A production-grade, full-stack AI speech recognition system that transcribes any audio in any language — powered by a multi-stage AI pipeline combining vocal isolation, noise reduction, and transformer-based transcription.
🚀 Try Live Demo · ⚡ Quick Start · 📐 Architecture · ✨ Features
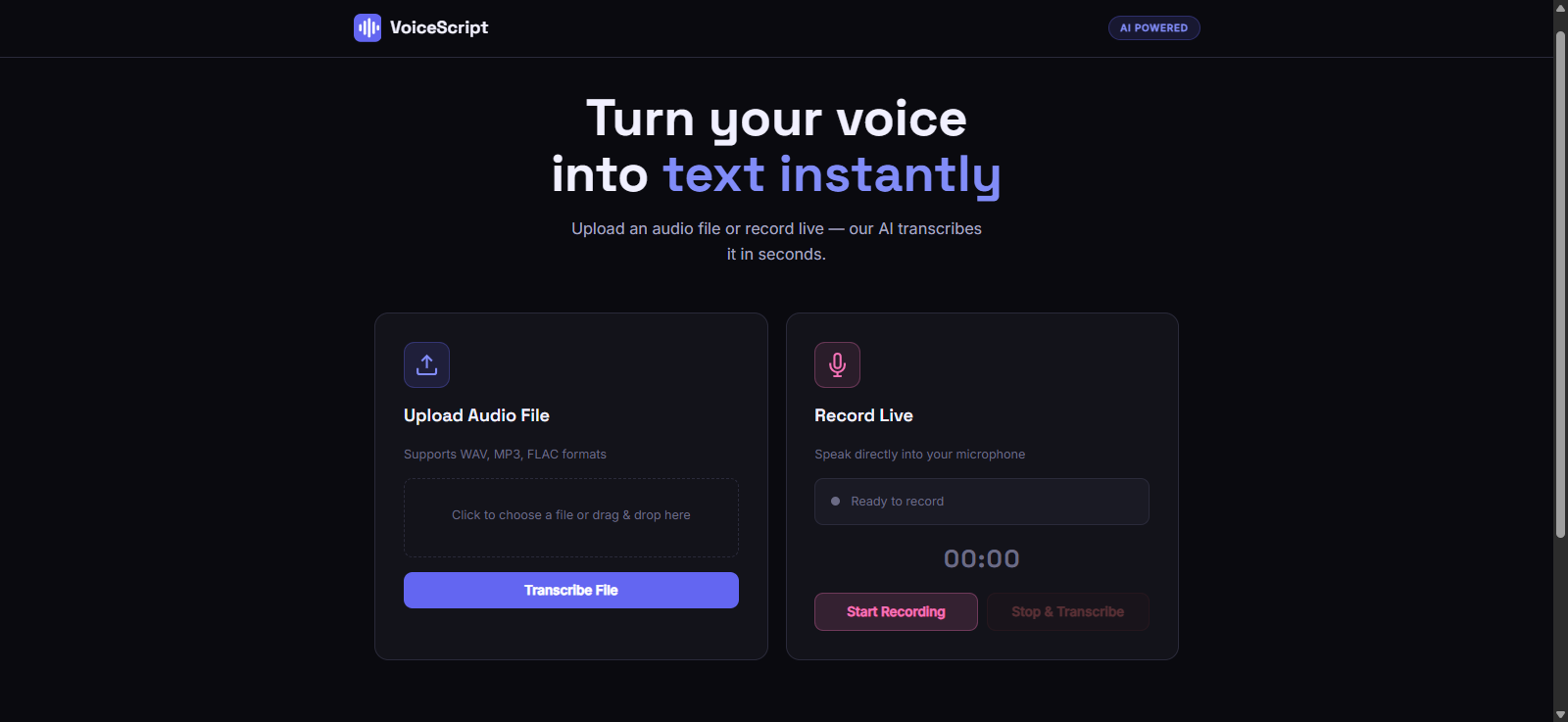
Most speech recognition tools fail in the real world because they assume clean, perfect audio. They struggle with:
- 🎵 Background music underneath speech (YouTube videos, podcasts, interviews)
- 🌍 Non-English languages — or mixed language audio
- 🔊 Crowd noise and ambient sound degrading accuracy
- ⏱️ Long audio files hitting API rate limits and time restrictions
VoiceScript solves all of this through a three-stage AI pipeline that processes audio before a single word is transcribed.
