| assert plot_series.make_figure( | ||
| update_series.load_series(series), "cost_per_shard_usd", "c", out | ||
| ) | ||
| fig = captured["fig"] | ||
|
|
||
| panels = {ax.get_title(): ax for ax in fig.axes if ax.get_title()} | ||
| # n=2 -> single row, so both panels are "bottom" and carry their own labels. |
There was a problem hiding this comment.
🤖 from Claude (review)
The regression target here is the per-target x-label misalignment across the grid, and make_figure's own comment frames it as "hide the upper rows' commit labels by hand." But this fixture has only 2 targets → nrows=1, a single-row 1x2 grid, and the test even acknowledges it ("n=2 -> single row, so both panels are 'bottom'"). In a single row there are no stacked rows, so the labelbottom=False hiding loop never fires for any panel — every panel is its column's last. That means this test exercises the differing-commit-sets path but does not exercise the row-hiding logic that is the actual fix, and it's not obvious it would fail on the pre-fix shared-x code (whose cross-panel stamping is a multi-row phenomenon). Suggest bumping to 4 uneven targets (e.g. t_early/t_late/t_a/t_b with differing commit sets) so it lands a 2x2 grid: then assert the top-row panels are blank and the bottom-row panels each carry their own commits in order. That makes it a true regression for the stacked-row misalignment and removes the reliance on the single-row coincidence.
Secondary nit: ordering via len(commit) % 10 (name length → timestamp) is clever but obscure — a reader has to reverse-engineer why "a"/"bb"/"ccc" sort that way. Passing explicit timestamps (or an explicit ts= kwarg to _rec_row) would make the merge order legible at the call site.
Generated by Claude Code
| cbar.ax.xaxis.set_major_formatter(lambda v, _pos: f"{v:.0%}") | ||
| # Twin axis (below the bar) reading the same scale in absolute MB: the bar's | ||
| # data coords are fraction-of-cap, so MB = fraction * cap_mb (and back). | ||
| mb_ax = cbar.ax.secondary_xaxis(-1.0, functions=(lambda f: f * cap_mb, lambda mb: mb / cap_mb)) |
There was a problem hiding this comment.
🤖 from Claude (review)
The dual-axis math is correct — the colorbar's x data coords are fraction-of-cap, so the forward/inverse (f*cap_mb, mb/cap_mb) place MB ticks aligned with the % scale, and the (v, _pos) formatter signature is right. No change required there.
One robustness note, not a blocker: there is no test asserting the MB axis is actually populated/correct (e.g. that mb_ax exists and its forward maps vmax -> vmax*cap_mb). Given this is the headline feature of the round and matplotlib's secondary_xaxis tick placement is easy to silently break (empty axis if the parent has no ticks, wrong side, etc.), a one-line assertion in the existing colorbar test — grab the secondary axis from cbar.ax.child_axes and check f(vmax) == pytest.approx(vmax * cap_mb) — would lock the behavior. Worth considering since the visual artifacts (docs/deployment/_review_renders/*.png) are the only current "proof" it renders.
Generated by Claude Code
|
closer... we need the circles plotted on top of the line; right now the circle symbol z-order puts them behind the open circle and dotted line glyph (also, bump them up one radius size please). |
|
🤖 from Claude Round 3 done (column padding, colorbar MB dual-axis, clipped memory range, plus an uneven-commit-set regression test); fresh-context self-review folded in Generated by Claude Code |
|
🤖 from Claude Folded the round-4 tweaks from your comment (4835498668) into (1) Cost circles now plot on top of the runtime line. The runtime line lives on a (2) Marker bumped up one size — Test added: Updated previews (committed temporarily under
Generated by Claude Code |
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Round-4 review of db317b0 (parent 1aa343c), scoped to the cost-circle-over-runtime-line layering fix + marker bump. Verdict: mergeable as-is. Both of @espg's asks land, the matplotlib idiom is the correct/standard one, and the new test is a real guard (fails on pre-fix code). Only non-blocking nits inline.
What's correct (verified):
- Layering fix.
ax.set_zorder(rt.get_zorder() + 1)+ax.patch.set_visible(False)is exactly the documented fix for the twinx "twin draws on top" gotcha — across axes, only axes-level zorder reorders; per-artist zorder can't. Host→1, twin→0, host patch hidden so it doesn't occlude the runtime line beneath. No white-background loss (figure patch still backs the panel), no gridline double-render (none enabled), no colorbar /bbox_inches="tight"interaction. The (2) cost circles now sit over the runtime open-circle/dashed glyph. - Marker bump.
s=60 → s=90is a sensible one-step bump; withbbox_inches="tight"there's no edge-clipping concern. - Test.
test_make_figure_cost_scatter_drawn_above_runtime_lineasserts host-zorder > twin-zorder and host patch hidden — both fail on the default-zorder pre-fix code, and the bbox-equality twin match is robust (twins share host position; colorbar bounds differ). plot_series.py~210 lines,tests/test_benchmark.py~640 — both well under the ~1000-line limit. ruff-clean style, matches surrounding code.
