-
-
diff --git a/docs/source/methods/overview.md b/docs/source/methods/overview.md
new file mode 100644
index 0000000000..a63f9571ea
--- /dev/null
+++ b/docs/source/methods/overview.md
@@ -0,0 +1,68 @@
+
+
+
+# Parameter efficient fine-tuning methods
+
+Training a model parameter efficiently means to train as few parameters as possible to achieve comparable performance to training all parameters, i.e. full fine-tuning. There is, of course, no free lunch: by using fewer and therefore less expressive, parameters, it is not guaranteed that you will get the same performance! You may need to use a specific PEFT method to get optimal results for the model/task combination you want to train. But you will need less memory and possibly less compute during training and may gain features such as fast hot-swapping between trained expert models and less forgetting of previous knowledge compared to full fine-tuning.
+
+Giving general advice for training large models is hard but for generative
+models, especially language models, you can follow these steps:
+
+1. use prompting (few-shot examples in the prompt) to see if the model is
+ already capable of the task. If the model solves your problem, great! You can
+ now use [Prompt-based methods](#prompt-based-methods) to learn the prompt and
+ save precious tokens.
+2. If prompt-based methods are not sufficient you can use [layer tuning](#layer-tuning)
+ and [adapter methods](#adapter-methods). These methods are generally
+ more expressive than prompt-based methods and get closer to full-finetuning.
+3. Make sure to measure retention of already learnt knowledge since each
+ fine-tuning step is potentially unlearning past knowledege.
+
+The [PEFT method comparison suite](https://huggingface.co/spaces/peft-internal-testing/PEFT-method-comparison) aims to give a rough overview of (most) implemented methods on selected benchmarks and models.
+
+
+## Adapter methods
+
+Adapter methods can be seen as ways of adding relatively small, trainable matrices to existing models for fine-tuning. The goal is to introduce few trainable parameters to steer the big model in the direction of the task that needs fine-tuning to save on resources, such as memory or compute.
+
+A popular way to realize adapters is to insert smaller trainable matrices that are a low-rank decomposition of the adapted weight's layout to save on memory. There are several different ways to express the weight matrix as a low-rank decomposition, but [Low-Rank Adaptation (LoRA)](../package_reference/lora) is the most common method. The PEFT library supports several other variations of this formulation - some are direct variants of LoRA and are documented under LoRA, some are different enough to count as their own methods, such as [Low-Rank Hadamard Product (LoHa)](../package_reference/loha), [Low-Rank Kronecker Product (LoKr)](../package_reference/lokr), and [Adaptive Low-Rank Adaptation (AdaLoRA)](../package_reference/adalora). If you're interested in applying these methods to other tasks and use cases like semantic segmentation, token classification, take a look at our [notebook collection](https://huggingface.co/collections/PEFT/notebooks-6573b28b33e5a4bf5b157fc1)!
+
+> [!TIP]
+> LoRA is one of the most popular PEFT methods and a good starting point if you're just getting started with PEFT. It was originally developed for large language models but it is a tremendously popular training method for diffusion models because of its efficiency and effectiveness.
+
+Low-rank adapters are only one possible adapter formualation, PEFT implements many other types of adapters as well. For example, Orthogonal Fine-Tuning methods ([OFT](../package_reference/oft), [BOFT](../package_reference/boft), ...) use orthogonal decompositions of the adapter weights to achieve small size. Methods like [MiSS](../package_reference/miss) shard matrices and share these shards to save on memory. [IA3](../package_reference/ia3) just introduces three trainable vectors to steer the original model.
+
+## Prompt-based methods
+
+Prompting primes a frozen pretrained model for a specific downstream task by including a text prompt that describes the task or even demonstrates an example of the task. With prompting, you can avoid fully training a separate model for each downstream task, and use the same frozen pretrained model instead. This is a lot easier because you can use the same model for several different tasks, and it is significantly more efficient to train and store a smaller set of prompt parameters than to train all the model's parameters.
+
+There are two categories of prompting methods:
+
+- hard prompts are manually handcrafted text prompts with discrete input tokens; the downside is that it requires a lot of effort to create a good prompt
+- soft prompts are learnable tensors concatenated with the input embeddings that can be optimized to a dataset; the downside is that they aren't human readable because you aren't matching these "virtual tokens" to the embeddings of a real word
+
+The PEFT library supports several types of prompting methods (p-tuning, prefix tuning, prompt tuning, ...), explore the table of contents for a full listing of soft prompt methods.
+If you're interested in applying these methods to other tasks and use cases, take a look at our [notebook collection](https://huggingface.co/spaces/PEFT/soft-prompting)!
+
+> [!TIP]
+> Some familiarity with the general process of training a causal language model would be really helpful and allow you to focus on the soft prompting methods. If you're new, we recommend taking a look at the [Causal language modeling](https://huggingface.co/docs/transformers/tasks/language_modeling) guide first from the Transformers documentation. When you're ready, come back and see how easy it is to drop PEFT in to your training!
+
+## Layer Tuning
+
+Layer Tuning categorizes methods that target specific layers of a model such as [LayerNorm Tuning](../package_reference/layernorm_tuning)
+or targeting specific tokens in the embedding matrix via [TrainableTokens](../package_reference/trainable_tokens).
+
diff --git a/docs/source/package_reference/adalora.md b/docs/source/package_reference/adalora.md
index 9cc51d0e09..f96142d9f2 100644
--- a/docs/source/package_reference/adalora.md
+++ b/docs/source/package_reference/adalora.md
@@ -16,16 +16,64 @@ rendered properly in your Markdown viewer.
# AdaLoRA
-[AdaLoRA](https://hf.co/papers/2303.10512) is a method for optimizing the number of trainable parameters to assign to weight matrices and layers, unlike LoRA, which distributes parameters evenly across all modules. More parameters are budgeted for important weight matrices and layers while less important ones receive fewer parameters.
+[AdaLoRA](https://hf.co/papers/2303.10512) (Adaptive LoRA) is a method for optimizing the number of trainable parameters to assign to weight matrices and layers, unlike LoRA, which distributes parameters evenly across all modules. More parameters are budgeted for important weight matrices and layers while less important ones receive fewer parameters. You can control the average desired *rank* or `r` of the matrices, and which modules to apply AdaLoRA to with `target_modules`. Other important parameters to set are `lora_alpha` (scaling factor), and `modules_to_save` (the modules apart from the AdaLoRA layers to be trained and saved). All of these parameters - and more - are found in the [`AdaLoraConfig`].
The abstract from the paper is:
*Fine-tuning large pre-trained language models on downstream tasks has become an important paradigm in NLP. However, common practice fine-tunes all of the parameters in a pre-trained model, which becomes prohibitive when a large number of downstream tasks are present. Therefore, many fine-tuning methods are proposed to learn incremental updates of pre-trained weights in a parameter efficient way, e.g., low-rank increments. These methods often evenly distribute the budget of incremental updates across all pre-trained weight matrices, and overlook the varying importance of different weight parameters. As a consequence, the fine-tuning performance is suboptimal. To bridge this gap, we propose AdaLoRA, which adaptively allocates the parameter budget among weight matrices according to their importance score. In particular, AdaLoRA parameterizes the incremental updates in the form of singular value decomposition. Such a novel approach allows us to effectively prune the singular values of unimportant updates, which is essentially to reduce their parameter budget but circumvent intensive exact SVD computations. We conduct extensive experiments with several pre-trained models on natural language processing, question answering, and natural language generation to validate the effectiveness of AdaLoRA. Results demonstrate that AdaLoRA manifests notable improvement over baselines, especially in the low budget settings. Our code is publicly available at https://github.com/QingruZhang/AdaLoRA*.
+> [!WARNING]
+> AdaLoRA has an [`~AdaLoraModel.update_and_allocate`] method that should be called at each training step to update the parameter budget and mask, otherwise the adaptation step is not performed. This requires writing a custom training loop or subclassing the [`~transformers.Trainer`] to incorporate this method. As an example, take a look at this [custom training loop](https://github.com/huggingface/peft/blob/912ad41e96e03652cabf47522cd876076f7a0c4f/examples/conditional_generation/peft_adalora_seq2seq.py#L120).
+
+AdaLoRA manages the parameter budget introduced from LoRA by allocating more parameters - in other words, a higher rank `r` - for important weight matrices that are better adapted for a task and pruning less important ones. The rank is controlled by a method similar to singular value decomposition (SVD). The $\Delta W$ is parameterized with two orthogonal matrices and a diagonal matrix which contains singular values. This parametrization method avoids iteratively applying SVD which is computationally expensive. Based on this method, the rank of $\Delta W$ is adjusted according to an importance score. $\Delta W$ is divided into triplets and each triplet is scored according to its contribution to model performance. Triplets with low importance scores are pruned and triplets with high importance scores are kept for finetuning.
+
+Training with AdaLoRA has three phases: the init phase, the budgeting phase and the final phase. In the initial phase, no budgeting is applied, therefore the ranks are not touched. During the budgeting phase the process described above is applied and the rank is redistributed according to a budget, aiming to give more important adapters more rank and less important layers less. When reaching the final phase, budgeting has ended, the ranks are redistributed but we may continue training for a while with the redistributed ranks to further improve performance.
+
+> [!NOTE]
+> **Contributions welcome**: This section needs clarification.
+>
+> It is unclear how importance is measured. The explanations are also a bit redundant and could benefit from consolidation.
+> See [here](../developer_guides/contributing#documentation-improvements) on how to contribute.
+
+## Benchmark overview
+
+
+
+## Usage
+
+
+```py
+from peft import AdaLoraConfig, get_peft_model
+
+config = AdaLoraConfig(
+ r=8,
+ init_r=12,
+ tinit=200,
+ tfinal=1000,
+ deltaT=10,
+ target_modules=["query", "value"],
+ modules_to_save=["classifier"],
+)
+model = get_peft_model(model, config)
+model.print_trainable_parameters()
+"trainable params: 520,325 || all params: 87,614,722 || trainable%: 0.5938785036606062"
+
+[... training code ...]
+
+model.update_and_allocate(step_idx)
+```
+
+# API
+
## AdaLoraConfig
[[autodoc]] tuners.adalora.config.AdaLoraConfig
## AdaLoraModel
-[[autodoc]] tuners.adalora.model.AdaLoraModel
\ No newline at end of file
+[[autodoc]] tuners.adalora.model.AdaLoraModel
diff --git a/docs/source/package_reference/adamss.md b/docs/source/package_reference/adamss.md
index 2ef4e550bc..fe3279b29e 100644
--- a/docs/source/package_reference/adamss.md
+++ b/docs/source/package_reference/adamss.md
@@ -22,13 +22,23 @@ The abstract from the paper is:
> We propose AdaMSS, an adaptive multi-subspace approach for parameter-efficient fine-tuning of large models. Unlike traditional parameterefficient fine-tuning methods that operate within a large single subspace of the network weights, AdaMSS leverages subspace segmentation to obtain multiple smaller subspaces and adaptively reduces the number of trainable parameters during training, ultimately updating only those associated with a small subset of subspaces most relevant to the target downstream task. By using the lowest-rank representation, AdaMSS achieves more compact expressiveness and finer tuning of the model parameters. Theoretical analyses demonstrate that AdaMSS has better generalization guarantee than LoRA, PiSSA, and other single-subspace low-rankbased methods. Extensive experiments across image classification, natural language understanding, and natural language generation tasks show that AdaMSS achieves comparable performance to full fine-tuning and outperforms other parameterefficient fine-tuning methods in most cases, all while requiring fewer trainable parameters. Notably, on the ViT-Large model, AdaMSS achieves 4.7% higher average accuracy than LoRA across seven tasks, using just 15.4% of the trainable parameters. On RoBERTa-Large, AdaMSS outperforms PiSSA by 7% in average accuracy across six tasks while reducing the number of trainable parameters by approximately 94.4%. These results demonstrate the effectiveness of AdaMSS in parameter-efficient fine-tuning. The code for AdaMSS is available at https: //github.com/jzheng20/AdaMSS.
