This Neural Network Project was inspired by the Kaggle BirdClef-2022 Competition to classify bird calls. This journal shows our approach to classifying bird calls from the birdclef-2022 dataset.
As the “extinction capital of the world," Hawai'i has lost 68% of its bird species, the consequences of which can harm entire food chains. Researchers use population monitoring to understand how native birds react to changes in the environment and conservation efforts, but many of the remaining birds across the islands are isolated in difficult-to-access, high-elevation habitats. With physical monitoring difficult, scientists have turned to sound recordings known as bioacoustic monitoring. This approach could provide a passive, low labor, and cost-effective strategy for studying endangered bird populations.
Current methods for processing large bioacoustic datasets involve manual annotation of each recording. This requires specialized training and prohibitively large amounts of time. Thankfully, recent advances in machine learning have made it possible to automatically identify bird songs for common species with ample training data. However, it remains challenging to develop such tools for rare and endangered species, such as those in Hawai'i.
The Cornell Lab of Ornithology's K. Lisa Yang Center for Conservation Bioacoustics (KLY-CCB) develops and applies innovative conservation technologies across multiple ecological scales to inspire and inform the conservation of wildlife and habitats. KLY-CCB does this by collecting and interpreting sounds in nature and they've joined forces with Google Bioacoustics Group, LifeCLEF, Listening Observatory for Hawaiian Ecosystems (LOHE) Bioacoustics Lab at the University of Hawai'i at Hilo, and Xeno-Canto for this competition.
In this competition, you’ll use your machine learning skills to identify bird species by sound. Specifically, you'll develop a model that can process continuous audio data and then acoustically recognize the species. The best entries will be able to train reliable classifiers with limited training data.
If successful, you'll help advance the science of bioacoustics and support ongoing research to protect endangered Hawaiian birds. Thanks to your innovations, it will be easier for researchers and conservation practitioners to accurately survey population trends. They'll be able to regularly and more effectively evaluate threats and adjust their conservation actions."
Inspired by BirdCLEF 2022
- Approach
- Preprocessing the data
- Creating, training and evaluating the model
- Conclusion and Future Plans
Our approach involves restructuring the audio (.ogg) files into mel-spectrograms and feeding these spectrograms into a convolutional Neural Network. Two appraoches were taken in the development of this model:
- Passing the Mel-Spectrograms into a Tensorflow Conv2d network
- Transfer learning using MobileNetV2 Neural Network to extract important features from Mel-Spectrograms and then passing those features through a vanilla-Neural Network for classification (Accuracy on Testing Data = 89.18)
We Decided to complete this project by using audo files from only 6 of the available birds, each with 500 audio files each totalling 3000 audio files
Using a combination of approaches from Magdalena Kortas in https://towardsdatascience.com/sound-based-bird-classification-965d0ecacb2b and Jeff Prosise in https://github.com/jeffprosise/Deep-Learning/blob/master/Audio%20Classification%20(CNN).ipynb, we will be building a similar model that converts bird audio files into melfrequency spectrogram images, which will then be passed through a convolutional neural network to detect bird species.
Convolutional Neural Network (CNN)
A Convolutional Neural Network is a class of artificial neural network that is most commonly used for image recognition. The most significant feature of CNNs are their ability to "successfully capture the Spatial and Temporal dependencies" of images (Saha). Many of the competitors in previous years of BirdCLEF have achieved best results using a Convolutional Neural Network classifier that takes a visual representation of bird calls as the input as opposed to other classes of neural networks (such Recursive Neural Networks (RNNs), General Adversarial Neural Networks (GAN), etc...).
Learn more about them here:
https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
Spectrogram vs Mel Frequency Spectrogram
This is what a spectrogram looks like:

Fig.1 - Spectrogram
Spectrogram Definition (According to The Pacific Northwest Seismic Network) - "A spectrogram is a visual way of representing the signal strength, or 'loudness', of a signal over time at various frequencies present in a particular waveform. Not only can one see whether there is more or less energy at, for example, 2 Hz vs 10 Hz, but one can also see how energy levels vary over time." To generate a spectrogram, one of the approaches you can take is to do a fourier transform. In this case, a fourier transform would "decompose" (change) the audio signal into its constituent frequencies (simply put, it shows which pitches are the most significant of loud over a period of time).

