[ROCm] Add HIP/ROCm backend support for AMD GPUs#327
Conversation
This adds HIP/ROCm support to brian2cuda, enabling GPU-accelerated neural network
simulations on AMD GPUs. A CUDA-to-HIP compatibility header maps CUDA symbols to
HIP equivalents at compile time, while the device detection and makefile
generation handle HIP-specific build requirements.
Key changes:
1. brianlib/cuda_to_hip.h: compatibility header mapping CUDA symbols to HIP.
2. brianlib/spikequeue.h: wave-serialized spin-lock for AMD GPUs to avoid
deadlock on wave64 architectures (CDNA GPUs lack Independent Thread
Scheduling, so the standard atomicCAS spin-lock can deadlock when multiple
lanes contend within the same wavefront).
3. device.py: HIP backend detection and HIP makefile generation.
4. templates/makefile_hip: HIP-specific makefile with -fgpu-rdc for cross-TU
device symbol linking.
The HIP backend is auto-detected when ROCm is present and CUDA is absent, or can
be forced via USE_HIP=1. The README documents the ROCm/HIP build.
On Windows, five further fixes are needed: the hipcc.exe suffix; reading the GPU
arch from preferences before falling back to rocminfo (absent on Windows);
bypassing distutils' get_compiler_and_args (which returns None on Windows);
passing --rocm-device-lib-path / -I to hipcc so clang finds the ROCm device
bitcode libraries and headers; and, at run time, an absolute main.exe path,