-
AdaMSS currently has the following constraints:
- Only `nn.Linear` layers are supported.
- Requires scikit-learn for the KMeans clustering step.
If these constraints don't work for your use case, consider other methods instead.
+## Benchmark overview
+
+
+
+# API
+
## AdamssConfig
[[autodoc]] tuners.adamss.config.AdamssConfig
diff --git a/docs/source/package_reference/beft.md b/docs/source/package_reference/beft.md
index f3b29468d1..f7c5de4a39 100644
--- a/docs/source/package_reference/beft.md
+++ b/docs/source/package_reference/beft.md
@@ -21,7 +21,7 @@ rendered properly in your Markdown viewer.
BEFT currently has the following tradeoffs:
Pros:
-- BEFT requires far fewer parameters than LoRA, while maintaining competitive or superior performance across tasks in low-data regimes.
+- BEFT requires far fewer parameters than LoRA, while maintaining competitive or superior performance across tasks in low-data regimes.
Cons:
- In high-data regimes, BEFT may show limited effectiveness compared to LoRA and full-parameters fine-tuning.
@@ -32,10 +32,21 @@ The abstract from the paper is:
*Fine-tuning the bias terms of large language models (LLMs) has the potential to achieve unprecedented parameter efficiency while maintaining competitive performance, particularly in low-data regimes. However, the link between fine-tuning different bias terms (i.e., **b**
q, **b**
k, and **b**
v in the query, key, or value projections) and downstream performance remains largely unclear to date. In this paper, we investigate the link between fine-tuning **b**
q, **b**
k, and **b**
v with the performance of the downstream task. Our key finding is that directly fine-tuning **b**
v generally leads to higher downstream performance in low-data regimes, in comparison to **b**
q and **b**
k. We extensively evaluate this unique property across a wide range of LLMs spanning encoder-only and decoder-only architectures up to 6.7B parameters (including bias-free LLMs). Our results provide strong evidence for the effectiveness of directly fine-tuning **b**
v across various downstream tasks*.
+## Benchmark overview
+
+
+
+# API
+
## BeftConfig
[[autodoc]] tuners.beft.config.BeftConfig
## BeftModel
-[[autodoc]] tuners.beft.model.BeftModel
\ No newline at end of file
+[[autodoc]] tuners.beft.model.BeftModel
diff --git a/docs/source/package_reference/boft.md b/docs/source/package_reference/boft.md
index 48231fa9fd..5a31d0adf4 100644
--- a/docs/source/package_reference/boft.md
+++ b/docs/source/package_reference/boft.md
@@ -1,4 +1,4 @@
-
+
+# Weight-Decomposed Low-Rank Adaptation (DoRA)
+
+This technique decomposes the updates of the weights into two parts, magnitude and direction. Direction is handled by normal LoRA, whereas the magnitude is handled by a separate learnable parameter. This can improve the performance of LoRA, especially at low ranks. For more information on DoRA, see https://huggingface.co/papers/2402.09353.
+
+```py
+from peft import LoraConfig
+
+config = LoraConfig(use_dora=True, ...)
+```
+
+If parts of the model or the DoRA adapter are offloaded to CPU you can get a significant speedup at the cost of some temporary (ephemeral) VRAM overhead by using `ephemeral_gpu_offload=True` in `config.runtime_config`.
+
+```py
+from peft import LoraConfig, LoraRuntimeConfig
+
+config = LoraConfig(use_dora=True, runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=True), ...)
+```
+
+A `PeftModel` with a DoRA adapter can also be loaded with `ephemeral_gpu_offload=True` flag using the `from_pretrained` method as well as the `load_adapter` method.
+
+```py
+from peft import PeftModel
+
+model = PeftModel.from_pretrained(base_model, peft_model_id, ephemeral_gpu_offload=True)
+```
+
+## Optimization
+
+DoRA is optimized (computes faster and takes less memory) for models in the evaluation mode, or when dropout is set to 0. We reuse the
+base result at those times to get the speedup.
+Running [dora finetuning](https://github.com/huggingface/peft/blob/main/examples/dora_finetuning/dora_finetuning.py)
+with `CUDA_VISIBLE_DEVICES=0 ZE_AFFINITY_MASK=0 time python examples/dora_finetuning/dora_finetuning.py --quantize --lora_dropout 0 --batch_size 16 --eval_step 2 --use_dora` on a 4090 with gradient accumulation set to 2 and max step to 20 resulted with the following observations:
+
+| | Without Optimization | With Optimization |
+| :--: | :--: | :--: |
+| train runtime (sec) | 359.7298 | **279.2676** |
+| train samples per second | 1.779 | **2.292** |
+| train steps per second | 0.056 | **0.072** |
+
+Moreover, it is possible to further increase runtime performance of DoRA by using the [`DoraCaching`] helper context. This requires the model to be in `eval` mode:
+
+```py
+from peft.helpers import DoraCaching
+
+model.eval()
+with DoraCaching():
+ output = model(inputs)
+```
+
+For [`meta-llama/Llama-3.1-8B`](https://huggingface.co/meta-llama/Llama-3.1-8B), the [DoRA caching benchmark script](https://github.com/huggingface/peft/blob/main/examples/dora_finetuning/dora-caching.py) shows that, compared to LoRA:
+
+- DoRA without caching requires 139% more time
+- DoRA without caching requires 4% more memory
+- DoRA with caching requires 17% more time
+- DoRA with caching requires 41% more memory
+
+Caching can thus make inference with DoRA significantly faster but it also requires signficantly more memory. Ideally, if the use case allows it, just merge the DoRA adapter to avoid both memory and runtime overhead.
+
+## Caveats
+
+- DoRA only supports embedding, linear, and Conv2d layers at the moment.
+- DoRA introduces a bigger overhead than pure LoRA, so it is recommended to merge weights for inference, see [`LoraModel.merge_and_unload`].
+- DoRA should work with weights quantized with bitsandbytes ("QDoRA"). However, issues have been reported when using QDoRA with DeepSpeed Zero2.
+
diff --git a/docs/source/package_reference/lora_variant_monteclora.md b/docs/source/package_reference/lora_variant_monteclora.md
new file mode 100644
index 0000000000..bc6a63b9b2
--- /dev/null
+++ b/docs/source/package_reference/lora_variant_monteclora.md
@@ -0,0 +1,51 @@
+# MonteCLoRA (Monte Carlo Low-Rank Adaptation)
+
+MonteCLoRA wraps a standard LoRA adapter with a small variational module that draws Monte Carlo samples of stochastic perturbations on top of the LoRA `A` matrix during training. Concretely, it learns variational parameters (a Wishart-based covariance, a per-sample multivariate-normal noise term, and a Dirichlet weighting over the samples) and adds the resulting averaged perturbation to `lora_A` at every forward pass. A KL-divergence + entropy term is added to the training loss to keep these variational parameters anchored to a sensible prior. At inference time the sampler is disabled and MonteCLoRA behaves exactly like a regular LoRA adapter, so there is **no extra inference cost or extra parameters to merge**. For the full method see https://huggingface.co/papers/2411.04358.
+
+You may want to consider MonteCLoRA when:
+
+- You are fine-tuning on a small or noisy dataset and want stronger regularization than vanilla LoRA. The Monte Carlo averaging and the KL term together act as a Bayesian-style regularizer.
+- You want better uncertainty calibration / robustness from your adapter without paying extra cost at inference time (the variational machinery is training-only).
+- Vanilla LoRA is overfitting and lowering `r` or increasing `lora_dropout` is not enough.
+
+You probably do *not* need MonteCLoRA when you have a large, clean dataset and vanilla LoRA already trains stably — in that regime the extra variational parameters mostly add training overhead without much benefit.
+
+To enable MonteCLoRA, pass a `MontecloraConfig` to `LoraConfig`:
+
+```py
+from peft import LoraConfig, MontecloraConfig
+
+monteclora_config = MontecloraConfig(
+ num_samples=8, # number of Monte Carlo samples per forward pass
+ sample_scaler=1e-4, # magnitude of the variational perturbation
+ kl_loss_weight=1e-5, # weight of the KL term added to the training loss
+)
+config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ monteclora_config=monteclora_config,
+)
+```
+
+During training you must add the variational regularization loss to the task loss. The simplest way is to call [`LoraModel._get_monteclora_loss`] on the underlying `LoraModel`:
+
+```py
+task_loss = ... # standard loss returned by your model
+monteclora_loss = model._get_monteclora_loss() # 0.0 if MonteCLoRA is not used
+total_loss = task_loss + monteclora_loss
+total_loss.backward()
+```
+
+If you train with the HF `Trainer`, you can simply mix in [`peft.helpers.MontecloraTrainerMixin`] which does this for you in `compute_loss`:
+
+```py
+from transformers import Trainer
+from peft.helpers import MontecloraTrainerMixin
+
+
+class MontecloraTrainer(MontecloraTrainerMixin, Trainer):
+ pass
+```
+
+A complete working example is available at [`examples/monteclora_finetuning`](https://github.com/huggingface/peft/tree/main/examples/monteclora_finetuning).
diff --git a/docs/source/package_reference/lora_variant_velora.md b/docs/source/package_reference/lora_variant_velora.md
new file mode 100644
index 0000000000..8658108cd4
--- /dev/null
+++ b/docs/source/package_reference/lora_variant_velora.md
@@ -0,0 +1,49 @@
+
+
+### VeLoRA
+
+[VeLoRA](https://huggingface.co/papers/2405.17991) is a LoRA variant that reduces training memory by compressing the activations saved for the LoRA in the forward pass and then reconstructing them in the backwards pass to implement the update rules. In PEFT, VeLoRA is configured as a LoRA variant through the `velora_config` argument on [`LoraConfig`].
+
+```py
+from peft import LoraConfig, VeloraConfig
+
+config = LoraConfig(
+ target_modules=["q_proj", "v_proj"],
+ velora_config=VeloraConfig(
+ num_groups=64,
+ scale=0.2,
+ init_type="batch_average",
+ ),
+)
+```
+
+VeLoRA is applied to every LoRA layer selected by `target_modules`. `num_groups` controls how the input activation depth is split before compression. If the activation depth is not evenly divisible by `num_groups`, VeLoRA pads the grouped representation internally and removes the padding after reconstruction. `scale` rescales the reconstructed activations during the backward pass, and `init_type` chooses how the projection is initialized.
+
+Use `batch_average_once` to initialize the projection from the first training batch, `batch_average` to update it from every training forward pass, or `random` to initialize it immediately from a random normalized vector.
+
+Below are some results with the [MetaMathQA benchmark](https://github.com/huggingface/peft/tree/main/method_comparison/MetaMathQA).
+
+| Variant | Training Loss | Max Memory (GiB) | Tokens/sec |
+|---|---:|---:|---:|
+| LoRA | 0.5427 | 27.69 | 2366.2 |
+| LoRA + GC | 0.5426 | 13.17 | 1671.8 |
+| LoRA+VeLoRA | 0.5427 | 19.94 | 2057.6 |
+
+#### Caveats
+
+- VeLoRA is currently supported on standard LoRA linear layers only.