Fig.2 - Mel Frequency Spectrogram
A mel frequency spectrogram is a variant of the spectrogram where the frequencies (y-axis) are converted the mel (log) scale.
The significance of the mel scale is that it is a logarithmic scale of frequency that more closely resembles the way that humans perceive sound. Humans are quite good at differentiating low frequencies, but struggle with differentiating as frequencies increase. Since humans are the ones labeling and listening the data, it would follow that we would also want the neural network to "learn" the patterns that human listeners noticed.
The logic behind this approach is that a convolutional neural network will be able to pick up on the correlation between the frequency patterns of the bird calls (due to the spectrogram measuring frequncy of the audio file on the veritcal axis) as well as the correlation in time (the x-axis of the spectrogram).
- Presence of background noise in the environment
- Birds have many types of calls and the different types have different functions
- Inter-species variance: there is individual variation between birds of the same species
Sample 1: Barn Owl (brnowl)
https://user-images.githubusercontent.com/79030095/166409384-03a05969-ad4d-4408-9a07-d3852db8b580.mov
Sample 2: Common Sandpiper (comsan)
https://user-images.githubusercontent.com/79030095/166409600-3cbc98b3-ca36-46f8-aef5-04153c6eaf58.mov
Sample 3: House Sparrow (houspa)
https://user-images.githubusercontent.com/79030095/166409495-77625c90-c58f-465b-bcfb-478bc7a1cea1.mov
Sample 4: Mallard (mallar3)
https://user-images.githubusercontent.com/79030095/166409672-bc83f331-6eb1-4559-a249-0148f30817c8.mov
Sample 5: Northern Cardinal (norcar)
https://user-images.githubusercontent.com/79030095/166409754-2d272838-7867-4df0-8eb5-281e47e057e2.mov
Sample 6: Eurasian Skylark (skylar)
https://user-images.githubusercontent.com/79030095/166409884-b96a56f9-352c-4a4b-83d6-e5c98e13a8f1.mov
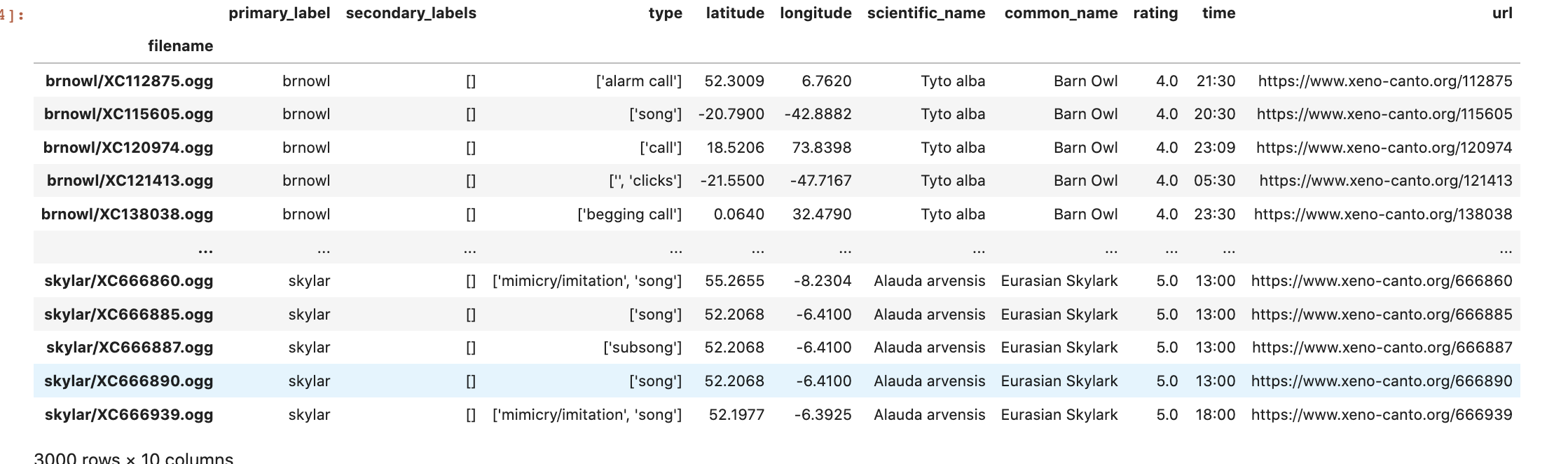
We first downloaded the training/test data from the BirdCLEF competition here: https://www.kaggle.com/competitions/birdclef-2022/data. This dataset provides audio files along with various categorical information (such as track_id, bird names, species, scientific name, etc) from over 150 different bird calls in csv format. For this neural network, only the sound files and bird names were utilized.