copying the runtime DLLs beside the executable, and setting ROCM_KPACK_PATH so
rocrand finds its kernel packages.
This work was authored with the assistance of Claude, an AI assistant by
Anthropic.
Test Plan:
Linux, AMD Instinct MI250X (gfx90a), ROCm 7.2.1:
```
export USE_HIP=1
python -c "
from brian2 import *
import brian2cuda
set_device('cuda_standalone', build_on_run=False)
G = NeuronGroup(100, 'dv/dt = -v/(10*ms) : 1', threshold='v>0.5', reset='v=0', method='linear')
G.v = 'rand()'
S = Synapses(G, G, on_pre='v_post += 0.1', delay=1*ms); S.connect(p=0.1)
run(1*ms)
device.build(directory='/tmp/brian2cuda_test', compile=True, run=True)
"
```
Compiles and runs, exercising the spike queue with synapses. Also validated on
gfx1100 (RDNA3, Linux) and gfx1201 (RDNA4, Windows): GPU simulations of LIF
groups, synaptic-delay spike queues, and a recurrent network pass.
|
Hi @jeffdaily, many thanks for this PR (and apologies for the late reaction). I am afraid I won't be able to review this right away – not the least because I don't have readily access to a PC with an AMD card right now. Regarding the tests you ran, you state "GPU simulations were generated, compiled, and run, with results exercising the spike queue and synapses[...] Covered: a 100-neuron LIF group, a source/target group with a 1 ms synaptic delay (the spike-queue spinlock