Non-blocking nits (inline):
- (1) The artist-level
zorder=1on the runtimert.plot(...)is inert for the cost-vs-runtime layering — that's decided by the axes-level zorder set below. Harmless but misleading-as-written; lean toward dropping it for terseness, or comment it. - (2) The test asserts the mechanism (zorder + hidden patch) rather than rendered pixels — correct call (pixels would be brittle); optionally also assert the scatter's
s == 90to lock the marker-bump ask too.
Nothing here blocks ready-for-review.
Generated by Claude Code
| ) | ||
| rt.set_ylabel("runtime (s)", color="C1") | ||
| rt.tick_params(axis="y", labelcolor="C1") | ||
| ax.set_zorder(rt.get_zorder() + 1) |
There was a problem hiding this comment.
🤖 from Claude (review)
Layering fix is correct. ax.set_zorder(rt.get_zorder() + 1) + ax.patch.set_visible(False) is exactly the documented matplotlib idiom for the twinx "twin paints on top" gotcha — the twin is added to the figure after the host, so it draws above regardless of per-artist zorder, and the only lever that reorders across axes is the axes-level zorder. Raising the host above the twin then drops the host's opaque patch so the (now-on-top) host axes doesn't occlude the runtime line beneath it. Default axes zorder is 0, so this sets host=1, twin=0 — works.
No white-background regression: only the axes patch is hidden, not the figure patch, so savefig's default white figure facecolor still backs the panel. No gridlines are enabled (ax.grid() is never called), so nothing double-renders, and there's no interaction with the colorbar (separate axes) or bbox_inches="tight". Verified the (2) cost circles now sit over the runtime glyph.
Generated by Claude Code
| marker="o", | ||
| markerfacecolor="none", | ||
| color="C1", | ||
| zorder=1, |
There was a problem hiding this comment.
🤖 from Claude (review)
Nit (non-blocking): this artist-level zorder=1 on the runtime line does nothing for the cost-vs-runtime layering. Per-artist zorder only orders artists within the same axes; the runtime line lives on rt while the cost scatter lives on ax, so what decides which is on top is the axes-level zorder you set two lines below — not this. It's harmless (it agrees with the cost line's zorder=1 on the host, and doesn't fight the axes-level fix), but as written it reads like it's contributing to the fix when it isn't.
Two options, either fine: (1) drop it (the cost scatter's zorder=2 over the cost line's zorder=1 on the host axis is what the run actually relies on, and that's unaffected); or (2) keep it but add a one-line comment that it only orders the runtime line vs. anything else on the twin, so a future reader doesn't mistake it for the cross-axes lever. Leaning toward (1) for terseness (CLAUDE.md §4).
Generated by Claude Code
|
|
||
| def test_make_figure_colorbar_has_mb_twin_axis(tmp_path, monkeypatch): | ||
| # The colorbar carries a second axis reading the same scale in absolute MB | ||
| # (issue #120 polish): MB = fraction-of-cap * cap_mb. cap_mb = 2 GB here, so a |
There was a problem hiding this comment.
🤖 from Claude (review)
The new test is meaningful and would fail on pre-fix code, so it genuinely guards the fix:
panel.get_zorder() > twin.get_zorder(): pre-fix both axes default to zorder 0, so0 > 0is False → fails. Post-fix host=1, twin=0 → passes. Real assertion.panel.patch.get_visible() is False: axes patch defaults to visible → pre-fix this is True → fails. Real assertion.- Matching the twin by
ax.bbox.bounds == panel.bbox.boundsis robust here:twinx()shares the host's position so their bounds are equal, while the colorbar axes has different bounds; with a single panel the comprehension yields exactly one match (the(twin,)unpack would loudly fail if not).
One framing nit (non-blocking): panel.get_zorder() > twin.get_zorder() plus patch.get_visible() is False is asserting the mechanism (the documented idiom), not directly the rendered outcome (circles visually above the line). That's acceptable and the right call — a pixel assertion on the rendered PNG would be brittle (and over-engineered), and these two properties are precisely the two-part idiom that produces the outcome. If you want one extra cheap belt-and-suspenders signal without touching pixels, you could also assert the cost PathCollection's s array is 90 here so the "bump the marker one size" ask (2) is locked too — but that's optional, fold at your discretion.
