Hackathon project with full-stack implementation using modern web technologies and machine learning prediction using XGBoost.



Thanks to these amazing people:
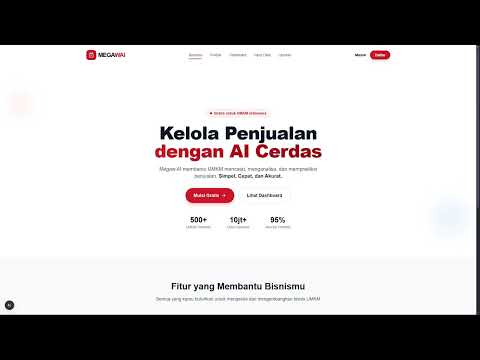
 Welcome page dengan overview sistem MEGAWAI
Welcome page dengan overview sistem MEGAWAI
 Halaman manajemen produk dan inventory
Halaman manajemen produk dan inventory
 Dashboard analytics dengan visualisasi data real-time
Dashboard analytics dengan visualisasi data real-time
 Form input data produk dan transaksi
Form input data produk dan transaksi
 Laporan lengkap dengan prediksi menggunakan XGBoost model
Laporan lengkap dengan prediksi menggunakan XGBoost model
- Runtime: Node.js v18+
- Framework: Express.js
- Language: TypeScript (compiled to JavaScript in
dist/) - ORM: Prisma
- Database: Supabase (PostgreSQL)
- Testing: Jest
- Authentication: JWT
- Validation: express-validator
- Framework: Next.js 14+ (App Router)
- Language: TypeScript
- Styling: Tailwind CSS (PostCSS)
- Linting: ESLint
- UI Components: Shadcn/ui
- State Management: Zustand/React Context
- API Client: Axios
- Database Client: Prisma Client (for direct access if needed)
- Framework: FastAPI
- ML Models: Multiple XGBoost models
ensemble.py- Ensemble model combining multiple predictionsinventory_optimizer.py- Inventory optimization modelprofit_analyzer.py- Profit analysis and predictionweekly_report_ranker.py- Weekly report ranking systemxgboost_optimal.py- Optimal XGBoost configuration
- Data Processing: Pandas, NumPy, Scikit-learn
- API Documentation: Swagger UI (auto-generated)
- CORS: FastAPI CORS middleware
- Provider: Supabase
- Type: PostgreSQL
- Features: Real-time subscriptions, Row Level Security, Auto-generated API
- Node.js v18.0.0 or higher
- Python v3.8 or higher
- Supabase Account (free tier available)
- npm or yarn package manager
git clone https://github.com/Okiled/-IMPHNEN-HEKATON.git
cd -IMPHNEN-HEKATON- Create a new project at supabase.com
- Go to Settings → Database → Copy your connection string
- Go to Settings → API → Copy your
anonkey andservice_rolekey
cd backend
# Install dependencies
npm install
# Create environment file
cp .env.example .envEdit .env file:
# Supabase Database URL
DATABASE_URL="postgresql://postgres:[YOUR-PASSWORD]@db.[YOUR-PROJECT-REF].supabase.co:5432/postgres"
# Or use connection pooling (recommended for production)
DATABASE_URL="postgresql://postgres:[YOUR-PASSWORD]@db.[YOUR-PROJECT-REF].supabase.co:6543/postgres?pgbouncer=true"
# Server
PORT=3001
NODE_ENV=development
# JWT
JWT_SECRET="your-super-secret-jwt-key-change-this"
JWT_EXPIRES_IN="7d"
# Supabase
SUPABASE_URL="https://[YOUR-PROJECT-REF].supabase.co"
SUPABASE_ANON_KEY="your-anon-key"
SUPABASE_SERVICE_KEY="your-service-role-key"
# Python Service
PYTHON_SERVICE_URL="http://localhost:8000"
# CORS
ALLOWED_ORIGINS="http://localhost:3000"Continue setup:
# Generate Prisma Client
npx prisma generate
# Push schema to Supabase
npx prisma db push
# Or run migrations
npx prisma migrate dev --name init
# Build TypeScript
npm run build
# Start development server (with hot reload)
npm run dev
# Or start production server
npm startBackend will run on: http://localhost:3001
cd frontend
# Install dependencies
npm install
# Create environment file
cp .env.example .env.localEdit .env.local:
# Backend API
NEXT_PUBLIC_API_URL=http://localhost:3001
# Python ML Service
NEXT_PUBLIC_ML_API_URL=http://localhost:8000
# Supabase (for direct client access if needed)
NEXT_PUBLIC_SUPABASE_URL=https://[YOUR-PROJECT-REF].supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key
# App
NEXT_PUBLIC_APP_URL=http://localhost:3000
NEXT_PUBLIC_APP_NAME="JIMPHNEN HEKATON"Start frontend:
npm run devFrontend will run on: http://localhost:3000