|
|
|
|
| Technology | Version | Purpose |
|---|---|---|
| Python | 3.10+ | Core backend language |
| Flask | 3.0.3 | REST API server + frontend serving |
| Flask-CORS | 4.0.1 | Cross-origin request handling |
| OpenAI Whisper | medium | Primary speech-to-text AI (769M params) |
| Facebook Demucs | 4.0.1 | Neural source separation — vocal isolation |
| pydub | 0.25.1 | Audio format conversion + preprocessing |
| deep-translator | 1.11.4 | Google Translate integration (55+ languages) |
| SpeechRecognition | 3.11.0 | Fallback recognition engine |
| NumPy | 2.4.4 | Numerical processing for Whisper |
| ffmpeg | 8.1 | Low-level audio codec processing |
| Technology | Purpose |
|---|---|
| HTML5 | Semantic structure |
| CSS3 | Dark theme, keyframe animations, responsive grid |
| Vanilla JavaScript ES6+ | MediaRecorder API, Fetch API, DOM manipulation |
| Web Audio API | Live microphone capture |
| Google Fonts | Space Grotesk + Inter typography |
| Technology | Purpose |
|---|---|
| Docker | Containerized deployment |
| Hugging Face Spaces | Production hosting (16GB RAM, free tier) |
| GitHub | Version control + CI |
┌─────────────────────────────────────────────────────────────────┐
│ FRONTEND │
│ HTML5 · CSS3 · Vanilla JS ES6+ │
│ │
│ ┌─────────────────────┐ ┌──────────────────────────────┐ │
│ │ File Upload │ │ Live Mic Recording │ │
│ │ Drag & Drop │ │ MediaRecorder API │ │
│ │ MP3/WAV/FLAC/OGG │ │ webm/ogg format │ │
│ └──────────┬──────────┘ └──────────────┬───────────────┘ │
│ └──────────────┬───────────────┘ │
│ │ HTTP POST /transcribe │
│ │ multipart/form-data + mode │
└────────────────────────────┼────────────────────────────────────┘
│
┌────────────────────────────┼────────────────────────────────────┐
│ FLASK API │
│ ▼ │
│ ┌──────────────────┐ │
│ │ app.py │ │
│ │ POST /transcribe│ │
│ │ POST /translate │ │
│ │ GET /languages │ │
│ │ GET /health │ │
│ └────────┬─────────┘ │
│ │ │
│ ┌────────────▼──────────────────────┐ │
│ │ BEAST MODE PIPELINE │ │
│ │ │ │
│ │ STAGE 1 — pydub │ │
│ │ ├─ Any format → 16kHz mono WAV │ │
│ │ ├─ Volume normalization │ │
│ │ └─ Silence stripping │ │
│ │ ↓ │ │
│ │ STAGE 2 — Facebook Demucs │ │
│ │ ├─ htdemucs model │ │
│ │ ├─ Neural source separation │ │
│ │ ├─ Isolate vocal stem │ │
│ │ └─ Discard music/noise/drums │ │
│ │ ↓ │ │
│ │ STAGE 3 — OpenAI Whisper Medium │ │
│ │ ├─ 769M parameter transformer │ │
│ │ ├─ beam_size=5 best_of=5 │ │
│ │ ├─ temperature=0 patience=2 │ │
│ │ ├─ condition_on_previous_text=True│ │
│ │ ├─ no_speech_threshold=0.25 │ │
│ │ ├─ word_timestamps=True │ │
│ │ └─ Auto language detection │ │
│ └────────────────────────────────────┘ │
│ │ │
│ JSON response: { transcript, segments, │
│ detected_language, duration, │
│ word_count, engine } │
└───────────────────────────┼─────────────────────────────────────┘
│
▼
┌─────────────────────────┐
│ FRONTEND RENDERS │
│ · Transcript text │
│ · Language badge │
│ · Timestamps view │
│ · Translation panel │
│ · Export buttons │
└─────────────────────────┘
VoiceScript/
│
├── backend/
│ ├── app.py # Flask server — all API routes
│ ├── transcriber.py # Beast mode pipeline: pydub → Demucs → Whisper
│ └── translator.py # Google Translate integration (55+ languages)
│
├── frontend/