The CSV file was then uploaded to a dataframe in our journal, allowing us to restructure the data. To simplify this project for our deadlines, we decided to only use sound files from the birds with the most sound files. The following 6 birds were used in classification (Each bird with 500 audiofiles)
- Barn Owl (brnowl)
- Common Sandpiper (comsan)
- House Sparrow (houspa)
- Mallard (mallar3)
- Northern Cardinal (norcar)
- Eurasian Skylark (skylar)
The audio files from these birds were separated from the original dataframe and placed in a separate python dataframe
Utilizing the librosa python package, we then converted each audio file into a mel-spectrogram
Here are a few examples:
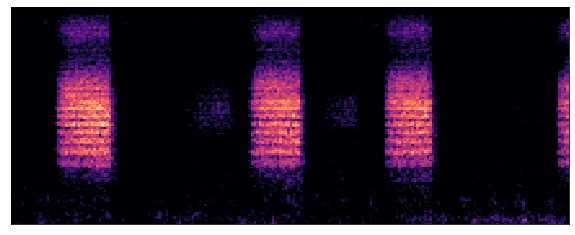
Fig.4 - Barn Owl Mel Frequency Spectrogram
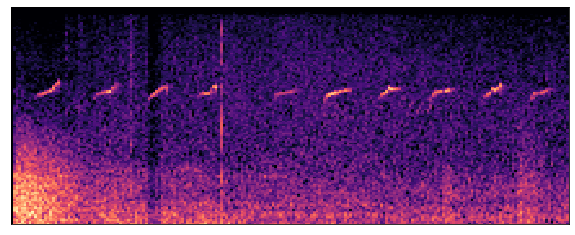
Fig.5 - Common Sandpiper Mel Frequency Spectrogram
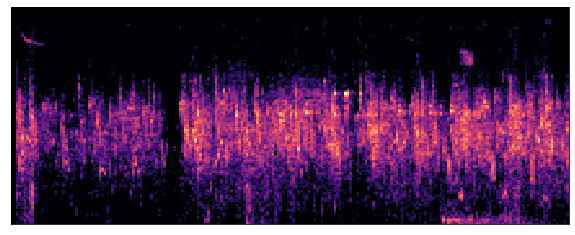
Fig.6 - House Sparrow Mel Frequency Spectrogram
Using a 80%, 10%, 10% split of training, validation, and testing data, we created a convolution neural network using the Keras library.