path), and a 200-neuron recurrent network (~12k synapses, ~6500 spikes). ". Did you run any of the existing examples for that and if yes, which one? Please also note that we are in the process of clarifying our policy with respect to LLM-assisted contributions and I am hesitant to merge this before. |
|
Note: this reply was drafted by an AI assistant. Hi @mstimberg, following up with concrete numbers. I've now run the bundled examples on the AMD hardware (gfx90a / MI250X, ROCm 7.2.1), each building, compiling and running through the HIP backend:
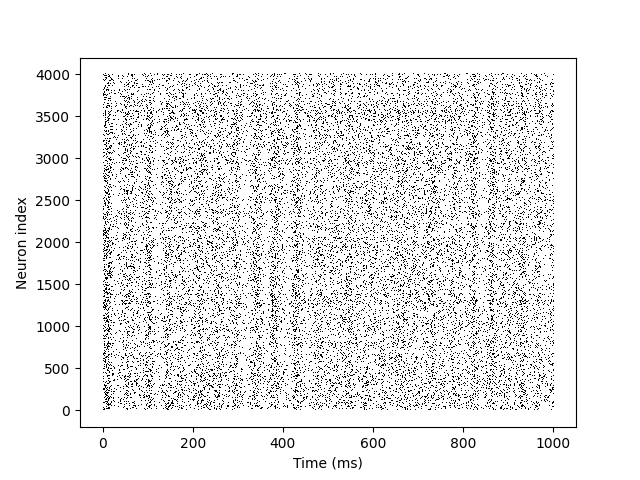
Since these examples plot rather than assert on their outputs, I used the CUBA CUBA (
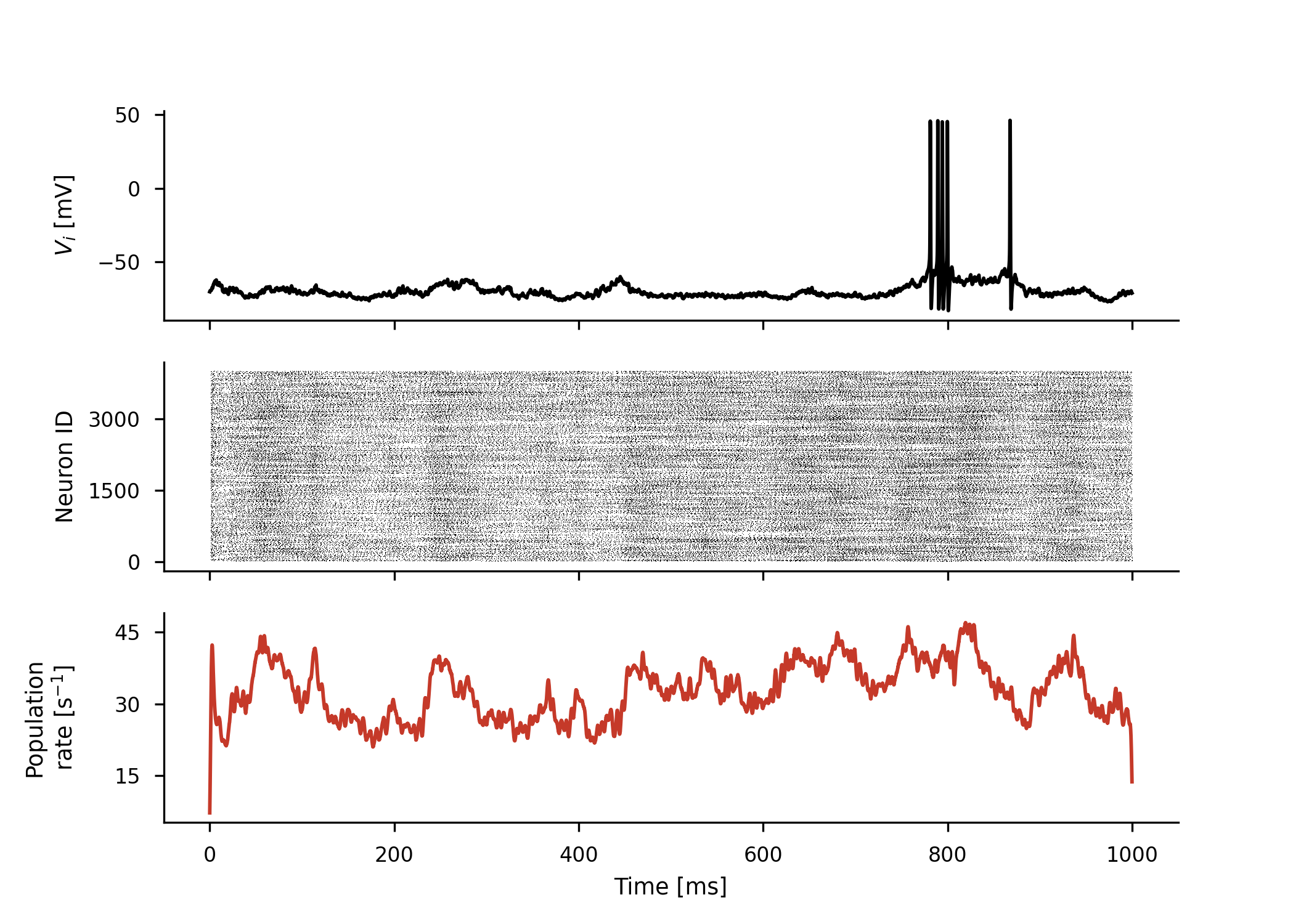
COBAHH (
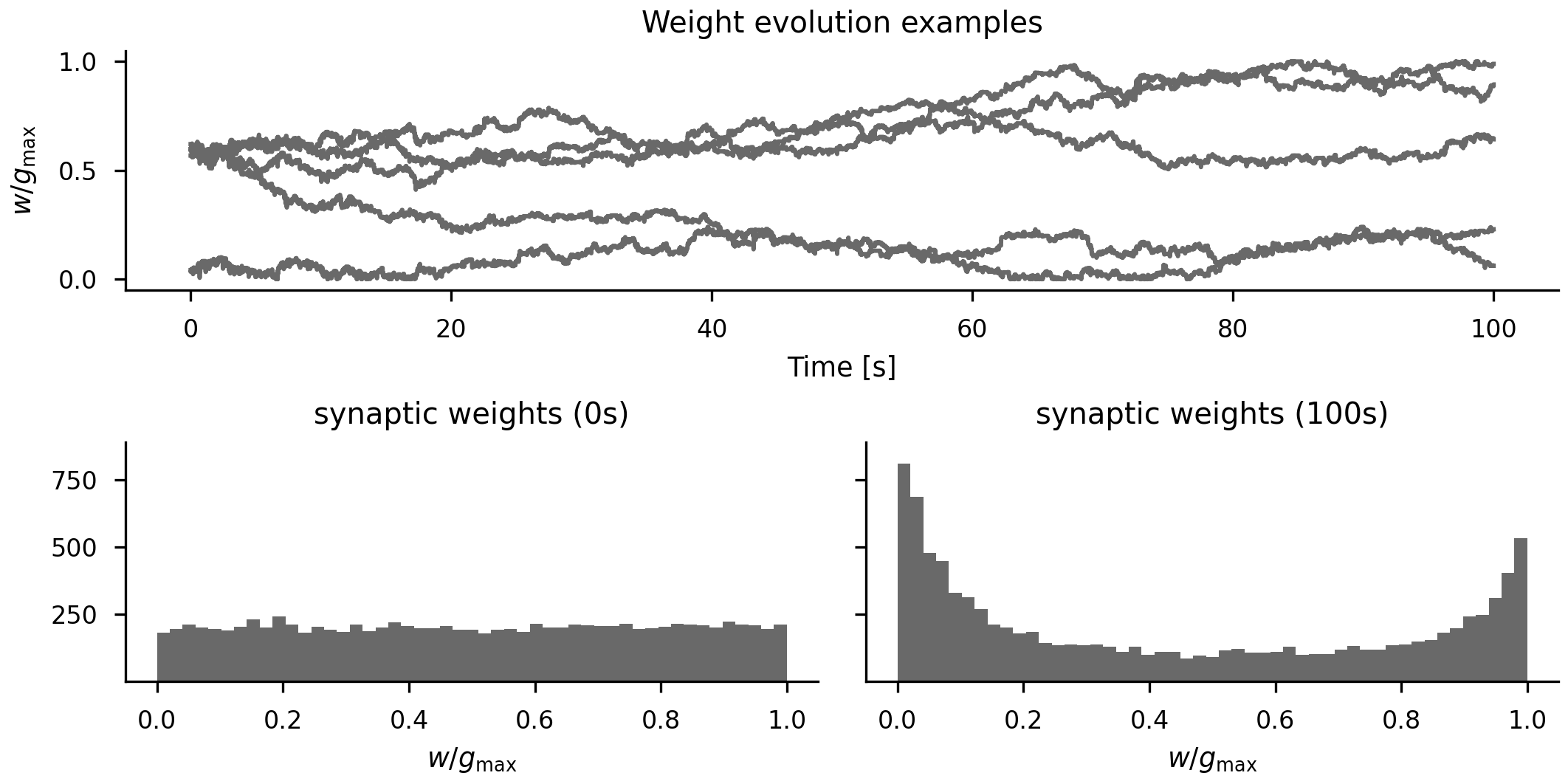
STDP (
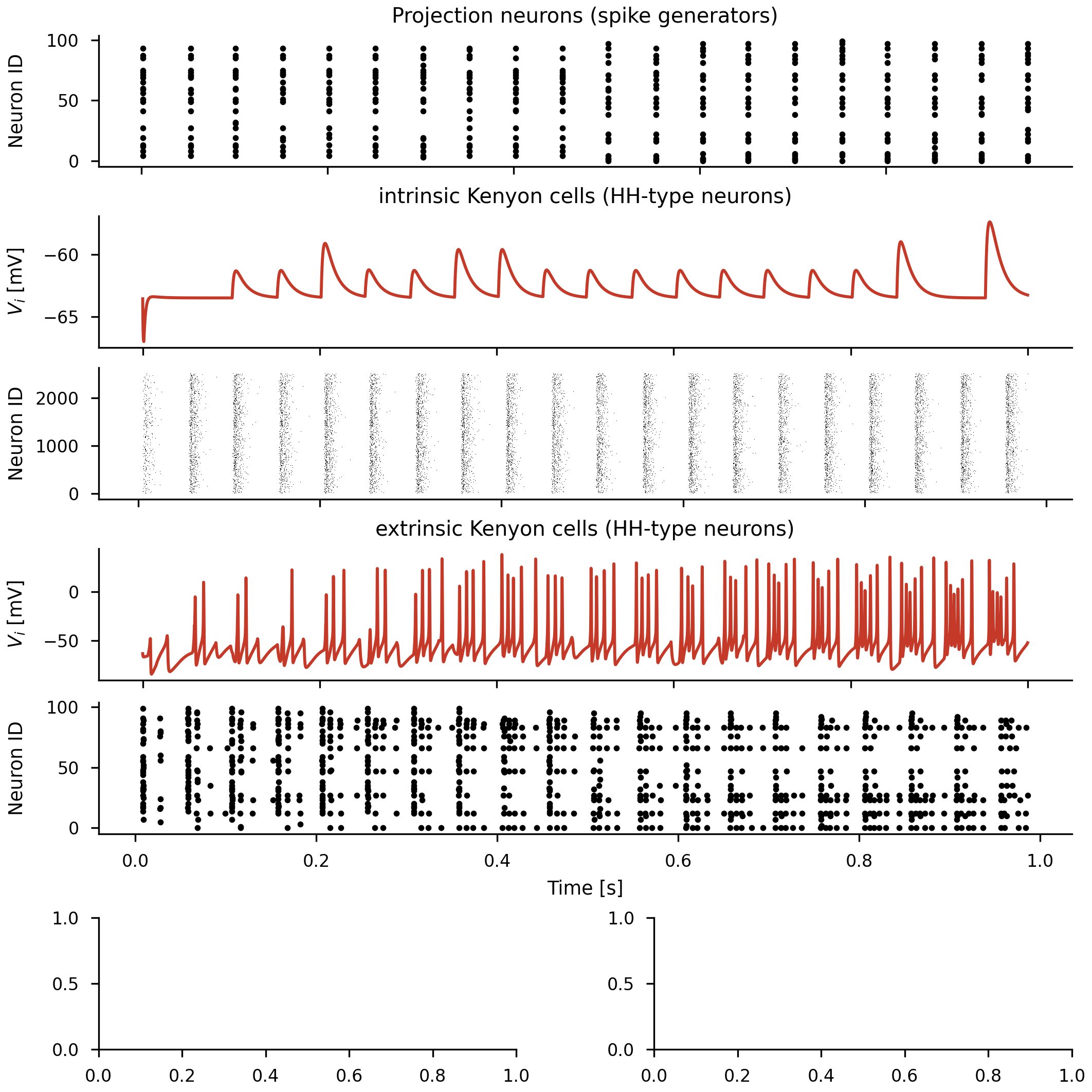
Mushroom body (
|
Hi @mstimberg. This is the actual Jeff replying now. Which is weird to have to say. There's no emergency hurry to get this PR landed. I'm fine either waiting for your LLM-assisted contrib guidance to materialize or your trying to find some AMD hardware to try it out yourself. I simply wanted to prove that this could run on some diverse AMD hardware on both Linux and Windows. I'm using your project and many others like it to prove this point, that AMD hardware and our ROCm software is ready. I'm finding that one of the last hurdles