Burla is the simplest way to scale python, it's has one function: remote_parallel_map
It's open-source, works with GPU's, custom docker containers, and up to 10,000 CPU's at once.
Scale machine learning systems, or other research efforts without weeks of onboarding or setup.
Burla's open-source web platform makes it simple to monitor long running pipelines or training runs.
Burla only has one function:
from burla import remote_parallel_map
my_inputs = [1, 2, 3]
def my_function(my_input):
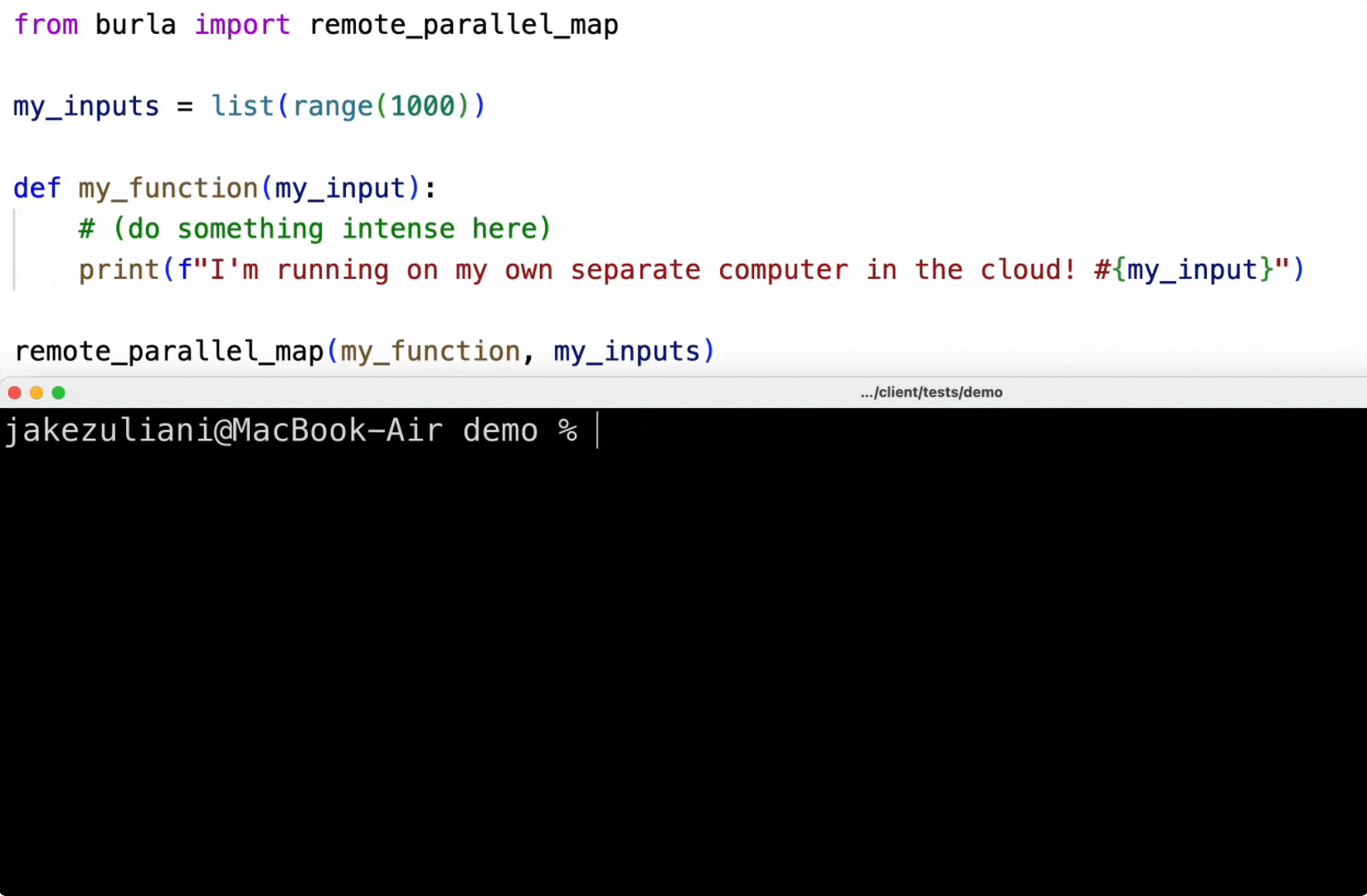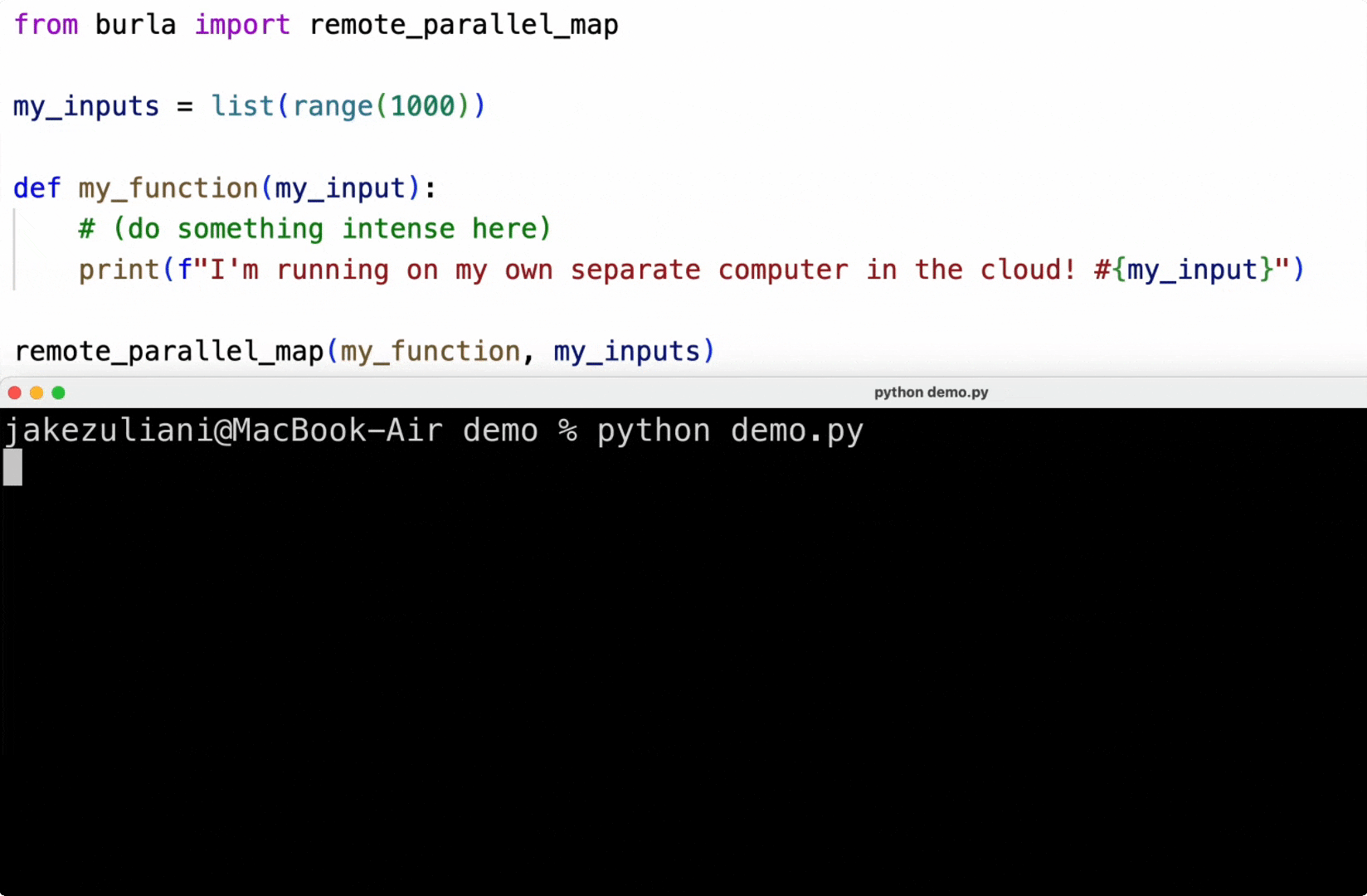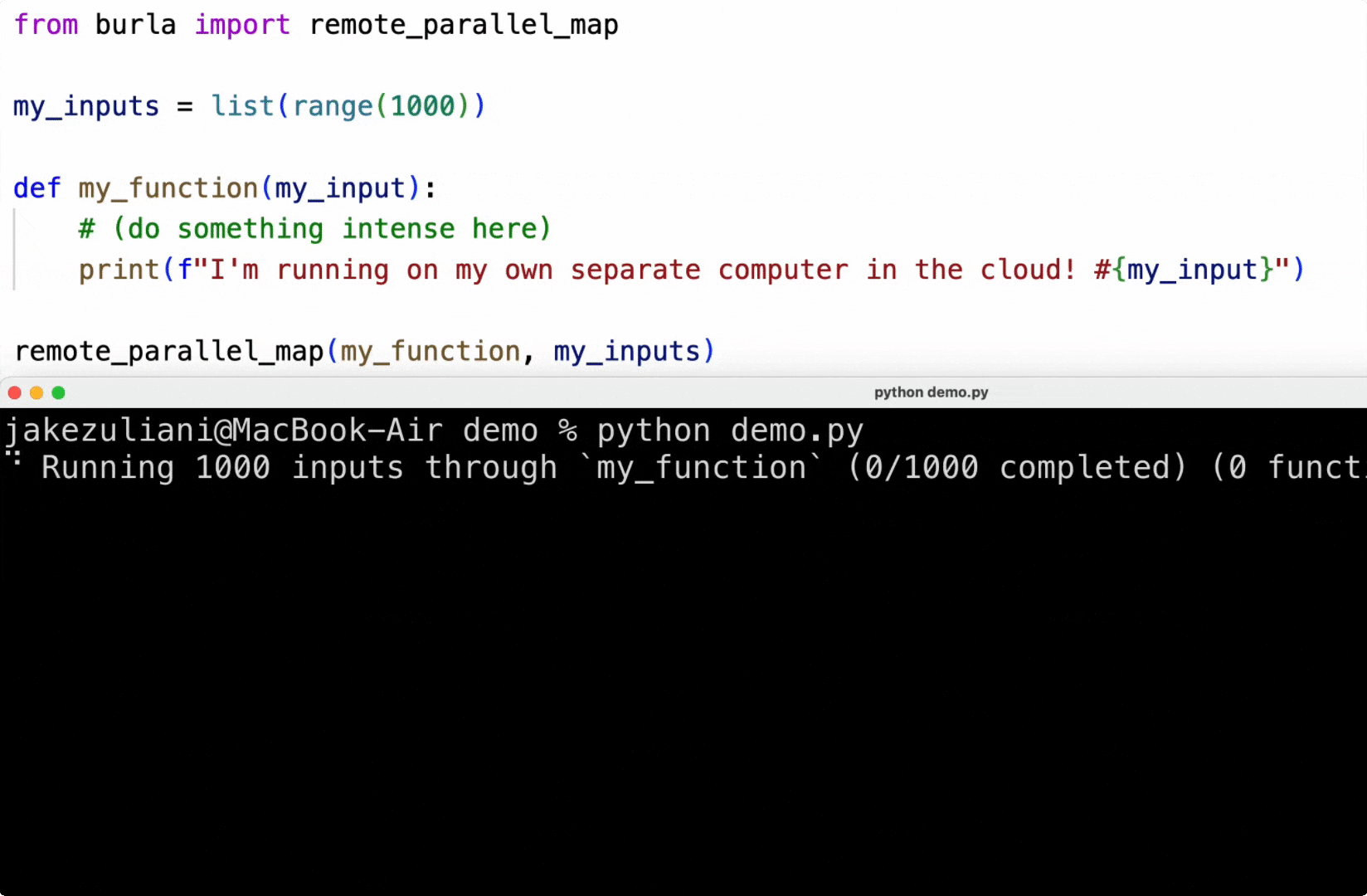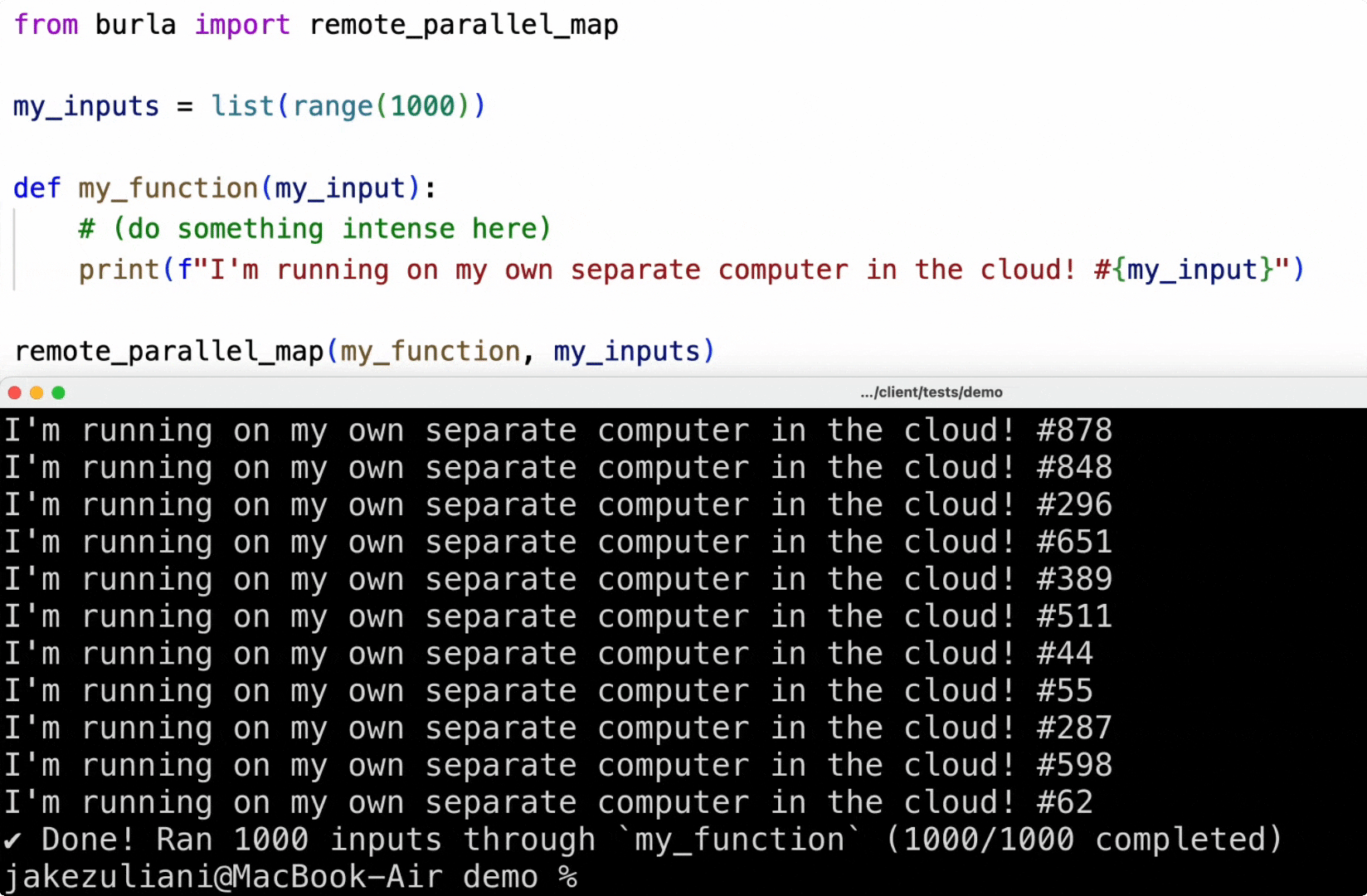