+
diff --git a/docs/source/package_reference/miss.md b/docs/source/package_reference/miss.md
index f8324ee4d3..c2c321fc48 100644
--- a/docs/source/package_reference/miss.md
+++ b/docs/source/package_reference/miss.md
@@ -22,6 +22,15 @@ The abstract from the paper is:
*Parameter-Efficient Fine-Tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), effectively reduce the number of trainable parameters in Large Language Models (LLMs). However, as model scales continue to grow, the demand for computational resources remains a significant challenge. Existing LoRA variants often struggle to strike an optimal balance between adaptability (model performance and convergence speed) and efficiency (computational overhead, memory usage, and initialization time). This paper introduces MiSS (Matrix Shard Sharing), a novel PEFT approach that addresses this trade-off through a simple shard-sharing mechanism. MiSS leverages the insight that a low-rank adaptation can be achieved by decomposing the weight matrix into multiple fragment matrices and utilizing a shared, trainable common fragment. This method constructs the low-rank update matrix through the replication of these shared, partitioned shards. We also propose a hardware-efficient and broadly applicable implementation for MiSS. Extensive experiments conducted on a range of tasks, alongside a systematic analysis of computational performance, demonstrate MiSS's superiority. The results show that MiSS significantly outperforms standard LoRA and its prominent variants in both model performance metrics and computational efficiency, including initialization speed and training throughput. By effectively balancing expressive power and resource utilization, MiSS offers a compelling solution for efficiently adapting large-scale models.*
+## Benchmark overview
+
+
+
## When to use MiSS
MiSS is a good choice when:
@@ -82,10 +91,12 @@ model.print_trainable_parameters()
For a full fine-tuning example including training and inference, see the [MiSS fine-tuning example](https://github.com/huggingface/peft/tree/main/examples/miss_finetuning).
+# API
+
## MissConfig
[[autodoc]] tuners.miss.config.MissConfig
## MissModel
-[[autodoc]] tuners.miss.model.MissModel
\ No newline at end of file
+[[autodoc]] tuners.miss.model.MissModel
diff --git a/docs/source/package_reference/multitask_prompt_tuning.md b/docs/source/package_reference/multitask_prompt_tuning.md
index 119739a3dc..ad5efa9103 100644
--- a/docs/source/package_reference/multitask_prompt_tuning.md
+++ b/docs/source/package_reference/multitask_prompt_tuning.md
@@ -22,10 +22,34 @@ The abstract from the paper is:
*Prompt tuning, in which a base pretrained model is adapted to each task via conditioning on learned prompt vectors, has emerged as a promising approach for efficiently adapting large language models to multiple downstream tasks. However, existing methods typically learn soft prompt vectors from scratch, and it has not been clear how to exploit the rich cross-task knowledge with prompt vectors in a multitask learning setting. We propose multitask prompt tuning (MPT), which first learns a single transferable prompt by distilling knowledge from multiple task-specific source prompts. We then learn multiplicative low rank updates to this shared prompt to efficiently adapt it to each downstream target task. Extensive experiments on 23 NLP datasets demonstrate that our proposed approach outperforms the state-of-the-art methods, including the full finetuning baseline in some cases, despite only tuning 0.035% as many task-specific parameters*.
+
+
+
+
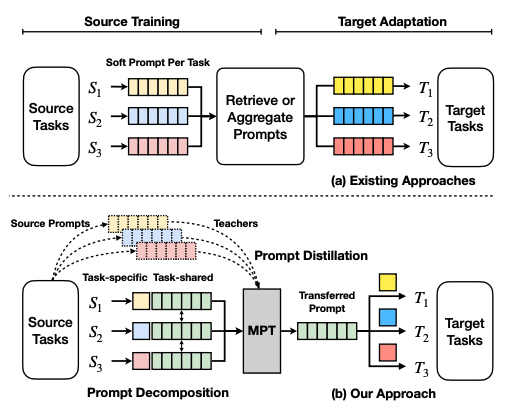
Multitask prompt tuning enables parameter-efficient transfer learning.
+
+MPT consists of two stages:
+
+1. source training - for each task, its soft prompt is decomposed into task-specific vectors. The task-specific vectors are multiplied together to form another matrix W, and the Hadamard product is used between W and a shared prompt matrix P to generate a task-specific prompt matrix. The task-specific prompts are distilled into a single prompt matrix that is shared across all tasks. This prompt is trained with multitask training.
+2. target adaptation - to adapt the single prompt for a target task, a target prompt is initialized and expressed as the Hadamard product of the shared prompt matrix and the task-specific low-rank prompt matrix.
+
+
+
+
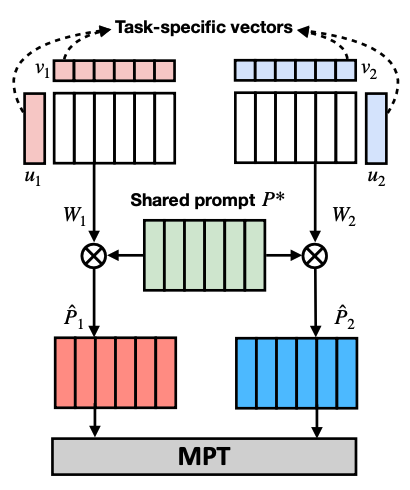
+
Prompt decomposition.
+
+## Benchmark overview
+
+There is no benchmark for this method yet. Feel free to contribute an experiment
+configuration but make sure to first create an issue
+[here](https://github.com/huggingface/peft/issues).
+
+
+# API
+
## MultitaskPromptTuningConfig
[[autodoc]] tuners.multitask_prompt_tuning.config.MultitaskPromptTuningConfig
## MultitaskPromptEmbedding
-[[autodoc]] tuners.multitask_prompt_tuning.model.MultitaskPromptEmbedding
\ No newline at end of file
+[[autodoc]] tuners.multitask_prompt_tuning.model.MultitaskPromptEmbedding
diff --git a/docs/source/package_reference/oft.md b/docs/source/package_reference/oft.md
index 63909b202b..fcf3ee9050 100644
--- a/docs/source/package_reference/oft.md
+++ b/docs/source/package_reference/oft.md
@@ -16,12 +16,79 @@ rendered properly in your Markdown viewer.
# OFT
-[Orthogonal Finetuning (OFT)](https://hf.co/papers/2306.07280) is a method developed for adapting text-to-image diffusion models. It works by reparameterizing the pretrained weight matrices with its orthogonal matrix to preserve information in the pretrained model. To reduce the number of parameters, OFT introduces a block-diagonal structure in the orthogonal matrix.
+
+
+
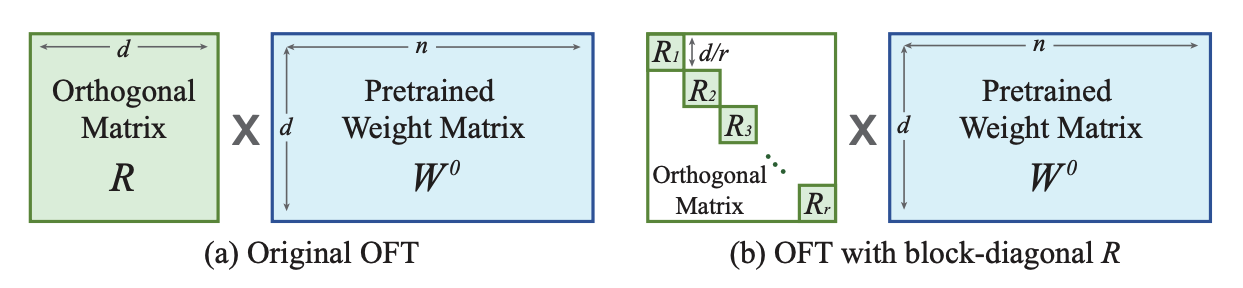
+
Controlling Text-to-Image Diffusion by Orthogonal Finetuning
+
+[Orthogonal Finetuning (OFT)](https://hf.co/papers/2306.07280) and [OFTv2](https://huggingface.co/papers/2506.19847) is a method developed for adapting text-to-image diffusion models. It works by reparameterizing the pretrained weight matrices with its orthogonal matrix to preserve information in the pretrained model. To reduce the number of parameters, OFT introduces a block-diagonal structure in the orthogonal matrix. The method primarily focuses on preserving a pretrained model's generative performance in the finetuned model. It tries to maintain the same cosine similarity ([hyperspherical energy](https://huggingface.co/papers/1805.09298)) between all pairwise neurons in a layer because this better captures the semantic information among neurons. This means OFT is more capable at preserving the subject and it is better for controllable generation (similar to [ControlNet](https://huggingface.co/docs/diffusers/using-diffusers/controlnet)).
The abstract from the paper is:
*Large text-to-image diffusion models have impressive capabilities in generating photorealistic images from text prompts. How to effectively guide or control these powerful models to perform different downstream tasks becomes an important open problem. To tackle this challenge, we introduce a principled finetuning method -- Orthogonal Finetuning (OFT), for adapting text-to-image diffusion models to downstream tasks. Unlike existing methods, OFT can provably preserve hyperspherical energy which characterizes the pairwise neuron relationship on the unit hypersphere. We find that this property is crucial for preserving the semantic generation ability of text-to-image diffusion models. To improve finetuning stability, we further propose Constrained Orthogonal Finetuning (COFT) which imposes an additional radius constraint to the hypersphere. Specifically, we consider two important finetuning text-to-image tasks: subject-driven generation where the goal is to generate subject-specific images given a few images of a subject and a text prompt, and controllable generation where the goal is to enable the model to take in additional control signals. We empirically show that our OFT framework outperforms existing methods in generation quality and convergence speed*.
+OFT preserves the hyperspherical energy by learning an orthogonal transformation for neurons to keep the cosine similarity between them unchanged, potentially leading to less forgetting of previous learnt knowledge. In practice, this means taking the matrix product of an orthogonal matrix with the pretrained weight matrix. However, to be parameter-efficient, the orthogonal matrix is represented as a block-diagonal matrix with rank `r` blocks. Whereas LoRA reduces the number of trainable parameters with low-rank structures, OFT reduces the number of trainable parameters with a sparse block-diagonal matrix structure.
+
+## Benchmark overview
+
+
+
+## Merge OFT weights into the base model
+
+Similar to LoRA, the weights learned by OFT can be integrated into the pretrained weight matrices using the [`~OFTModel.merge_and_unload()` function. This function merges the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.