Generated by Claude Code
|
🤖 from Claude Round 4 done: cost circles now render on top of the runtime line (host-axes z-order raised above the Generated by Claude Code |
|
A few more small changes:
|
|
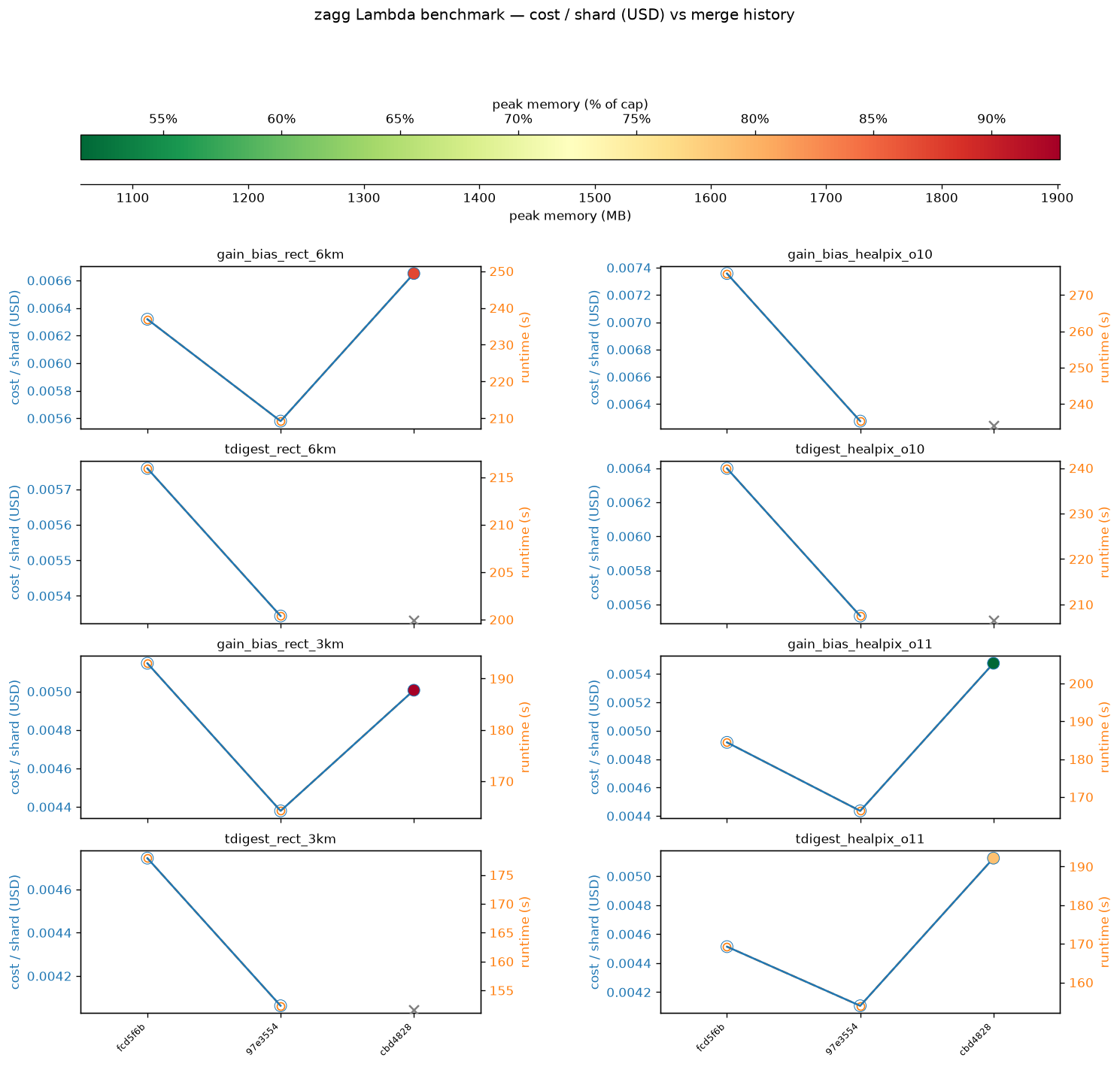
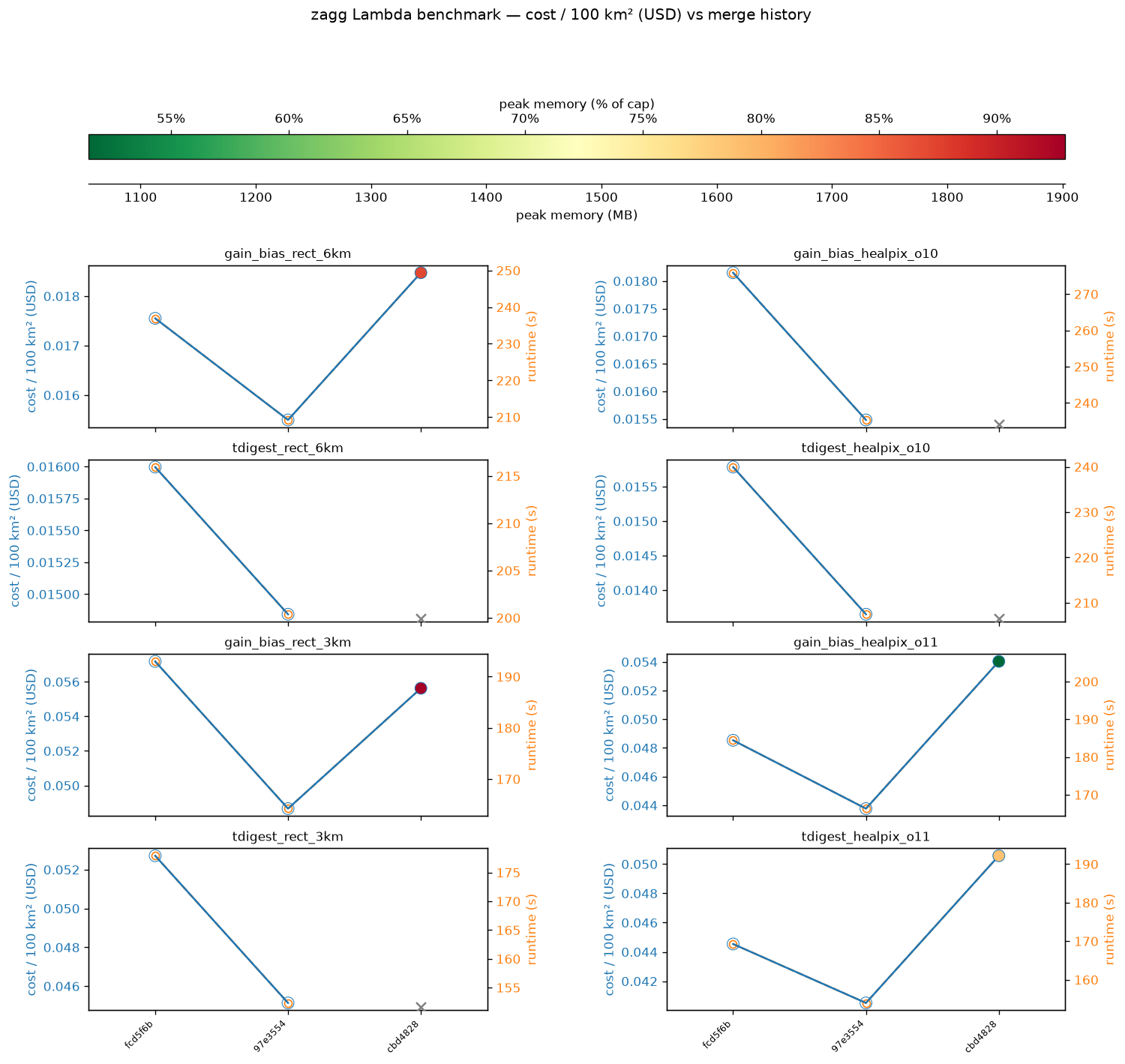
🤖 from Claude Folded the round-5 changes from your comment (4836608338) into (1) Meaningful row/column layout. New (2) Documented the conventions in (3) Dropped failed-run zeros. A zero cost/runtime is a crashed shard, not a measurement: the connecting line now breaks at that merge (NaN — it never dips to 0), for both the cost line+scatter and the runtime line. To keep the x-axis/commit alignment, a failed run is flagged with a non-line-connected grey Tests: extended the layout/label tests to the new placement and added Updated previews (committed temporarily under
One thing I had to decide (correct me if you'd prefer otherwise): for the vertical ordering of the four rows I made shard size the primary sort and aggregator secondary, so the grid is strictly largest→smallest top-to-bottom with the two aggregators of a given size class adjacent (gain_bias above tdigest). The alternative reading — group by aggregator first, size second — would interleave differently; happy to flip if you intended agg-major. Generated by Claude Code |
{kind=link}
{kind=link}
espg
left a comment
There was a problem hiding this comment.