- input to model = normalized (divided by 255) mel-spectrogram image
- Output of model = Bird Code
Using this initial model we obtained the following results:
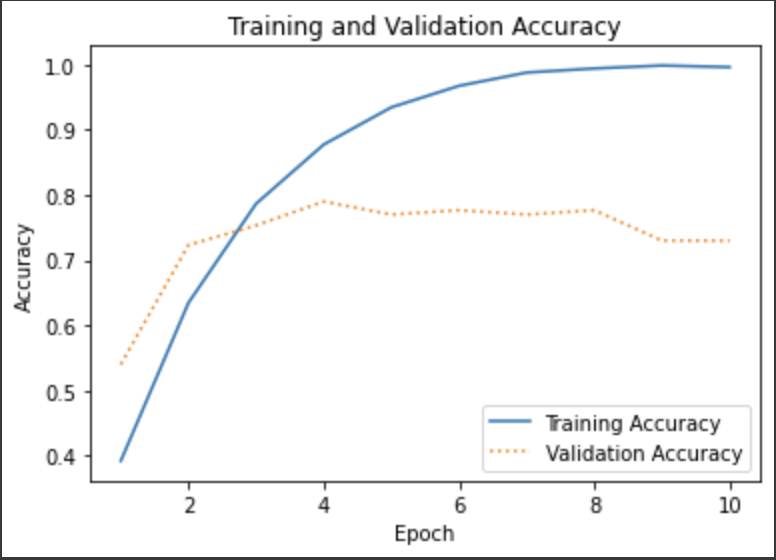
Fig.7 - Novel Convolutional Neural Network
At a batch size of 128 at 10 epochs, this model gave a surprisingly high accuracy. To further increase our accuracy, we decided to use MobileNetV2, a pretrained image classification model provided by Keras, to extract features from our mel-spectrogram.

We then used these extracted features as inputs to a Vanilla Neural Network. With this method, we were able to achieve an accuracy of ~90% on testing data:
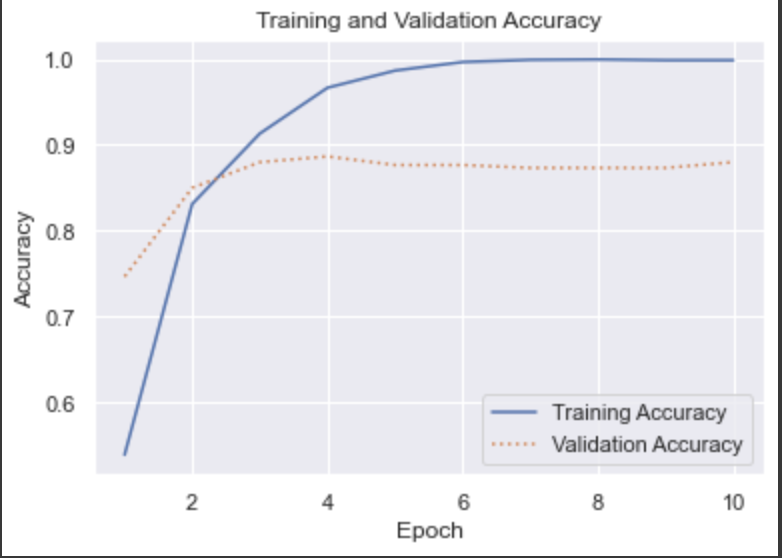
Fig.8 - MobileNetV2 Transfered Neural Network
The following HeatMap for the performance of the MobileNetV2 edition of the CNN shows how well this model was able to distinguish between different bird type:
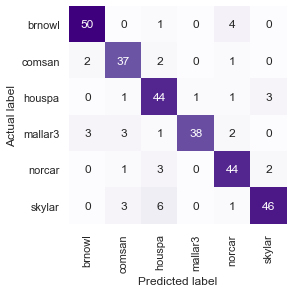
Example: You can see how brnowl can sometimes be confused with norcar or houspa, Skylar is mostly confused to be a houspa or comsan, mallar3 is mostly confused with comsan and brnowl, etc...
Our convolutional neural network and MobileNetV2 assisted network were able to achieve a relatively high testing accuracy. The top 6 most used birds can be distinguished with 90% accuracy. To improve this model our team will utilize the rest of the audio files in future iterations.
Sources:
https://ebird.org/home
https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53
https://towardsdatascience.com/sound-based-bird-classification-965d0ecacb2b
https://www.kaggle.com/competitions/birdclef-2022/data
https://pnsn.org/spectrograms/what-is-a-spectrogram
https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
https://github.com/jeffprosise/Deep-Learning/blob/master/Audio%20Classification%20(CNN).ipynb