is simply doing the work of these porting efforts. I alone don't have enough time to do all these ports myself, which is why I'm using Claude to assist me. Rest assured, I'm doing the final human review before the PR is created. It's by far the slowest part of this process, me. Otherwise, I can just guide Claude. It's doing remarkably well after all the work I did to seed its knowledge of how to port CUDA to HIP, but it still gets things wrong, or makes some editorial decisions that I wouldn't have done and I have to correct it. Even considering my time spent correcting Claude, it's still far faster than I am. I hope you're able to accept this PR even though it was AI-assisted, knowing that a human reviewed it first and that we did run it on all the hardware mentioned in the PR body. |
Summary
This adds a HIP/ROCm backend so Brian2CUDA runs on AMD GPUs. Brian2CUDA is a runtime code generator (it emits a standalone C++/CUDA project per simulation), so the port works at the generator level: a CUDA-to-HIP compatibility header maps the CUDA symbols the generated code uses to their HIP equivalents, and the device/makefile generation handles HIP-specific build requirements. The NVIDIA/CUDA path is unchanged.
The HIP backend is auto-detected when ROCm is present and CUDA is absent, or forced with
USE_HIP=1. It's documented in the README.What is implemented
brianlib/cuda_to_hip.h-- compatibility header mapping the CUDA / cuRAND symbols the generated kernels use to HIP / hipRAND, so the CUDA-spelled generated sources compile under hipcc unchanged.brianlib/spikequeue.h-- a wave-serialized spin-lock for AMD: CDNA wavefronts lack NVIDIA's independent thread scheduling, so the standardatomicCASspin-lock can deadlock when lanes in one wavefront contend; the AMD path serializes per wavefront.device.py+templates/makefile_hip-- HIP backend detection and HIP makefile generation (-fgpu-rdcfor cross-TU device-symbol linking).prefs.devices.hip_standalone.hip_backend.*(gpu_arch,rocm_path,extra_compile_args_hipcc,gpu_heap_size,gpu_id), mirroring the existingcuda_backendknobs.--rocm-device-lib-path/-Iso clang finds the ROCm device bitcode and headers, and runtime fixes (absolute exe path, copying the ROCm runtime DLLs beside the executable,ROCM_KPACK_PATHfor rocRAND kernel packages).Validation
GPU simulations were generated, compiled, and run, with results exercising the spike queue and synapses:
Covered: a 100-neuron LIF group, a source/target group with a 1 ms synaptic delay (the spike-queue spinlock path), and a 200-neuron recurrent network (~12k synapses, ~6500 spikes). The CUDA/NVIDIA path is unchanged and not affected by this backend.
This work was authored with the assistance of Claude, an AI assistant by Anthropic.