print("I'm running on my own separate computer in the cloud!")
return my_input
return_values = remote_parallel_map(my_function, my_inputs)With Burla, running code in the cloud feels the same as coding locally:
- Anything you print appears in your local terminal.
- Exceptions thrown in your code are thrown on your local machine.
- Responses are pretty quick, you can call a million simple functions in a couple seconds!
Burla clusters automatically (and very quickly) install any missing python packages into all containers in the cluster.
Easily run code in any linux-based Docker container. Public or private, just paste an image URI in the settings, then hit start!
Need to get big data into/out of the cluster? Burla automatically mounts a cloud storage bucket to your working directory.
The func_cpu and func_ram args make it possible to assign more hardware to some functions, and less to others, unlocking new ways to simplify pipelines and architecture.
Nest remote_parallel_map calls to fan code in/out over thousands of machines.
Example: Process every record of many files in parallel, then combine results on one big machine.
from burla import remote_parallel_map
def process_record(record):
# Pretend this does some math per-record!
return result
def process_file(filepath):
# load records from disk (network storage)
results = remote_parallel_map(process_record, records)
# save results back to disk (network storage)
def combine_results(result_filepaths):
# load results from disk (network storage), then combine!
result_filepaths = remote_parallel_map(process_file, filepaths)
remote_parallel_map(combine_results, [result_filepaths], func_ram=256)https://www.youtube.com/watch?v=9d22y_kWjyE
Sign up here and we'll send you a free managed instance! Compute is on us.
If you decide you like it, you can deploy self-hosted Burla (currently Google Cloud only) with just two commands:
pip install burlaburla install
See the Getting Started guide for more info.
Questions?
Schedule a call, or email jake@burla.dev. We're always happy to talk.