🤖 from Claude (review)
Round-5 review (commit 97dbb87, parent f1ec81b), scoped to the meaningful-layout / drop-zeros work in plot_series.py + tests/data/benchmark/README.md requested in comment 4836608338. Verdict: all three asks land; mergeable as-is, with a couple of judgment-call polish items worth a quick fold.
What's correct (verified against the full file on the branch):
- (1) Layout.
_panel_layoutis data-driven, not hardcoded: col =0 if grid.startswith("rect") else 1(rect left / healpix right), shard-size rank computed per family so the two families align row-for-row, rows ordered largest-shard-first viasorted({(rank, agg)}). The row order is size-major, agg-minor (the ambiguity the author flagged) — a defensible reading of "largest shards at top, descending," and code/test/README agree.test_panel_layout_...pins the exact 4x2 grid and would fail on a column swap or row mis-order. - (2) README. New "Plot layout" section documents columns=grid-family, rows=agg+resolution-rank aligned + largest-first with the agg tie-break, and zeros-are-failures — matches the implemented rule exactly, tie-break included.
- (3) Zeros. Both cost and runtime lines NaN out zeros (
v != 0), so neither line dips to/connects 0; cost failures get a non-connected greyx.test_make_figure_drops_failed_run_zerosproves the line is NaN at the zero, no connected 0 survives, and anxmarker exists — fails on pre-fix code.
Diff-scoped judgment calls (fold at discretion, none block):
- Cost fail
xat data-y=0re-expands the axis floor back to 0 — the line no longer dips, but the marker pinsymin≈0, so the panel still reads against a 0 baseline. Consider drawing it inax.get_xaxis_transform()axes-fraction y, or document the 0-anchor. - No
xfailure marker on the runtime axis — partial against "apply to both," though the costxalready flags that merge for both series. Either document that or mirror the marker. - Latent collision: two same-aggregator targets in one column with identical
shard_area_km2but different resolutions map to the same(rank, agg)cell and one is silently overwritten. Can't fire on today's data; rank by(area, grid_size)to harden the data-driven claim.
Nits: fail-marker test matches by len(get_offsets())==1 (fragile only if a panel ever has exactly 1 commit); NaN cost is a silent line-break with no x (intended distinction, just confirming); no test for the all-rect ncols=1 path; README could note the x is cost-axis-only.
Inline details on each. I only review — folding is the author's call.
Generated by Claude Code
| if d["col"] == col: | ||
| d["rank"] = rank[d["area"]] | ||
| # One row per (size-rank, aggregator); largest shard at the top. | ||
| row_keys = sorted({(d["rank"], d["agg"]) for d in rows}) |
There was a problem hiding this comment.
🤖 from Claude (review)
Row ordering is size-major, aggregator-minor: sorted({(rank, agg)}) sorts on rank first (0 = largest, ascending = descending size, good) then breaks ties alphabetically on the aggregator. So with two sizes x two aggs the rows are gain_bias@large, tdigest@large, gain_bias@small, tdigest@small — exactly what the test pins.
This is a defensible reading of @espg's "largest shards at top, descending" — it keeps the primary sort on size and only uses agg as a tie-break, which is what "rows sorted largest-shard-first" most naturally means. The alternative (agg-major: all gain_bias rows, then all tdigest) would not be largest-first across the whole grid, so I think the chosen reading is correct. Just confirming this matches the author's flagged ambiguity and the README ("same-size rows break ties on the aggregator name") — code, test, and README are mutually consistent. No change needed; flagging so @espg can veto if agg-major was actually wanted. [diff-scoped, judgment call]
Generated by Claude Code
| areas = sorted({d["area"] for d in rows if d["col"] == col}, reverse=True) | ||
| rank = {a: i for i, a in enumerate(areas)} | ||
| for d in rows: | ||
| if d["col"] == col: | ||
| d["rank"] = rank[d["area"]] | ||
| # One row per (size-rank, aggregator); largest shard at the top. | ||
| row_keys = sorted({(d["rank"], d["agg"]) for d in rows}) | ||
| row_of = {k: i for i, k in enumerate(row_keys)} | ||
| nrows = len(row_keys) |
There was a problem hiding this comment.