cd python-service
# Create virtual environment
python -m venv venv
# Activate virtual environment
# Windows:
venv\Scripts\activate
# macOS/Linux:
source venv/bin/activate
# Install dependencies
pip install -r requirements.txtCreate .env file:
# Server
PORT=8000
HOST=0.0.0.0
# API Configuration
API_KEY="your-python-service-api-key"
ALLOWED_ORIGINS="http://localhost:3000,http://localhost:3001"
# Model Configuration
MODEL_PATH="./models/xgboost_model.pkl"
MODEL_VERSION="1.0.0"Start service:
# Development
uvicorn main:app --reload --port 8000
# Or with python
python main.pyPython service will run on: http://localhost:8000
FastAPI Docs: http://localhost:8000/docs
{
"name": "jimphnen-backend",
"version": "1.0.0",
"scripts": {
"dev": "nodemon --exec ts-node src/index.ts",
"build": "tsc",
"start": "node dist/index.js",
"test": "jest",
"test:watch": "jest --watch",
"test:coverage": "jest --coverage",
"lint": "eslint src/**/*.ts",
"prisma:generate": "prisma generate",
"prisma:migrate": "prisma migrate dev",
"prisma:studio": "prisma studio"
},
"dependencies": {
"express": "^4.18.0",
"@prisma/client": "^5.0.0",
"cors": "^2.8.5",
"dotenv": "^16.0.0",
"jsonwebtoken": "^9.0.0",
"bcryptjs": "^2.4.3",
"express-validator": "^7.0.0",
"morgan": "^1.10.0",
"axios": "^1.6.0"
},
"devDependencies": {
"@types/express": "^4.17.0",
"@types/node": "^20.0.0",
"@types/bcryptjs": "^2.4.0",
"@types/jsonwebtoken": "^9.0.0",
"@types/cors": "^2.8.0",
"@types/morgan": "^1.9.0",
"prisma": "^5.0.0",
"typescript": "^5.0.0",
"ts-node": "^10.9.0",
"nodemon": "^3.0.0",
"jest": "^29.0.0",
"@types/jest": "^29.0.0",
"ts-jest": "^29.0.0",
"eslint": "^8.0.0",
"@typescript-eslint/parser": "^6.0.0",
"@typescript-eslint/eslint-plugin": "^6.0.0"
}
}fastapi==0.104.1
uvicorn[standard]==0.24.0
xgboost==2.0.3
pandas==2.1.3
numpy==1.26.2
scikit-learn==1.3.2
pydantic==2.5.0
python-dotenv==1.0.0
python-multipart==0.0.6# Supabase Database
DATABASE_URL="postgresql://postgres:[PASSWORD]@db.[PROJECT-REF].supabase.co:6543/postgres?pgbouncer=true"
# Server
PORT=3001
NODE_ENV=development
# JWT Authentication
JWT_SECRET="your-super-secret-jwt-key-minimum-32-characters"
JWT_EXPIRES_IN="7d"
# Supabase API (optional - for direct Supabase features)
SUPABASE_URL="https://[PROJECT-REF].supabase.co"
SUPABASE_ANON_KEY="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9..."
SUPABASE_SERVICE_KEY="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9..."
# CORS
ALLOWED_ORIGINS="http://localhost:3000"
# Python Service
PYTHON_SERVICE_URL="http://localhost:8000"# Backend API
NEXT_PUBLIC_API_URL=http://localhost:3001
# Python ML API
NEXT_PUBLIC_ML_API_URL=http://localhost:8000
# Supabase (if using Supabase client directly)
NEXT_PUBLIC_SUPABASE_URL=https://[PROJECT-REF].supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
# Database (for Prisma Client in frontend - optional)
DATABASE_URL="postgresql://postgres:[PASSWORD]@db.[PROJECT-REF].supabase.co:6543/postgres?pgbouncer=true"
# App Configuration
NEXT_PUBLIC_APP_URL=http://localhost:3000
NEXT_PUBLIC_APP_NAME="JIMPHNEN HEKATON"
# Feature Flags
NEXT_PUBLIC_ENABLE_AUTH=true
NEXT_PUBLIC_ENABLE_ML_FEATURES=true
NEXT_PUBLIC_ENABLE_ANALYTICS=false# Server Configuration
PORT=8000
HOST=0.0.0.0
WORKERS=4
# API Security
API_KEY="your-secure-api-key-change-this"
ALLOWED_ORIGINS="http://localhost:3000,http://localhost:3001"
# XGBoost Model
MODEL_PATH="./models/artifacts"
MODEL_VERSION="1.0.0"
MAX_PREDICTION_BATCH=1000
# Model Configuration
ENSEMBLE_WEIGHTS="inventory:0.3,profit:0.4,weekly_report:0.3"
ENABLE_MODEL_CACHING=true
CACHE_TTL_SECONDS=3600
# Logging
LOG_LEVEL="INFO"// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id String @id @default(uuid())
email String @unique
name String?