+
+## OFT Example Usage
+
+For using OFT for quantized finetuning with [TRL](https://github.com/huggingface/trl) for `SFT`, `PPO`, or `DPO` fine-tuning, follow the following outline:
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+from trl import SFTTrainer
+from peft import OFTConfig
+
+if use_quantization:
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_storage=torch.bfloat16,
+ )
+
+model = AutoModelForCausalLM.from_pretrained(
+ "model_name",
+ quantization_config=bnb_config
+)
+tokenizer = AutoTokenizer.from_pretrained("model_name")
+
+# Configure OFT
+peft_config = OFTConfig(
+ oft_block_size=32,
+ use_cayley_neumann=True,
+ target_modules="all-linear",
+ bias="none",
+ task_type="CAUSAL_LM"
+)
+
+trainer = SFTTrainer(
+ model=model,
+ train_dataset=ds['train'],
+ peft_config=peft_config,
+ processing_class=tokenizer,
+ args=training_arguments,
+ data_collator=collator,
+)
+
+trainer.train()
+```
+
+# API
+
## OFTConfig
[[autodoc]] tuners.oft.config.OFTConfig
diff --git a/docs/source/package_reference/osf.md b/docs/source/package_reference/osf.md
index 266138589b..6cd43fad7f 100644
--- a/docs/source/package_reference/osf.md
+++ b/docs/source/package_reference/osf.md
@@ -105,7 +105,7 @@ config = OSFConfig(
"gate_proj": 4 # Lower rank for gate projection
}
)
-
+
# Fractional preserved rank is supported (interpreted per-target as fraction * min_dim)
config = OSFConfig(effective_rank=0.8) # preserve 80% of min_dim; train remaining 20%
config = OSFConfig(rank_pattern={"q_proj": 0.5}) # preserve 50% on q_proj, others use global/default
@@ -144,7 +144,7 @@ train_task(model, task_3_data)
When training on a known sequence of n tasks, one effective strategy is to progressively allocate model capacity to balance learning new tasks while preserving previous knowledge:
- **Task 1**: Use full capacity (train everything)
-- **Task 2**: Freeze 1/n of model capacity, train remaining (n-1)/n capacity
+- **Task 2**: Freeze 1/n of model capacity, train remaining (n-1)/n capacity
- **Task 3**: Freeze 2/n of model capacity, train remaining (n-2)/n capacity
- **Task n**: Freeze (n-1)/n of model capacity, use 1/n capacity for final task
@@ -222,6 +222,17 @@ optimizer = torch.optim.AdamW([
], lr=1e-4)
```
+## Benchmark overview
+
+
+
+# API
+
## OSFConfig
[[autodoc]] tuners.osf.config.OSFConfig
diff --git a/docs/source/package_reference/p_tuning.md b/docs/source/package_reference/p_tuning.md
index a35f7244c3..d529448dae 100644
--- a/docs/source/package_reference/p_tuning.md
+++ b/docs/source/package_reference/p_tuning.md
@@ -16,16 +16,55 @@ rendered properly in your Markdown viewer.
# P-tuning
-[P-tuning](https://hf.co/papers/2103.10385) adds trainable prompt embeddings to the input that is optimized by a prompt encoder to find a better prompt, eliminating the need to manually design prompts. The prompt tokens can be added anywhere in the input sequence, and p-tuning also introduces anchor tokens for improving performance.
+
+
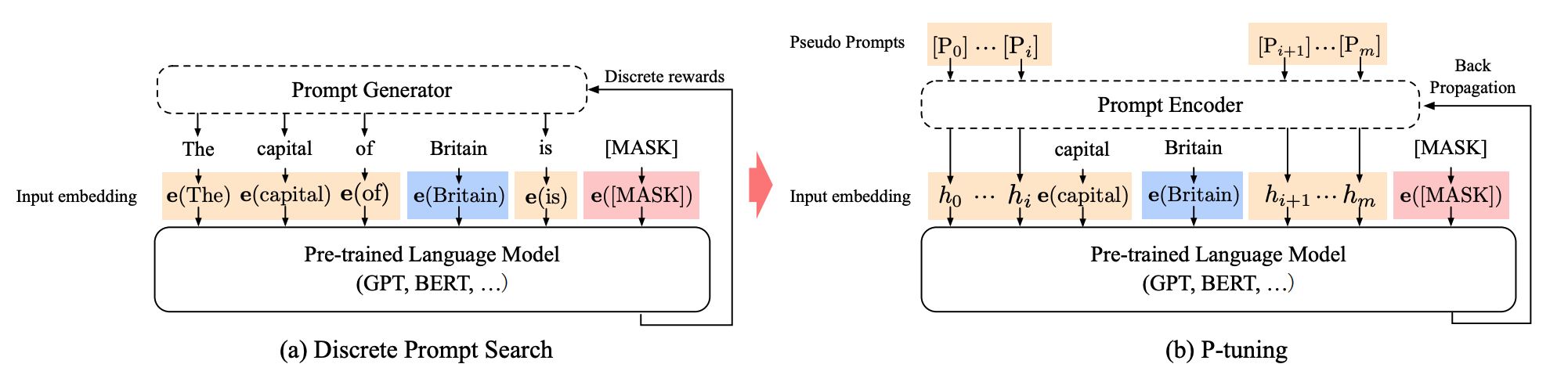
+
+
Prompt tokens can be inserted anywhere in the input sequence, and they are optimized by a prompt encoder (image source).
+
+[P-tuning](https://hf.co/papers/2103.10385) is designed for natural language understanding (NLU) tasks and all language models.
The abstract from the paper is:
*While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), we show that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning -- which employs trainable continuous prompt embeddings. On the knowledge probing (LAMA) benchmark, the best GPT recovers 64\% (P@1) of world knowledge without any additional text provided during test time, which substantially improves the previous best by 20+ percentage points. On the SuperGlue benchmark, GPTs achieve comparable and sometimes better performance to similar-sized BERTs in supervised learning. Importantly, we find that P-tuning also improves BERTs' performance in both few-shot and supervised settings while largely reducing the need for prompt engineering. Consequently, P-tuning outperforms the state-of-the-art approaches on the few-shot SuperGlue benchmark.*.
+The method adds trainable prompt embeddings to the input that is optimized by a prompt encoder to find a better prompt, eliminating the need to manually design prompts. The prompt tokens can be added anywhere in the input sequence, and p-tuning also introduces anchor tokens for improving performance. A prompt encoder (a bidirectional long-short term memory network or LSTM) is used to optimize the prompt parameters. Unlike prefix tuning:
+
+- the prompt tokens can be inserted anywhere in the input sequence, and it isn't restricted to only the beginning
+- the prompt tokens are only added to the input instead of adding them to every layer of the model
+- introducing *anchor* tokens can improve performance because they indicate characteristics of a component in the input sequence
+
+The paper's results suggest that P-tuning is more efficient than manually crafting prompts, and it enables GPT-like models to compete with BERT-like models on NLU tasks.
+
+## Usage
+
+Create a [`PromptEncoderConfig`] with the task type, the number of virtual tokens to add and learn, and the hidden size of the encoder for learning the prompt parameters.
+
+```py
+from peft import PromptEncoderConfig, get_peft_model
+
+peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
+model = get_peft_model(model, peft_config)
+model.print_trainable_parameters()
+"trainable params: 300,288 || all params: 559,514,880 || trainable%: 0.05366935013417338"
+```
+
+## Benchmark overview
+
+
+
+
+# API
+
## PromptEncoderConfig
[[autodoc]] tuners.p_tuning.config.PromptEncoderConfig
## PromptEncoder
-[[autodoc]] tuners.p_tuning.model.PromptEncoder
\ No newline at end of file
+[[autodoc]] tuners.p_tuning.model.PromptEncoder
+
diff --git a/docs/source/package_reference/peanut.md b/docs/source/package_reference/peanut.md
index c40e95fb1e..f986d87897 100644
--- a/docs/source/package_reference/peanut.md
+++ b/docs/source/package_reference/peanut.md
@@ -43,6 +43,17 @@ The abstract from the paper is:
> Fine-tuning large pre-trained foundation models often yields excellent downstream performance but is prohibitively expensive when updating all parameters. Parameter-efficient fine-tuning (PEFT) methods such as LoRA alleviate this by introducing lightweight update modules, yet they commonly rely on weight-agnostic linear approximations, limiting their expressiveness. In this work, we propose PEANuT, a novel PEFT framework that introduces weight-aware neural tweakers, compact neural modules that generate task-adaptive updates conditioned on frozen pre-trained weights. PEANuT provides a flexible yet efficient way to capture complex update patterns without full model tuning. We theoretically show that PEANuT achieves equivalent or greater expressivity than existing linear PEFT methods with comparable or fewer parameters. Extensive experiments across four benchmarks with over twenty datasets demonstrate that PEANuT consistently outperforms strong baselines in both NLP and vision tasks, while maintaining low computational overhead.
+## Benchmark overview
+
+
+
+# API
+
## PeanutConfig
[[autodoc]] tuners.peanut.config.PeanutConfig
diff --git a/docs/source/package_reference/poly.md b/docs/source/package_reference/poly.md
index a4cf28ce56..3dd2a20c9b 100644
--- a/docs/source/package_reference/poly.md
+++ b/docs/source/package_reference/poly.md
@@ -35,6 +35,10 @@ The abstract from the paper is:
+In case you want to try out routing without training first, you can check out the [Arrow LoRA variant](./lora#Arrow).
+
+# API
+
## PolyConfig
[[autodoc]] tuners.poly.config.PolyConfig
diff --git a/docs/source/package_reference/prefix_tuning.md b/docs/source/package_reference/prefix_tuning.md
index 9d722da219..06ec4c5245 100644
--- a/docs/source/package_reference/prefix_tuning.md
+++ b/docs/source/package_reference/prefix_tuning.md
@@ -16,14 +16,40 @@ rendered properly in your Markdown viewer.
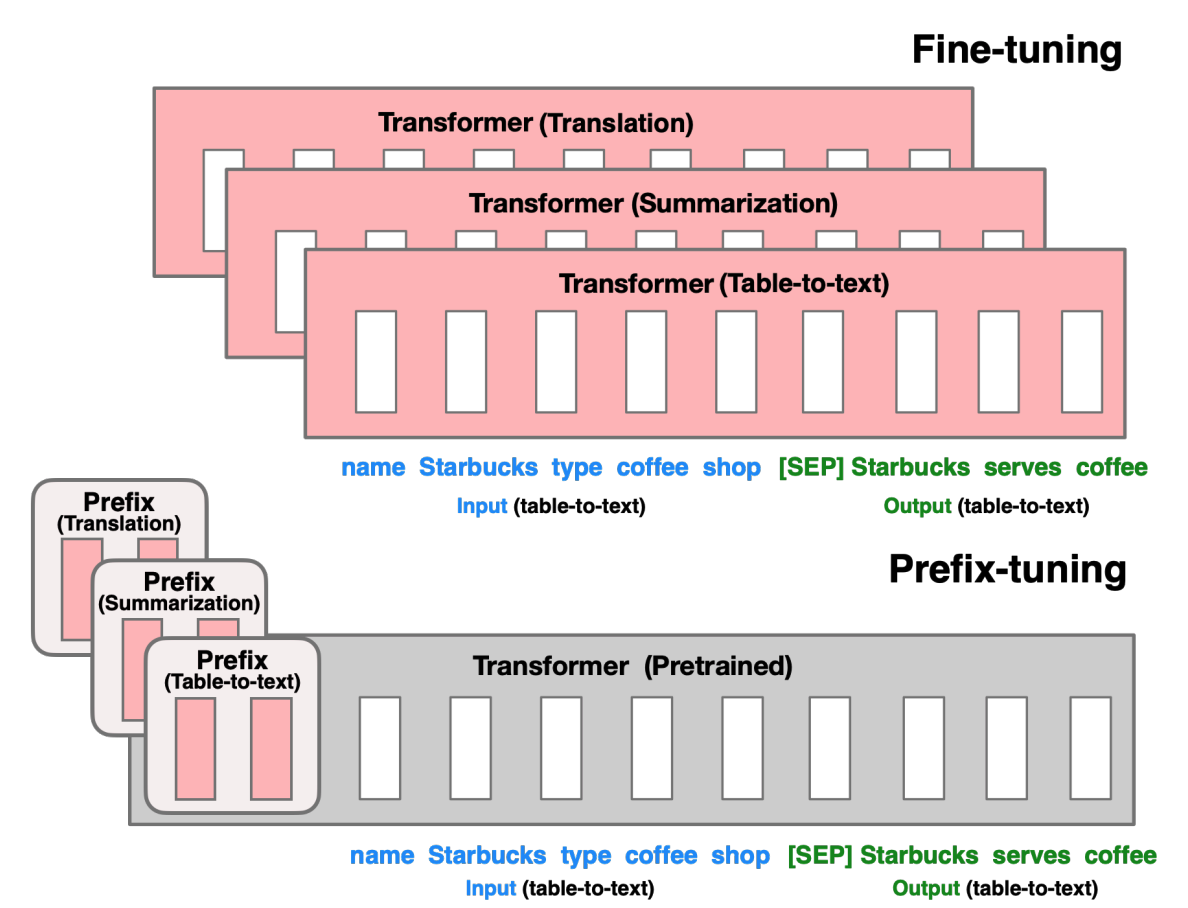
# Prefix tuning
+
+
+
+
Optimize the prefix parameters for each task (image source).