🤖 from Claude (review)
Edge case: two targets in the same column+aggregator with identical shard_area_km2 but different resolutions collide into one cell. rank is keyed on the distinct area value, so two different-resolution rect targets that happen to share the exact same float area get the same rank; with the same aggregator they map to the same (rank, agg) row key, and grid[row][col] = target silently overwrites — one target vanishes from the figure with no error.
In today's data the four rect/healpix sizes are distinct, so this can't fire now, and the author flagged area-ties to @espg. But the layout claims to be data-driven for new targets, and the natural collision key is resolution, not area. Cheap hardening: rank by (area, grid_size) (or fall back to grid label) so equal-area-different-resolution targets still get distinct ranks. At minimum worth a one-line comment that equal areas within a family must not occur. [diff-scoped, low severity — latent]
Generated by Claude Code
| plotnonfinite=True, | ||
| ) | ||
| if fail: # failed-run markers, not joined to the line | ||
| ax.scatter(fail, [0] * len(fail), marker="x", color="0.5", s=60, zorder=3) |
There was a problem hiding this comment.
🤖 from Claude (review)
The fail 'x' at y=0 re-expands the cost axis back down to 0, partially undermining the "line never dips to 0" goal. Once zeros are NaN'd out of line, the left y-axis would autoscale tightly to the real cost range (e.g. 0.005–0.006). But this scatter(fail, [0]*n, ...) adds a real data point at y=0, so matplotlib's autoscale pulls ylim back down to ~0 — the real points then cluster at the very top and the 'x' sits alone at the bottom, against a baseline that now reaches 0. The line doesn't dip to 0 (good, the ask is met literally), but visually the axis floor is still 0, which is the impression the ask was trying to avoid.
Two options if you want the cost panel to read cleanly: (a) draw the 'x' in axes-fraction coords pinned near the bottom (transform=ax.get_xaxis_transform(), y≈0.02) so it flags the failed x without forcing data-space ymin=0; or (b) accept it as-is and note in the README that failures anchor the axis at 0. Either is fine — flagging because "break the line at zeros" was specifically to stop the 0-dip, and pinning the marker at data-y=0 reintroduces a 0 floor. [diff-scoped, judgment call]
Generated by Claude Code
| # ``ax``'s opaque patch -- otherwise the runtime glyph sits on top of | ||
| # the cost circles. Zero runtimes break the line the same way. | ||
| runtime = sub["runtime_s"].to_numpy(dtype=float) | ||
| rt_line = [v if v != 0 else float("nan") for v in runtime] |
There was a problem hiding this comment.
🤖 from Claude (review)
Runtime zeros break the line (good) but there is no failure 'x' marker on the runtime/right axis — only the cost axis gets one. @espg's ask was "apply to both cost and runtime series." This is arguably acceptable: a failed shard zeros both cost and runtime at the same x, so the cost 'x' already flags that merge as a failure and a second 'x' would be redundant clutter. But it's a literal partial-coverage against "both series," so calling it out as a judgment call: either (a) leave as-is and document in the README that the single cost 'x' flags the failure for both series, or (b) add a matching runtime 'x' on the twin axis for symmetry. I lean (a). [diff-scoped, judgment call]
Generated by Claude Code
| # non-connected 'X' so the x-axis/commit alignment is kept and the | ||
| # failure reads as a failure, not a real 0. | ||
| cost = sub[cost_col].to_numpy(dtype=float) | ||
| line = [v if v != 0 else float("nan") for v in cost] |
There was a problem hiding this comment.
🤖 from Claude (review)
v != 0 is the right "failed run" test for this data (costs/runtimes are pinned-shard measurements, never legitimately exactly 0.0; a near-zero real value like 1e-6 is non-zero and correctly kept). Two small notes, neither blocking:
- NaN cost (missing metric, not a failed run) passes
v != 0(NaN != 0 → True), so it stays inlineas a NaN break without a fail 'x' — i.e. silently a gap. That's a reasonable distinction (missing-metric ≠ crashed-run), just confirming it's intended rather than overlooked. - A failed run that emitted a tiny non-zero cost (partial write before crash) wouldn't be caught by
== 0. Out of scope for this PR — the series records 0 for failures by convention — but worth knowing the marker keys strictly on exact 0. [diff-scoped, nit]
Generated by Claude Code
| assert 0.0 not in [y for y in ys if not np.isnan(y)] | ||
| # A distinct, non-line 'x' marker flags the failed run. | ||
| fails = [ | ||
| c for c in panel.collections if isinstance(c, PathCollection) and len(c.get_offsets()) == 1 |
There was a problem hiding this comment.