password String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
model Prediction {
id String @id @default(uuid())
userId String
input Json
result Json
modelVersion String
createdAt DateTime @default(now())
user User @relation(fields: [userId], references: [id])
}# Generate Prisma Client
npx prisma generate
# Push schema to Supabase (no migrations)
npx prisma db push
# Create and apply migrations
npx prisma migrate dev --name your_migration_name
# View database in Prisma Studio
npx prisma studio
# Reset database
npx prisma migrate reset
# Format schema file
npx prisma format
# Pull schema from existing database
npx prisma db pullAccess Supabase Dashboard: https://app.supabase.com/project/[YOUR-PROJECT-REF]
- Table Editor: Visual database management
- SQL Editor: Run custom queries
- Auth: Built-in authentication
- Storage: File storage
- Realtime: WebSocket subscriptions
- Edge Functions: Serverless functions
Base URL: http://localhost:3001/api
POST /api/auth/register - Register new user
POST /api/auth/login - Login user
POST /api/auth/refresh - Refresh JWT token
GET /api/auth/me - Get current user profile
GET /api/users - Get all users (admin)
GET /api/users/:id - Get user by ID
PUT /api/users/:id - Update user
DELETE /api/users/:id - Delete user
POST /api/predictions - Create new prediction (calls Python service)
GET /api/predictions - Get user's predictions
GET /api/predictions/:id - Get prediction by ID
Base URL: http://localhost:8000
Interactive Docs: http://localhost:8000/docs (Swagger UI)
Alternative Docs: http://localhost:8000/redoc (ReDoc)
GET / - Health check
POST /predict - Make prediction with XGBoost model
POST /predict/ensemble - Ensemble prediction
POST /predict/inventory - Inventory optimization prediction
POST /predict/profit - Profit analysis prediction
POST /predict/weekly-report - Weekly report ranking
POST /batch-predict - Batch predictions
GET /model/info - Get model information
GET /model/features - Get model feature names
GET /models/list - List all available modelscurl -X POST "http://localhost:8000/predict" \
-H "Content-Type: application/json" \
-d '{
"features": {
"feature1": 1.5,
"feature2": 2.3,
"feature3": 0.8
}
}'{
"prediction": 0.85,
"probability": 0.8523,
"model_version": "1.0.0",
"timestamp": "2024-12-07T10:30:00Z"
}The Python service includes multiple specialized XGBoost models:
Combines predictions from multiple models for more robust results.
POST /predict/ensemble
{
"features": {...},
"models": ["inventory", "profit", "weekly_report"]
}Optimizes inventory levels based on historical data and demand forecasting.
POST /predict/inventory
{
"product_id": "ABC123",
"current_stock": 100,
"sales_history": [...],
"lead_time_days": 7
}Analyzes and predicts profit margins based on various business metrics.
POST /predict/profit
{
"revenue": 10000,
"costs": 6000,
"market_conditions": {...}
}Ranks and prioritizes weekly reports based on importance and urgency.
POST /predict/weekly-report
{
"report_data": {...},
"metrics": [...],
"priority_factors": {...}
}Optimal XGBoost configuration for general-purpose predictions.