+
[Prefix tuning](https://hf.co/papers/2101.00190) prefixes a series of task-specific vectors to the input sequence that can be learned while keeping the pretrained model frozen. The prefix parameters are inserted in all of the model layers.
+The abstract from the paper is:
+
+*Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen, but optimizes a small continuous task-specific vector (called the prefix). Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were "virtual tokens". We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We find that by learning only 0.1\% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics unseen during training*.
+
**Note** For encoder-decoder models (seq2seq), the prefix is only applied to the decoder, which does not correspond to the paper specification (see e.g. Figure 2). Prefix tuning can still be fine-tuned on these model architectures but the performance could be sub-par; consider using other PEFT methods for encoder-decoder models.
-## Possible Initialization
+Prefix tuning is very similar to [prompt tuning](../package_reference/prompt_tuning). The main difference is that the prefix parameters are inserted in **all** of the model layers, whereas prompt tuning only adds the prompt parameters to the model input embeddings. The prefix parameters are also optimized by a separate feed-forward network (FFN) instead of training directly on the soft prompts because it causes instability and hurts performance. The FFN is discarded after updating the soft prompts.
+
+As a result, the authors found that prefix tuning demonstrates comparable performance to fully finetuning a model, despite having 1000x fewer parameters, and it performs even better in low-data settings.
+
+## Basic Usage
+
+Create a [`PrefixTuningConfig`] with the task type and number of virtual tokens to add and learn.
-By default, prefix tuning is randomly initialized. There's also the option to initialize the embeddings (or the
-projection thereof) to be close to a no-op (initialized to zero, it will still shift the probability mass a bit).
+```py
+from peft import PrefixTuningConfig, get_peft_model
+
+peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
+model = get_peft_model(model, peft_config)
+model.print_trainable_parameters()
+"trainable params: 983,040 || all params: 560,197,632 || trainable%: 0.1754809274167014"
+```
+
+## Possible Initializations
+
+By default, prefix tuning uses randomly initialized virtual tokens. There's also the option to initialize the vectors
+to be close to a no-op (initialized to zero, it will still shift the probability mass a bit).
This means that the KV-cache injected prefixes have less impact from the beginning and reduces the variance in training
performance.
@@ -42,12 +68,26 @@ tok = AutoTokenizer.from_pretrained("gpt2")
peft_cfg = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, prefix_projection=False)
model = get_peft_model(base, peft_cfg)
+initialize_kv_prefix_from_text(
+ model,
+ tok,
+ text="...a long context with at least num_virtual_tokens tokens...",
+ use_chat_template=False,
+)m peft import PrefixTuningConfig, get_peft_model, initialize_kv_prefix_from_text
+
+base = AutoModelForCausalLM.from_pretrained("gpt2")
+tok = AutoTokenizer.from_pretrained("gpt2")
+
+peft_cfg = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, prefix_projection=False)
+model = get_peft_model(base, peft_cfg)
+
initialize_kv_prefix_from_text(
model,
tok,
text="...a long context with at least num_virtual_tokens tokens...",
use_chat_template=False,
)
+
```
Make sure the text is long enough to produce at least `num_virtual_tokens` tokens, otherwise initialization will fail.
@@ -61,9 +101,18 @@ As a guideline:
* if it is not possible to use an initialization text or you want to quickly check if prefix tuning is viable at all,
use a zero init without projection
-The abstract from the paper is:
-*Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen, but optimizes a small continuous task-specific vector (called the prefix). Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were "virtual tokens". We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We find that by learning only 0.1\% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics unseen during training*.
+## Benchmark overview
+
+
+
+
+# API
## PrefixTuningConfig
diff --git a/docs/source/package_reference/prompt_tuning.md b/docs/source/package_reference/prompt_tuning.md
index 61dbb6a2e9..e03be042fa 100644
--- a/docs/source/package_reference/prompt_tuning.md
+++ b/docs/source/package_reference/prompt_tuning.md
@@ -16,16 +16,59 @@ rendered properly in your Markdown viewer.
# Prompt tuning
-[Prompt tuning](https://hf.co/papers/2104.08691) adds task-specific prompts to the input, and these prompt parameters are updated independently of the pretrained model parameters which are frozen.
+
+
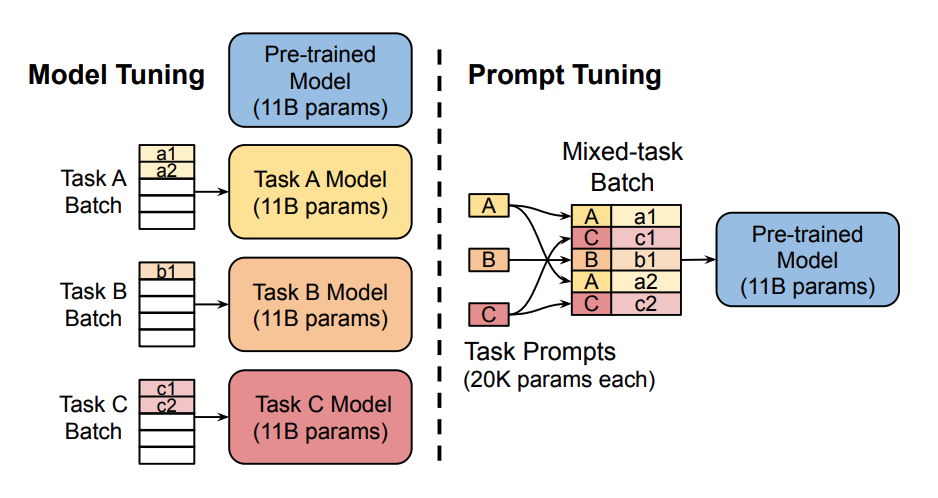
+
+
Only train and store a significantly smaller set of task-specific prompt parameters (image source).
+
+[Prompt tuning](https://hf.co/papers/2104.08691) adds a task-specific, virtual prompt to the input that consists of trainable vectors in the embedding space. The virtual token parameters are updated independently of the pretrained model parameters which are frozen.
The abstract from the paper is:
*In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signal from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3's "few-shot" learning by a large margin. More remarkably, through ablations on model size using T5, we show that prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method "closes the gap" and matches the strong performance of model tuning (where all model weights are tuned). This finding is especially relevant in that large models are costly to share and serve, and the ability to reuse one frozen model for multiple downstream tasks can ease this burden. Our method can be seen as a simplification of the recently proposed "prefix tuning" of Li and Liang (2021), and we provide a comparison to this and other similar approaches. Finally, we show that conditioning a frozen model with soft prompts confers benefits in robustness to domain transfer, as compared to full model tuning*.
+In contrast to [prefix tuning](../package_reference/prefix_tuning), only the
+input of the first layer receives the virtual tokens.
+
+## Usage
+
+There are two decisions to take: how many virtual tokens are added to the
+input of the model (`num_virtual_tokens`) - this will define how many
+trainable parameters there will be - and how these tokens are initialized.
+
+Create a [`PromptTuningConfig`] with the task type, the initial prompt tuning text to train the model with, the number of virtual tokens to add and learn, and a tokenizer.
+
+```py
+from peft import PromptTuningConfig, PromptTuningInit, get_peft_model
+
+prompt_tuning_init_text = "Classify if the tweet is a complaint or no complaint.\n"
+peft_config = PromptTuningConfig(
+ task_type="CAUSAL_LM",
+ prompt_tuning_init=PromptTuningInit.TEXT,
+ num_virtual_tokens=len(tokenizer(prompt_tuning_init_text)["input_ids"]),
+ prompt_tuning_init_text=prompt_tuning_init_text,
+ tokenizer_name_or_path="bigscience/bloomz-560m",
+)
+model = get_peft_model(model, peft_config)
+model.print_trainable_parameters()
+"trainable params: 8,192 || all params: 559,222,784 || trainable%: 0.0014648902430985358"
+```
+
+## Benchmark overview
+
+
+
+# API
+
## PromptTuningConfig
[[autodoc]] tuners.prompt_tuning.config.PromptTuningConfig
## PromptEmbedding
-[[autodoc]] tuners.prompt_tuning.model.PromptEmbedding
\ No newline at end of file
+[[autodoc]] tuners.prompt_tuning.model.PromptEmbedding
diff --git a/docs/source/package_reference/psoft.md b/docs/source/package_reference/psoft.md
index 4eea99a1cd..d5aaeed4d1 100644
--- a/docs/source/package_reference/psoft.md
+++ b/docs/source/package_reference/psoft.md
@@ -67,7 +67,7 @@ model = AutoModelForCausalLM.from_pretrained(model_id)
# Configure PSOFT
config = PsoftConfig(
- r=32, # the dimension of trainable matrix R,
+ r=32, # the dimension of trainable matrix R,
psoft_alpha=32, # scaling factor (typically set to r in PSOFT),
target_modules=["q_proj", "v_proj"], # target attention projection layers
ab_svd_init="psoft_init", # principal subspace initialization
@@ -119,6 +119,16 @@ config = PsoftConfig(psoft_orth=True,psoft_mag_a=True,psoft_mag_b=True)
4. **SVD Initialization**: The `lowrank` option is more memory- and compute-efficient than `full`, making it more suitable for large models.
5. **Cayley–Neumann Approximation**: When the rank is large, enabling the Cayley–Neumann approximation can significantly improve computational efficiency, while the benefit is less pronounced for small ranks. In practice, a small number of Neumann series terms (typically `5`) usually provides a good balance between accuracy and efficiency.
+## Benchmark overview
+
+
+
+# API
## PsoftConfig
@@ -126,4 +136,4 @@ config = PsoftConfig(psoft_orth=True,psoft_mag_a=True,psoft_mag_b=True)
## PsoftModel
-[[autodoc]] tuners.psoft.model.PsoftModel
\ No newline at end of file
+[[autodoc]] tuners.psoft.model.PsoftModel
diff --git a/docs/source/package_reference/pvera.md b/docs/source/package_reference/pvera.md
index 6ea72c7d25..d0c6ca4e93 100644
--- a/docs/source/package_reference/pvera.md
+++ b/docs/source/package_reference/pvera.md
@@ -31,10 +31,21 @@ The abstract from the paper is:
> Large foundation models have emerged in the last years and are pushing performance boundaries for a variety of tasks. Training or even finetuning such models demands vast datasets and computational resources, which are often scarce and costly. Adaptation methods provide a computationally efficient solution to address these limitations by allowing such models to be finetuned on small amounts of data and computing power. This is achieved by appending new trainable modules to frozen backbones with only a fraction of the trainable parameters and fitting only these modules on novel tasks. Recently, the VeRA adapter was shown to excel in parameter-efficient adaptations by utilizing a pair of frozen random low-rank matrices shared across all layers. In this paper, we propose PVeRA, a probabilistic version of the VeRA adapter, which modifies the low-rank matrices of VeRA in a probabilistic manner. This modification naturally allows handling inherent ambiguities in the input and allows for different sampling configurations during training and testing. A comprehensive evaluation was performed on the VTAB-1k benchmark and seven adapters, with PVeRA outperforming VeRA and other adapters.