🤖 from Claude (review)
Matching the fail marker by len(c.get_offsets()) == 1 is robust for this fixture (3 commits → cost scatter has 3 offsets, fail scatter has 1, runtime is a Line2D not a PathCollection) and the test does prove the three things that matter: the cost line is NaN at the zero index, no connected 0 survives, and a single-offset 'x' collection exists. It would fail on pre-fix code (which plotted a connected 0). Good test.
One fragility note: the == 1 heuristic would mis-identify if a panel ever had exactly one commit total — then the cost scatter also has 1 offset and the assertion could match the wrong collection (or a non-failure panel could spuriously "have a fail marker"). Cheap tightening: assert on the marker itself, e.g. select the collection whose paths are the 'x' marker, or assert its single offset's x equals the failed index (1) and its y equals 0. Not blocking — the fixture guarantees ≥2 commits. [diff-scoped, nit]
Generated by Claude Code
| # --- panel layout + failed-run handling (issue #121 review) --------------- | ||
|
|
||
|
|
||
| def test_panel_layout_rect_left_healpix_right_largest_on_top(): |
There was a problem hiding this comment.
🤖 from Claude (review)
test_panel_layout_rect_left_healpix_right_largest_on_top is a genuine, non-tautological pin of the rule: it asserts the exact 4x2 grid with rect in col 0 / healpix in col 1, largest shards on top, and agg as the row tie-break. It would fail if columns were swapped, if rows were mis-ordered, or if the size-rank alignment broke — i.e. it locks all of @espg's layout asks. Good.
Two gaps the suite doesn't cover (optional, not blocking): (a) the all-rect → ncols=1 path (does make_figure render a 1-col figure without the right-column logic tripping?), and (b) a column with only one family present. Both are reachable configurations the layout claims to handle data-drivenly; a small assertion on _panel_layout for an all-rect input would lock the ncols branch. [diff-scoped, nit]
Generated by Claude Code
|
|
||
| When adding or rearranging targets, keep these conventions — the layout is derived | ||
| from `grid_type` / `aggregator` / `shard_area_km2`, so getting that metadata right | ||
| in `targets.json` is what places the panel. |
There was a problem hiding this comment.
🤖 from Claude (review)
README ↔ code match is accurate on all three asks: columns = grid family (rect left / healpix right), rows = aggregator + shard-size-rank aligned across families with "same-size rows break ties on the aggregator name" (matches sorted({(rank, agg)})), largest-first descending, and the zeros-are-failures rule (line breaks, non-connected x marker). Good — the documented convention is exactly the implemented rule, including the tie-break.
One doc accuracy nit tied to the runtime-marker finding on plot_series.py: the README says the failure "is shown as a non-line-connected x marker" without noting it's drawn only on the cost axis, not runtime. If you keep the cost-only marker, add a half-sentence that the single cost x flags the failure for both series (so the doc isn't read as promising an x on the runtime axis too). [diff-scoped, nit]
Generated by Claude Code
|
🤖 from Claude Round 5 done (meaningful data-driven panel layout: rect left / healpix right, rows agg+resolution-aligned largest-first; documented the conventions in Generated by Claude Code |
Closes #121
What
The Lambda benchmark matrix is single-AOI by construction:
tests/data/benchmark/targets.jsonhas one top-levelaoi/temporal/cmr, and the drift test (tests/test_benchmark_shardmap.py) rebuilds every shard map over that single AOI. This makes the top-levelaoi/temporal/cmrdefaults and lets a shard-map entry override any of them, falling back to the default when a key is absent — enabling runtime-vs-latitude studies and a deliberate 88S density stress target.Runner (
.github/scripts/run_benchmark.py) and CI (.github/workflows/lambda-benchmark.yml) are unchanged — the runner is AOI-agnostic (it dispatches the pinnedshard_key), so only the drift test consumes the AOI. The change is confined to thetests/fixture/test/loader layer.Approach
resolve_aoi_temporal_cmr(sm_meta)helper:sm_meta.get("aoi", MANIFEST["aoi"])and likewise fortemporal/cmr. An entry with no override resolves by identity to the top-level default, so existing NEON shard maps rebuild exactly as today.antarctic_88s.geojson(a box at the ±88° ICESat-2 turning latitude) ships ready to use.--polygon antarctic_88s.geojsonbuild + the "high-latitude → OOM/timeout is the expected result" caveat tied to Order-10 single-shard processing OOMs at 2 GB (gain_bias) — 2 GB is marginal for order-10 #117 / Don't retry deterministic Lambda failures (OOM); expose max_retries and run the benchmark with max_retries=1 #119).Phases