All trained models are stored in models/artifacts/ directory:
- Models are versioned with unique identifiers
- Each model includes metadata and performance metrics
- Models can be hot-swapped without restarting the service
# python-service/main.py
from fastapi import FastAPI, HTTPException
from models.artifacts import (
ensemble,
inventory_optimizer,
profit_analyzer,
weekly_report_ranker,
xgboost_optimal
)
app = FastAPI(
title="JIMPHNEN ML Service",
description="Machine Learning API with multiple XGBoost models",
version="1.0.0"
)
@app.post("/predict/inventory")
async def predict_inventory(data: dict):
"""Optimize inventory levels"""
try:
result = inventory_optimizer.predict(data)
return {
"optimization": result,
"model": "inventory_optimizer",
"version": "1.0.0"
}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))
@app.post("/predict/profit")
async def predict_profit(data: dict):
"""Analyze profit margins"""
try:
result = profit_analyzer.predict(data)
return {
"profit_analysis": result,
"model": "profit_analyzer",
"version": "1.0.0"
}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))
@app.post("/predict/ensemble")
async def predict_ensemble(data: dict):
"""Ensemble prediction using multiple models"""
try:
result = ensemble.predict(data)
return {
"ensemble_prediction": result,
"models_used": ["inventory", "profit", "weekly_report"],
"version": "1.0.0"
}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))Training scripts are located in the training/ directory:
cd python-service/training
# Train a specific model
python train_inventory_model.py
# Train all models
python train_all_models.py
# Evaluate model performance
python evaluate_models.pyOption 1: Manual (3 terminals)
# Terminal 1 - Backend
cd backend
npm run dev
# Terminal 2 - Frontend
cd frontend
npm run dev
# Terminal 3 - Python Service
cd python-service
source venv/bin/activate # or venv\Scripts\activate on Windows
uvicorn main:app --reloadOption 2: Using concurrently (recommended)
Create package.json in root:
{
"scripts": {
"dev": "concurrently \"npm run dev:backend\" \"npm run dev:frontend\" \"npm run dev:python\"",
"dev:backend": "cd backend && npm run dev",
"dev:frontend": "cd frontend && npm run dev",
"dev:python": "cd python-service && venv/Scripts/activate && uvicorn main:app --reload"
},
"devDependencies": {
"concurrently": "^8.2.0"
}
}Then run:
npm run dev# Backend tests (Jest)
cd backend
npm test # Run all tests
npm run test:watch # Watch mode
npm run test:coverage # Coverage report
# Frontend tests
cd frontend
npm test # Run tests
npm run test:e2e # E2E tests (if configured)
# Python tests (pytest)
cd python-service
pytest # Run all tests
pytest --cov # With coverage
pytest -v # Verbose output# Backend - ESLint & TypeScript
cd backend
npm run lint # Check for issues
npm run lint:fix # Fix issues automatically
npx tsc --noEmit # Type checking
# Frontend - ESLint
cd frontend
npm run lint # Check for issues
npm run lint:fix # Fix issues
# Python - Pylint & Black
cd python-service
pylint **/*.py # Lint Python files
black . --check # Check formatting
black . # Format filescd backend
# Build TypeScript to JavaScript
npm run build
# This compiles src/ to dist/
# Start production server
NODE_ENV=production npm start
# Runs compiled code from dist/
# Or use PM2 for production
npm install -g pm2
pm2 start dist/index.js --name jimphnen-backend
pm2 save
pm2 startupcd frontend
# Build for production
npm run build
# Start production server
npm startcd python-service
# Run with Gunicorn
gunicorn main:app --workers 4 --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000
# Or with Uvicorn
uvicorn main:app --host 0.0.0.0 --port 8000 --workers 4version: '3.8'
services:
backend:
build: ./backend
ports:
- "3001:3001"
environment:
- DATABASE_URL=${DATABASE_URL}
- JWT_SECRET=${JWT_SECRET}
depends_on:
- python-service
frontend:
build: ./frontend
ports:
- "3000:3000"
environment:
- NEXT_PUBLIC_API_URL=http://backend:3001
- NEXT_PUBLIC_ML_API_URL=http://python-service:8000
depends_on:
- backend
python-service:
build: ./python-service
ports:
- "8000:8000"
environment:
- MODEL_PATH=/app/models/xgboost_model.pklRun:
docker-compose up -d| Service | Platform | Why |
|---|---|---|
| Backend | Railway, Render | Easy Node.js deployment, free tier |
| Frontend | Vercel | Optimized for Next.js, automatic deployments |
| Python Service | Railway, Render | Python support, easy FastAPI deployment |
| Database | Supabase | Already using it, free tier generous |
# Install Vercel CLI
npm i -g vercel
# Deploy
cd frontend
vercel
# Production deployment
vercel --prod- Connect your GitHub repo
- Create new project
- Add services: backend, python-service
- Set environment variables
- Deploy automatically on push
For production with Prisma, use connection pooling:
# Use port 6543 with pgbouncer
DATABASE_URL="postgresql://postgres:[PASSWORD]@db.[PROJECT-REF].supabase.co:6543/postgres?pgbouncer=true"- ✅ Use environment variables for secrets
- ✅ Enable CORS with specific origins only
- ✅ Implement rate limiting (express-rate-limit)
- ✅ Use HTTPS in production
- ✅ Hash passwords with bcrypt
- ✅ Validate all inputs (express-validator)
- ✅ Enable Supabase Row Level Security (RLS)
- ✅ Use API keys for Python service
- ✅ Keep dependencies updated
- Fork the repository
- Create feature branch (
git checkout -b feature/amazing-feature) - Commit changes (
git commit -m 'Add amazing feature') - Push to branch (
git push origin feature/amazing-feature) - Open Pull Request
This project is licensed under the MIT License.
Found a bug? Open an issue
Project Repository: https://github.com/Okiled/-IMPHNEN-HEKATON
⭐ Star this repo if you find it helpful!
Made with ❤️ by the MEGAW AI Team