+## Benchmark overview
+
+
+
+# API
+
## PveraConfig
[[autodoc]] tuners.pvera.config.PveraConfig
## PveraModel
-[[autodoc]] tuners.pvera.model.PveraModel
\ No newline at end of file
+[[autodoc]] tuners.pvera.model.PveraModel
diff --git a/docs/source/package_reference/randlora.md b/docs/source/package_reference/randlora.md
index 930c400685..8140538423 100644
--- a/docs/source/package_reference/randlora.md
+++ b/docs/source/package_reference/randlora.md
@@ -14,14 +14,14 @@ rendered properly in your Markdown viewer.
-->
-# RandLora: Full-rank parameter-efficient fine-tuning of large models
+# RandLora: Full-rank parameter-efficient fine-tuning of large models
[RandLora](https://huggingface.co/papers/2502.00987) is a parameter-efficient fine-tuning technique that is similar to [LoRA](https://huggingface.co/papers/2106.09685) and [VeRA](https://huggingface.co/papers/2310.11454) but performs full rank updates to improve performance. RandLora can be particularly useful when adapting large model to hard tasks that require complex updates while preserving the parameter efficiency of LoRA. The full rank update of RandLora is achieved by linearly scaling random bases. The random bases are a collection of multiple low rank matrices such that the summation of their ranks if greater or equal to the full rank of the parameter matrices. The trainable parameters of RandLora are two diagonal matrices (vectors) that get multiplied with the right hand low rank random bases, in a similar way to VeRA's update. To maintain low memory usage, RandLora uses a custom function that prevents storing unnecessary bases in memory for backpropagation.
RandLora presents the noteworthy difference that contrary to other LoRA-like PEFT algorithm, increasing RandLora's random base ranks increases the amount of trainable parameters. Because number of bases x bases rank is constant in RandLora, reducing the rank will increase the number of random bases, hence the number of base-specific trainable diagonal bases.
Because reducing the rank of RandLora's random bases will increase their number, RandLora can become slower to train than LoRA for very small ranks where typically, ranks below 4 with result in a large training time increase. This does not affect inference though as the RandLora adapters can be merged into the pretrained weight matrices.
-RandLora additionally supports training with sparse, ternary random bases (only containing -1, 0 and 1). These bases are as described in [Bingham et al.](https://cs-people.bu.edu/evimaria/cs565/kdd-rp.pdf) and [Ping et al.](https://hastie.su.domains/Papers/Ping/KDD06_rp.pdf) and could theoretically be used to reduce compute needs by performing aggregations instead of matrix multiplications to create the weight update. This is not currently supported. Although it does not currently reduce compute, using sparse random bases in RandLora can reduce overfitting in some cases. For users intersted in using sparse ternary bases, the `sparse` option is recommended over the `very_sparse` one that can reduce perfromance.
+RandLora additionally supports training with sparse, ternary random bases (only containing -1, 0 and 1). These bases are as described in [Bingham et al.](https://cs-people.bu.edu/evimaria/cs565/kdd-rp.pdf) and [Ping et al.](https://hastie.su.domains/Papers/Ping/KDD06_rp.pdf) and could theoretically be used to reduce compute needs by performing aggregations instead of matrix multiplications to create the weight update. This is not currently supported. Although it does not currently reduce compute, using sparse random bases in RandLora can reduce overfitting in some cases. For users intersted in using sparse ternary bases, the `sparse` option is recommended over the `very_sparse` one that can reduce perfromance.
Similarly to VeRA, when saving the RandLora's parameters, it's possible to eschew storing the low rank matrices by setting `save_projection=False` on the `VeraConfig`. In that case, these matrices will be restored based on the fixed random seed from the `projection_prng_key` argument. This cuts down on the size of the checkpoint, but we cannot guarantee reproducibility on all devices and for all future versions of PyTorch. If you want to ensure reproducibility, set `save_projection=True` (which is the default).
@@ -36,6 +36,17 @@ The abstract from the paper is:
> Low-Rank Adaptation (LoRA) and its variants have shown impressive results in reducing the number of trainable parameters and memory requirements of large transformer networks while maintaining fine-tuning performance. The low-rank nature of the weight update inherently limits the representation power of fine-tuned models, however, thus potentially compromising performance on complex tasks. This raises a critical question: when a performance gap between LoRA and standard fine-tuning is observed, is it due to the reduced number of trainable parameters or the rank deficiency?
This paper aims to answer this question by introducing RandLora, a parameter-efficient method that performs full-rank updates using a learned linear combinations of low-rank, non-trainable random matrices. Our method limits the number of trainable parameters by restricting optimization to diagonal scaling matrices applied to the fixed random matrices. This allows us to effectively overcome the low-rank limitations while maintaining parameter and memory efficiency during training. Through extensive experimentation across vision, language, and vision-language benchmarks, we systematically evaluate the limitations of LoRA and existing random basis methods. Our findings reveal that full-rank updates are beneficial across vision and language tasks individually, and even more so for vision-language tasks, where RandLora significantly reduces---and sometimes eliminates---the performance gap between standard fine-tuning and LoRA, demonstrating its efficacy.
+## Benchmark overview
+
+
+
+# API
+
## RandLoraConfig
[[autodoc]] tuners.randlora.config.RandLoraConfig
diff --git a/docs/source/package_reference/road.md b/docs/source/package_reference/road.md
index fb951a91de..4a69c26008 100644
--- a/docs/source/package_reference/road.md
+++ b/docs/source/package_reference/road.md
@@ -20,7 +20,18 @@ rendered properly in your Markdown viewer.
Finetuning with RoAd typically requires higher learning rate compared to LoRA or similar methods, around 1e-3. Currently RoAd only supports linear layers and it can be used on models quantized with bitsandbytes (4-bit or 8-bit).
-For running inference with different RoAd adapters in the same batch see [Inference with different LoRA adapters in the same batch](../developer_guides/lora#inference-with-different-lora-adapters-in-the-same-batch).
+For running inference with different RoAd adapters in the same batch see [Inference with different LoRA adapters in the same batch](lora#inference-with-different-lora-adapters-in-the-same-batch).
+
+## Benchmark overview
+
+
+
+# API
## RoadConfig
diff --git a/docs/source/package_reference/shira.md b/docs/source/package_reference/shira.md
index cbd869ddb4..05d12dd263 100644
--- a/docs/source/package_reference/shira.md
+++ b/docs/source/package_reference/shira.md
@@ -26,6 +26,17 @@ The abstract from the paper is:
> Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models, adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model significantly outperforms LoRA while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library which trains at nearly the same speed as LoRA while consuming up to 16% lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases. To demonstrate rapid switching benefits during inference, we show that loading SHiRA on a base model can be 5x-16x faster than LoRA fusion on a CPU.
+## Benchmark overview
+
+
+
+# API
+
## ShiraConfig
[[autodoc]] tuners.shira.config.ShiraConfig
diff --git a/docs/source/package_reference/tinylora.md b/docs/source/package_reference/tinylora.md
index 3217951b1a..16bcaf2db7 100644
--- a/docs/source/package_reference/tinylora.md
+++ b/docs/source/package_reference/tinylora.md
@@ -32,6 +32,17 @@ The abstract from the paper is:
> Recent research has shown that language models can learn to reason, often via reinforcement learning. Some work even trains low-rank parameterizations for reasoning, but conventional LoRA cannot scale below the model dimension. We question whether even rank=1 LoRA is necessary for learning to reason and propose TinyLoRA, a method for scaling low-rank adapters to sizes as small as one parameter. Within our new parameterization, we are able to train the 8B parameter size of Qwen2.5 to 91% accuracy on GSM8K with only 13 trained parameters in bf16 (26 total bytes). We find this trend holds in general: we are able to recover 90% of performance improvements while training 1000x fewer parameters across a suite of more difficult learning-to-reason benchmarks such as AIME, AMC, and MATH500. Notably, we are only able to achieve such strong performance with RL: models trained using SFT require 100-1000x larger updates to reach the same performance.
+## Benchmark overview
+
+
+
+# API
+
## TinyLoraConfig
[[autodoc]] tuners.tinylora.config.TinyLoraConfig
diff --git a/docs/source/package_reference/trainable_tokens.md b/docs/source/package_reference/trainable_tokens.md
index adebde7357..42d22a3f74 100644
--- a/docs/source/package_reference/trainable_tokens.md
+++ b/docs/source/package_reference/trainable_tokens.md
@@ -31,7 +31,7 @@ these numbers a bit.
Note that this method does not add tokens for you, you have to add tokens to the tokenizer yourself and resize the
embedding matrix of the model accordingly. This method will only re-train the embeddings for the tokens you specify.
-This method can also be used in conjunction with LoRA layers! See [the LoRA developer guide](../developer_guides/lora#efficiently-train-tokens-alongside-lora).
+This method can also be used in conjunction with LoRA layers! See [the LoRA documentation](lora#efficiently-train-tokens-alongside-lora).
> [!TIP]
> Saving the model with [`~PeftModel.save_pretrained`] or retrieving the state dict using
@@ -40,6 +40,17 @@ This method can also be used in conjunction with LoRA layers! See [the LoRA deve
> `save_embedding_layers=False` when calling `save_pretrained`. This is safe to do as long as you don't modify the
> embedding matrix through other means as well, as such changes will be not tracked by trainable tokens.
+## Benchmark overview
+
+
+
+# API
+
## TrainableTokensConfig
[[autodoc]] tuners.trainable_tokens.config.TrainableTokensConfig
diff --git a/docs/source/package_reference/vblora.md b/docs/source/package_reference/vblora.md
index 02aaf10b87..5e791a950d 100644
--- a/docs/source/package_reference/vblora.md
+++ b/docs/source/package_reference/vblora.md
@@ -30,6 +30,17 @@ The abstract from the paper is:
- VB-LoRA has two sets of training parameters: vector bank parameters and logit parameters. In practice, we found that logit parameters require a higher learning rate, while vector bank parameters require a lower learning rate. When using the AdamW optimizer, typical learning rates are 0.01 for logits and 0.001 for vector bank parameters.
+## Benchmark overview
+
+
+
+# API
+
## VBLoRAConfig
[[autodoc]] tuners.vblora.config.VBLoRAConfig
diff --git a/docs/source/package_reference/vera.md b/docs/source/package_reference/vera.md
index f9ed281275..98f3f795db 100644
--- a/docs/source/package_reference/vera.md
+++ b/docs/source/package_reference/vera.md
@@ -30,6 +30,17 @@ The abstract from the paper is:
> Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which significantly reduces the number of trainable parameters compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, image classification tasks, and show its application in instruction-tuning of 7B and 13B language models.
