{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
With just a tiny dataset of 303 entries, can we craft a model that accurately predicts patients at high risk of heart attacks? Such a model could be a game-changer, helping doctors intervene earlier and potentially save lives!
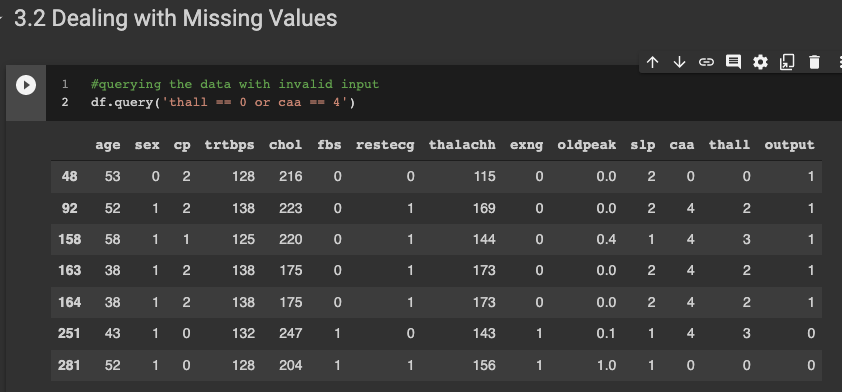
It appears that there were errors during data collection, resulting in invalid inputs in 7 of the records. Given the dataset's limited size, it's advisable to sidestep imputation to prevent potential distortions in the original data distribution.
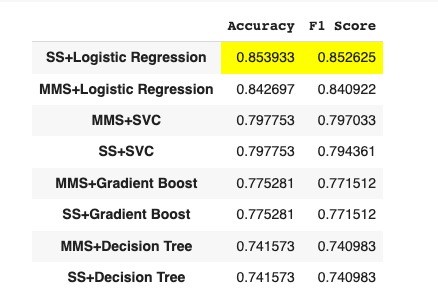
Upon evaluation, the combination of Standard Scaler and Logistic Regression yielded the highest accuracy score of 0.85.
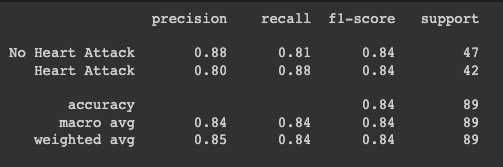
Considering the dataset's constraints, the results are commendable! We're now set to transition into the app development phase.

Clinicians require robust evidence before integrating new tools into their practice. A critical concern raised was the potential ramifications of the app incorrectly classifying high-risk patients as low-risk. Such misclassifications could lead to a false sense of security, delaying essential treatments.
A separate dataset, consisting of 10 entries, was provided by clinicians for model validation.
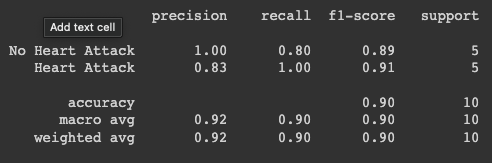
The results were promising! The model's 100% sensitivity in detecting heart attack patients reassured clinicians of its reliability, particularly in minimizing False Negative outcomes.
- Original Dataset: UCI Heart Disease Dataset
- Kaggle Dataset: Kaggle Heart Attack Analysis & Prediction Dataset