│ ├── index.html # App structure — all UI elements
│ ├── style.css # Dark theme, keyframe animations, responsive layout
│ └── app.js # MediaRecorder, Fetch API, all interactivity
│
├── uploads/ # Temp audio storage (auto-deleted after processing)
│ └── .gitkeep
│
├── docs/
│ └── Screenshot.png # UI screenshot
│
├── Dockerfile # Docker container config for HF Spaces
├── .gitignore # Excludes venv, uploads, cache
├── requirements.txt # All Python dependencies
└── README.md # This file
- Python 3.10+
- Git
- ffmpeg —
winget install ffmpegon Windows - Modern browser (Chrome, Edge, Firefox)
git clone https://github.com/TUSHARTAMRAKAR/VoiceScript.git
cd VoiceScriptpython -m venv venv
# Windows
venv\Scripts\activate
# Mac/Linux
source venv/bin/activatepip install -r requirements.txt
⚠️ First run downloads:
- Whisper
mediummodel — ~769MB (cached at~/.cache/whisper/)- Demucs
htdemucsmodel — ~300MB (cached automatically)Both are one-time downloads. Every subsequent run loads instantly.
cd backend
python app.pyOpen http://localhost:7860 in your browser. VoiceScript is running.
Deployed on Hugging Face Spaces · Docker · CPU Basic · Always On
Upload a file:
- Drop any audio file onto the upload zone
- Choose mode —
TranscribeorAny Language → English - Click Transcribe File
- Get transcript + language badge + timestamps + export options
Record live:
- Click Start Recording — allow mic access
- Speak clearly
- Click Stop & Transcribe
- Transcript appears in seconds
Translate:
- After transcription, the Translate panel appears
- Pick any of 55+ languages from the dropdown
- Click Translate — Google Translate does the rest
Export:
- TXT — plain text file with metadata header
- SRT — subtitle file with timestamps, ready for YouTube/VLC
- PDF — opens a clean print-ready page, save as PDF
Change Whisper model in backend/transcriber.py:
# tiny | base | small | medium | large-v3
# medium = best CPU balance (default)
# large-v3 = maximum accuracy (needs GPU for practical speed)
WHISPER_MODEL_SIZE = "medium"Change transcription language in backend/transcriber.py:
language = "en" # en, hi, de, fr, es, ja, ko, zh...
# Remove language= entirely for auto-detection- GPU acceleration (CUDA) for large-v3 model
- Real-time streaming transcription
- Speaker diarization (who said what)
- AI summarization of long transcripts
- Transcript history (localStorage)
- Docker compose for one-command setup
- REST API documentation (Swagger/OpenAPI)
- Chrome extension for transcribing browser audio
# Fork → clone → create branch
git checkout -b feature/your-feature
# Make changes, then
git commit -m "feat: describe your change"
git push origin feature/your-feature
# Open a Pull RequestPlease follow Conventional Commits.

Full-Stack Developer · AI/ML Enthusiast · Builder
"Built with curiosity, powered by caffeine, debugged at 2AM." ☕
MIT License — Copyright (c) 2026 Tushar Tamrakar
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software to deal in the Software without restriction,
including the rights to use, copy, modify, merge, publish, distribute,
sublicense, and/or sell copies of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND.
Python · Flask · JavaScript · OpenAI Whisper · Facebook Demucs · pydub · ffmpeg · Docker · Hugging Face