antarctic_88s.geojsonAOI fixture + fixture-validity test; README Layout entry + end-to-end different-AOI recipe.mainto pick up Capture per-shard max memory and color benchmark markers by % of cap #125's memory color-coding, then fixed the chart in.github/scripts/plot_series.py: (1) the memory-coloured cost markers were hidden behind the runtime markers — runtime markers are now hollow circles (was filled squares) so the colour shows through, and the cost scatter is enlarged so the green→red memory signal reads clearly; (2) shared x-axis (sharex=True) so only the bottom-row panels carry the commit labels; (3) the colorbar is now horizontal, placed just below the figure title instead of a cramped vertical bar on the right. Re-rendered from the committedseries.parquet(no benchmark re-run); figure posted to the thread for review.wspacepadding so a panel's right-axis labels no longer overlap the next column's left-axis labels; (2) added a dual axis on the colorbar showing absolute MB alongside the existing % of cap (secondary_xaxis,MB = fraction * cap_mb); (3) clipped the memory normalisation to the observed min..max (no longer anchored at 0) so the green→red gradient spans only real data. While here, dropped the globalsharex=True: it stamps one target's commit labels onto every panel when commit sets differ, so each panel now keeps its own x-axis and the upper rows' labels are hidden vialabelbottom=False. Re-rendered from the committedseries.parquet(no re-run, no network) and posted updated previews to the thread.twinx()runtime axis and hid the host patch so the memory-coloured cost circles render on top of the runtime open-circle/dashed glyph; bumped the markers=60->s=90._panel_layout): left column = rect grids, right column = HEALPix; each row pairs the families at matching aggregator + shard-size rank; rows ordered largest-shard-first. (2) Documented the layout + zeros-are-failures conventions intests/data/benchmark/README.md. (3) Dropped failed-run zeros — a zero cost/runtime breaks the line (NaN, no dip to 0) and is flagged with a non-connectedxmarker on both the cost and runtime series.How tested
uv run ruff check --select=E,F,W,I --ignore=E501 tests/...— clean.uv run ruff format --checkon touched files — clean.uv run pytest tests/test_benchmark.py -q— 39 passed. Phase 3 addedtest_make_figure_circle_runtime_and_bottom_row_labels(round runtime markers + only the bottom-row panels carry x tick labels); round 3 addedtest_make_figure_uneven_commit_sets_label_per_panel, which uses differing commit sets across targets (one target missing an early merge) and asserts each bottom panel's tick labels match THAT panel's own commits in order — the misalignment class a uniform-commit fixture can't catch. Rounds 4-5 addedtest_make_figure_cost_scatter_drawn_above_runtime_line,test_panel_layout_rect_left_healpix_right_largest_on_top, andtest_make_figure_drops_failed_run_zeros. The existing Capture per-shard max memory and color benchmark markers by % of cap #125 colour-array / colorbar tests still pass. New tests from earlier phases:test_override_resolution_falls_back_to_defaults— absent override returns the top-level objects by identity (the byte-identical guarantee for existing entries).test_override_resolution_uses_overrides/..._partial_override— overrides win; omitted keys fall back.test_antarctic_88s_aoi_fixture_loads_near_turning_latitude— the AOI loads and sits in the high-density polar band.test_targets_manifest_consistentstill passes — no existing target entry changed, so the committed NEON shard maps stay byte-identical.The drift test itself is network +
ZAGG_BENCHMARK_DRIFT=1gated (and needs spherely for rect maps), so it does not run in the unit suite; the resolution logic it now uses is covered by the non-network unit tests above.Questions for review
sm_healpix_o11_88s.jsonshard map requires a CMR fetch (cmr.earthdata.nasa.gov), which is outside this routine's outbound allowlist (proxy returns 403), so I cannot build/pin an honest map here. This PR ships the mechanism + the AOI geojson + the documented recipe, but does not commit a fabricated shard map or a live target entry referencing it (that would either bake fake CMR granules into the fixture or breaktest_targets_manifest_consistent). Two options: (1) merge the mechanism now and add the real 88S target as a follow-on data PR once a network-capable run builds + pins the map; (2) you build/pinsm_healpix_o11_88s.jsonand push it to this branch. I recommend (1).maininto this branch to bring in Capture per-shard max memory and color benchmark markers by % of cap #125's color-coding foundation (the chart fixes build on top of it). The merge was conflict-free and the PR base/state staysclean.Generated by Claude Code