+## Benchmark overview
+
+
+
+# API
+
## VeRAConfig
[[autodoc]] tuners.vera.config.VeraConfig
diff --git a/docs/source/package_reference/waveft.md b/docs/source/package_reference/waveft.md
index 29837bc774..434b25b6d6 100644
--- a/docs/source/package_reference/waveft.md
+++ b/docs/source/package_reference/waveft.md
@@ -26,6 +26,17 @@ The abstract from the paper is:
>Efficiently adapting large foundation models is critical, especially with tight compute and memory budgets. Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA offer limited granularity and effectiveness in few-parameter regimes. We propose Wavelet Fine-Tuning (WaveFT), a novel PEFT method that learns highly sparse updates in the wavelet domain of residual matrices. WaveFT allows precise control of trainable parameters, offering fine-grained capacity adjustment and excelling with remarkably low parameter count, potentially far fewer than LoRA’s minimum—ideal for extreme parameter-efficient scenarios. Evaluated on personalized text-to-image generation using Stable Diffusion XL as baseline, WaveFT significantly outperforms LoRA and other PEFT methods, especially at low parameter counts; achieving superior subject fidelity, prompt alignment, and image diversity.
+## Benchmark overview
+
+
+
+# API
+
## WaveFTConfig
[[autodoc]] tuners.waveft.config.WaveFTConfig
diff --git a/docs/source/package_reference/xlora.md b/docs/source/package_reference/xlora.md
index f4710ab6fa..0ebfb744d0 100644
--- a/docs/source/package_reference/xlora.md
+++ b/docs/source/package_reference/xlora.md
@@ -24,6 +24,10 @@ The below graphic demonstrates how the scalings change for different prompts for

+For each step, X-LoRA requires the base model to be run twice: first, to get hidden states without any LoRA adapters, and secondly, the hidden states are used to calculate scalings which are applied to the LoRA adapters and the model is run a second time. The output of the second run is the result of the model step.
+
+Ultimately, X-LoRA allows the model to reflect upon its knowledge because of the dual forward pass scheme, and dynamically reconfigure the architecture.
+
The abstract from the paper is:
*We report a mixture of expert strategy to create fine-tuned large language models using a deep layer-wise token-level approach based on low-rank adaptation (LoRA). Starting with a set of pre-trained LoRA adapters, our gating strategy uses the hidden states to dynamically mix adapted layers, allowing the resulting X-LoRA model to draw upon different capabilities and create never-before-used deep layer-wise combinations to solve tasks. The design is inspired by the biological principles of universality and diversity, where neural network building blocks are reused in different hierarchical manifestations. Hence, the X-LoRA model can be easily implemented for any existing large language model (LLM) without a need for modifications of the underlying structure. We develop a tailored X-LoRA model that offers scientific capabilities including forward/inverse analysis tasks and enhanced reasoning capability, focused on biomaterial analysis, protein mechanics and design. The impact of this work include access to readily expandable and adaptable models with strong domain knowledge and the capability to integrate across areas of knowledge. Featuring experts in biology, mathematics, reasoning, bio-inspired materials, mechanics and materials, chemistry, protein biophysics, mechanics and quantum-mechanics based molecular properties, we conduct a series of physics-focused case studies. We examine knowledge recall, protein mechanics forward/inverse tasks, protein design, adversarial agentic modeling including ontological knowledge graph construction, as well as molecular design. The model is capable not only of making quantitative predictions of nanomechanical properties of proteins or quantum mechanical molecular properties, but also reasons over the results and correctly predicts likely mechanisms that explain distinct molecular behaviors.*.
@@ -47,6 +51,8 @@ Please cite X-LoRA as:
}
```
+# API
+
## XLoraConfig
[[autodoc]] tuners.xlora.config.XLoraConfig
diff --git a/docs/source/quicktour.md b/docs/source/quicktour.md
index 1f0a0a27be..0fea7f268b 100644
--- a/docs/source/quicktour.md
+++ b/docs/source/quicktour.md
@@ -18,48 +18,88 @@ rendered properly in your Markdown viewer.
PEFT offers parameter-efficient methods for finetuning large pretrained models. The traditional paradigm is to finetune all of a model's parameters for each downstream task, but this is becoming exceedingly costly and impractical because of the enormous number of parameters in models today. Instead, it is more efficient to train a smaller number of prompt parameters or use a reparametrization method like low-rank adaptation (LoRA) to reduce the number of trainable parameters.
+
+
+ PEFT can be thought of as a framework for adding trainable parameters to arbitrary places in existing models ("base models"). Specific PEFT methods arrange the trainable parameters in certain ways or modify the training process to achieve fine-tuning performance comparable to training all parameters of the base model.
+
+
+
+
This quicktour will show you PEFT's main features and how you can train or run inference on large models that would typically be inaccessible on consumer devices.
-## Train
-Each PEFT method is defined by a [`PeftConfig`] class that stores all the important parameters for building a [`PeftModel`]. For example, to train with LoRA, load and create a [`LoraConfig`] class and specify the following parameters:
+## PEFT configuration and model
+
+For any PEFT method, you'll need to create a configuration which contains all the parameters that specify how the PEFT method should be applied, most importantly which layers of the existing model to target with trainable parameters. Once the configuration is setup, pass it to the [`~peft.get_peft_model`] function along with the base model to create a trainable [`PeftModel`].
+
+Let's use [LoRA](./package_reference/lora) as an example but only discuss common parameters - you might want to use one of the [many other PEFT methods](./methods/overview).
+The configuration usually entails this:
+
+- `target_modules`: which modules of the base model to adapt
+- `task_type` (default: `None`, see [available `TaskType`s](package_reference/peft_types#peft.TaskType)): the nature of the trained task; if provided may help to automatically save relevant layers alongside the adapter weights or warn you about incompatibilities
+- `inference_mode` (default: `False`): whether you're using the model for inference or not
-- `task_type`: the task to train for (sequence-to-sequence language modeling in this case)
-- `inference_mode`: whether you're using the model for inference or not
-- `r`: the dimension of the low-rank matrices
-- `lora_alpha`: the scaling factor for the low-rank matrices
-- `lora_dropout`: the dropout probability of the LoRA layers
+Depending on the PEFT method you choose you will add specific parameters that, for example, determine the size of the update matrices.
+Here's an example of a config you may encounter in the wild:
```python
from peft import LoraConfig, TaskType
-peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
+peft_config = LoraConfig(target_modules=["q_proj"], task_type=TaskType.CAUSAL_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
```
> [!TIP]
-> See the [`LoraConfig`] reference for more details about other parameters you can adjust, such as the modules to target or the bias type.
+> See the [configuration guide](guides/peft_model_config) for more details on how the PEFT configuration works under the hood.
-Once the [`LoraConfig`] is setup, create a [`PeftModel`] with the [`get_peft_model`] function. It takes a base model - which you can load from the Transformers library - and the [`LoraConfig`] containing the parameters for how to configure a model for training with LoRA.
+Once the [`LoraConfig`] is set up, create a [`PeftModel`] with the [`get_peft_model`] function. It takes a base model - which you can (but don't have to) load from the Transformers library - and the [`LoraConfig`] containing the parameters for how to configure a model for training with LoRA.
Load the base model you want to finetune.
```python
-from transformers import AutoModelForSeq2SeqLM
+from transformers import AutoModelForCausalLM
-model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/mt0-large")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B")
```
-Wrap the base model and `peft_config` with the [`get_peft_model`] function to create a [`PeftModel`]. To get a sense of the number of trainable parameters in your model, use the [`print_trainable_parameters`] method.
+Now wrap the base model and `peft_config` with the [`get_peft_model`] function to create a [`PeftModel`].
+
+
+
+
+ Wrapping means that PEFT replaces the targeted layers (here: all q_proj layers) with the adapter-specific layer for the target layer's type.
+ Since we're dealing with linear layers, it will be, in this case, a lora.Linear layer. Note that these changes are done in-place to
+ save memory, so your base model is now modified.
+
+
+ Note that we've only specified q_proj but in actuality we are targeting all model.layers[:].self_attn.q_proj layers. This is
+ because PEFT searches for matching suffixes by default. Pass a string with a regular expression if you want to target more complex layer patterns.
+
+
+
+
+
+
+
+
+
+ The base model's layer will be wrapped, retained and not trained while new, trainable weights are added and are combined.
+ How these new weights are structured and combined with the weights of the base model is a good portion of what sets
+ the different PEFT methods apart.
+
+
+
+
+To get a sense of the number of trainable parameters in your model, use the [`print_trainable_parameters`] method.
```python
from peft import get_peft_model
-model = get_peft_model(model, peft_config)
-model.print_trainable_parameters()
-"output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
+peft_model = get_peft_model(model, peft_config)
+peft_model.print_trainable_parameters()
+"output: trainable params: 524,288 || all params: 1,236,338,688 || trainable%: 0.0424"
```
-Out of [bigscience/mt0-large's](https://huggingface.co/bigscience/mt0-large) 1.2B parameters, you're only training 0.19% of them!
+Out of [meta-llama/Llama-3.2-1B's](https://huggingface.co/meta-llama/Llama-3.2-1B) 1B parameters, you're only training 0.04% of them!
That is it 🎉! Now you can train the model with the Transformers [`~transformers.Trainer`], Accelerate, or any custom PyTorch training loop.
@@ -67,7 +107,7 @@ For example, to train with the [`~transformers.Trainer`] class, setup a [`~trans
```py
training_args = TrainingArguments(
- output_dir="your-name/bigscience/mt0-large-lora",
+ output_dir="your-name/meta-llama/my-llama3.2-adapter",
learning_rate=1e-3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
@@ -83,11 +123,10 @@ Pass the model, training arguments, dataset, tokenizer, and any other necessary
```py
trainer = Trainer(
- model=model,
+ model=peft_model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
- processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
@@ -97,10 +136,10 @@ trainer.train()
### Save model
-After your model is finished training, you can save your model to a directory using the [`~transformers.PreTrainedModel.save_pretrained`] function.
+After your model is finished training, you can save your model to a directory using the [`~PeftModel.save_pretrained`] function.
```py
-model.save_pretrained("output_dir")
+peft_model.save_pretrained("output_dir")
```
You can also save your model to the Hub (make sure you're logged in to your Hugging Face account first) with the [`~transformers.PreTrainedModel.push_to_hub`] function.
@@ -109,7 +148,7 @@ You can also save your model to the Hub (make sure you're logged in to your Hugg
from huggingface_hub import notebook_login
notebook_login()
-model.push_to_hub("your-name/bigscience/mt0-large-lora")
+peft_model.push_to_hub("your-name/my-llama3.2-adapter")
```
Both methods only save the extra PEFT weights that were trained, meaning it is super efficient to store, transfer, and load. For example, this [facebook/opt-350m](https://huggingface.co/ybelkada/opt-350m-lora) model trained with LoRA only contains two files: `adapter_config.json` and `adapter_model.safetensors`. The `adapter_model.safetensors` file is just 6.3MB!
@@ -152,11 +191,35 @@ from peft import AutoPeftModel
model = AutoPeftModel.from_pretrained("smangrul/openai-whisper-large-v2-LORA-colab")
```
+## Multiple adapters
+
+PEFT supports installing multiple adapters (of the same kind, in this document this would be LoRA) on top of a base model. When you call `get_peft_model` there is only one adapter named `"default"` but you can add as many additional adapters by calling `peft_model.add_adapter(adapter_name=...)`.
+
+
+
+
+ This works because the wrapped layer actually has a unique set of trainable weights for each adapter name. Not every adapter is active and trainable by default.
+ You have to explicitly enable adapters by name before they are active. This allows you to quickly swap between adapters where task-specific knowledge is needed
+ or serve different use-cases on top of one model.
+
+
+
+
+
+Just remember to call `peft_model.set_adapter(
)` first to enable the adapter.
+
+Quick example:
+
+```py
+peft_model.add_adapter(adapter_name='new_adapter')
+peft_model.set_adapter('new_adapter')
+```
+
## Next steps
Now that you've seen how to train a model with one of the PEFT methods, we encourage you to try out some of the other methods like prompt tuning. The steps are very similar to the ones shown in the quicktour:
-1. prepare a [`PeftConfig`] for a PEFT method
+1. prepare a [`PeftConfig`] for a PEFT method, e.g. a [`LoraConfig`] or some other config (see the [method overview](methods/overview))
2. use the [`get_peft_model`] method to create a [`PeftModel`] from the configuration and base model
Then you can train it however you like! To load a PEFT model for inference, you can use the [`AutoPeftModel`] class.
diff --git a/docs/source/task_guides/ia3.md b/docs/source/task_guides/ia3.md
deleted file mode 100644
index c23145f897..0000000000
--- a/docs/source/task_guides/ia3.md
+++ /dev/null
@@ -1,235 +0,0 @@
-
-
-# IA3
-
-[IA3](../conceptual_guides/ia3) multiplies the model's activations (the keys and values in the self-attention and encoder-decoder attention blocks, and the intermediate activation of the position-wise feedforward network) by three learned vectors. This PEFT method introduces an even smaller number of trainable parameters than LoRA which introduces weight matrices instead of vectors. The original model's parameters are kept frozen and only these vectors are updated. As a result, it is faster, cheaper and more efficient to finetune for a new downstream task.
-
-This guide will show you how to train a sequence-to-sequence model with IA3 to *generate a sentiment* given some financial news.
-
-> [!TIP]
-> Some familiarity with the general process of training a sequence-to-sequence would be really helpful and allow you to focus on how to apply IA3. If you’re new, we recommend taking a look at the [Translation](https://huggingface.co/docs/transformers/tasks/translation) and [Summarization](https://huggingface.co/docs/transformers/tasks/summarization) guides first from the Transformers documentation. When you’re ready, come back and see how easy it is to drop PEFT in to your training!
-
-## Dataset
-
-You'll use the [zeroshot/twitter-financial-news-sentiment](https://huggingface.co/datasets/zeroshot/twitter-financial-news-sentiment) dataset. This dataset contains financial tweets labeled with sentiment (bearish, bullish, or neutral). Take a look at the [dataset viewer](https://huggingface.co/datasets/zeroshot/twitter-financial-news-sentiment/viewer) for a better idea of the data and sentences you'll be working with.
-
-Load the dataset with the [`~datasets.load_dataset`] function. This dataset only contains a train split, so use the [`~datasets.train_test_split`] function to create a train and validation split. Create a new `text_label` column so it is easier to understand what the `label` values `0`, `1`, and `2` mean.
-
-```py
-from datasets import load_dataset
-
-ds = load_dataset("zeroshot/twitter-financial-news-sentiment")
-ds = ds["train"].train_test_split(test_size=0.1)
-ds["validation"] = ds["test"]
-del ds["test"]
-
-classes = ds["train"].features["label"].names
-ds = ds.map(
- lambda x: {"text_label": [classes[label] for label in x["label"]]},
- batched=True,
- num_proc=1,
-)
-
-ds["train"][0]
-{'text': 'Morrisons reports first sales rise in four years',
- 'label': 1,
- 'text_label': 'bullish'}
-```
-
-Load a tokenizer and create a preprocessing function that:
-
-1. tokenizes the inputs, pads and truncates the sequence to the `max_length`
-2. apply the same tokenizer to the labels but with a shorter `max_length` that corresponds to the label
-3. mask the padding tokens
-
-```py
-from transformers import AutoTokenizer
-
-text_column = "text"
-label_column = "text_label"
-max_length = 128
-
-tokenizer = AutoTokenizer.from_pretrained("bigscience/mt0-large")
-
-def preprocess_function(examples):
- inputs = examples[text_column]
- targets = examples[label_column]
- model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
- labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")
- labels = labels["input_ids"]
- labels[labels == tokenizer.pad_token_id] = -100
- model_inputs["labels"] = labels
- return model_inputs
-```
-
-Use the [`~datasets.Dataset.map`] function to apply the preprocessing function to the entire dataset.
-
-```py
-processed_ds = ds.map(
- preprocess_function,
- batched=True,
- num_proc=1,
- remove_columns=ds["train"].column_names,
- load_from_cache_file=False,
- desc="Running tokenizer on dataset",
-)
-```
-
-Create a training and evaluation [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader), and set `pin_memory=True` to speed up data transfer to the accelerator during training if your dataset samples are on a CPU.
-
-```py
-from torch.utils.data import DataLoader
-from transformers import default_data_collator
-
-train_ds = processed_ds["train"]
-eval_ds = processed_ds["validation"]
-
-batch_size = 8
-
-train_dataloader = DataLoader(
- train_ds, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
-)
-eval_dataloader = DataLoader(eval_ds, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
-```
-
-## Model
-
-Now you can load a pretrained model to use as the base model for IA3. This guide uses the [bigscience/mt0-large](https://huggingface.co/bigscience/mt0-large) model, but you can use any sequence-to-sequence model you like.
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/mt0-large")
-```
-
-### PEFT configuration and model
-
-All PEFT methods need a configuration that contains and specifies all the parameters for how the PEFT method should be applied. Create an [`IA3Config`] with the task type and set the inference mode to `False`. You can find additional parameters for this configuration in the [API reference](../package_reference/ia3#ia3config).
-
-> [!TIP]
-> Call the [`~PeftModel.print_trainable_parameters`] method to compare the number of trainable parameters of [`PeftModel`] versus the number of parameters in the base model!
-
-Once the configuration is setup, pass it to the [`get_peft_model`] function along with the base model to create a trainable [`PeftModel`].
-
-```py
-from peft import IA3Config, get_peft_model
-
-peft_config = IA3Config(task_type="SEQ_2_SEQ_LM")
-model = get_peft_model(model, peft_config)
-model.print_trainable_parameters()
-"trainable params: 282,624 || all params: 1,229,863,936 || trainable%: 0.022980103060766553"
-```
-
-### Training
-
-Set up an optimizer and learning rate scheduler.
-
-```py
-import torch
-from transformers import get_linear_schedule_with_warmup
-
-lr = 8e-3
-num_epochs = 3
-
-optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
-lr_scheduler = get_linear_schedule_with_warmup(
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=(len(train_dataloader) * num_epochs),
-)
-```
-
-Move the model to the accelerator and create a training loop that reports the loss and perplexity for each epoch.
-
-```py
-from tqdm import tqdm
-
-device = torch.accelerator.current_accelerator().type if hasattr(torch, "accelerator") else "cuda"
-model = model.to(device)
-
-for epoch in range(num_epochs):
- model.train()
- total_loss = 0
- for step, batch in enumerate(tqdm(train_dataloader)):
- batch = {k: v.to(device) for k, v in batch.items()}
- outputs = model(**batch)
- loss = outputs.loss
- total_loss += loss.detach().float()
- loss.backward()
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
-
- model.eval()
- eval_loss = 0
- eval_preds = []
- for step, batch in enumerate(tqdm(eval_dataloader)):
- batch = {k: v.to(device) for k, v in batch.items()}
- with torch.no_grad():
- outputs = model(**batch)
- loss = outputs.loss
- eval_loss += loss.detach().float()
- eval_preds.extend(
- tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
- )
-
- eval_epoch_loss = eval_loss / len(eval_dataloader)
- eval_ppl = torch.exp(eval_epoch_loss)
- train_epoch_loss = total_loss / len(train_dataloader)
- train_ppl = torch.exp(train_epoch_loss)
- print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
-```
-
-## Share your model
-
-After training is complete, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method. You'll need to login to your Hugging Face account first and enter your token when prompted.
-
-```py
-from huggingface_hub import notebook_login
-
-account =
-peft_model_id = f"{account}/mt0-large-ia3"
-model.push_to_hub(peft_model_id)
-```
-
-## Inference
-
-To load the model for inference, use the [`~AutoPeftModelForSeq2SeqLM.from_pretrained`] method. Let's also load a sentence of financial news from the dataset to generate a sentiment for.
-
-```py
-from peft import AutoPeftModelForSeq2SeqLM
-
-device = torch.accelerator.current_accelerator().type if hasattr(torch, "accelerator") else "cuda"
-
-model = AutoPeftModelForSeq2SeqLM.from_pretrained("/mt0-large-ia3").to(device)
-tokenizer = AutoTokenizer.from_pretrained("bigscience/mt0-large")
-
-i = 15
-inputs = tokenizer(ds["validation"][text_column][i], return_tensors="pt")
-print(ds["validation"][text_column][i])
-"The robust growth was the result of the inclusion of clothing chain Lindex in the Group in December 2007 ."
-```
-
-Call the [`~transformers.GenerationMixin.generate`] method to generate the predicted sentiment label.
-
-```py
-with torch.no_grad():
- inputs = {k: v.to(device) for k, v in inputs.items()}
- outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
- print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
-['positive']
-```
diff --git a/docs/source/task_guides/lora_based_methods.md b/docs/source/task_guides/lora_based_methods.md
deleted file mode 100644
index 50be188848..0000000000
--- a/docs/source/task_guides/lora_based_methods.md
+++ /dev/null
@@ -1,344 +0,0 @@
-
-
-# LoRA methods
-
-A popular way to efficiently train large models is to insert (typically in the attention blocks) smaller trainable matrices that are a low-rank decomposition of the delta weight matrix to be learnt during finetuning. The pretrained model's original weight matrix is frozen and only the smaller matrices are updated during training. This reduces the number of trainable parameters, reducing memory usage and training time which can be very expensive for large models.
-
-There are several different ways to express the weight matrix as a low-rank decomposition, but [Low-Rank Adaptation (LoRA)](../conceptual_guides/adapter#low-rank-adaptation-lora) is the most common method. The PEFT library supports several other LoRA variants, such as [Low-Rank Hadamard Product (LoHa)](../conceptual_guides/adapter#low-rank-hadamard-product-loha), [Low-Rank Kronecker Product (LoKr)](../conceptual_guides/adapter#low-rank-kronecker-product-lokr), and [Adaptive Low-Rank Adaptation (AdaLoRA)](../conceptual_guides/adapter#adaptive-low-rank-adaptation-adalora). You can learn more about how these methods work conceptually in the [Adapters](../conceptual_guides/adapter) guide. If you're interested in applying these methods to other tasks and use cases like semantic segmentation, token classification, take a look at our [notebook collection](https://huggingface.co/collections/PEFT/notebooks-6573b28b33e5a4bf5b157fc1)!
-
-Additionally, PEFT supports the [X-LoRA](../conceptual_guides/adapter#mixture-of-lora-experts-x-lora) Mixture of LoRA Experts method.
-
-This guide will show you how to quickly train an image classification model - with a low-rank decomposition method - to identify the class of food shown in an image.
-
-> [!TIP]
-> Some familiarity with the general process of training an image classification model would be really helpful and allow you to focus on the low-rank decomposition methods. If you're new, we recommend taking a look at the [Image classification](https://huggingface.co/docs/transformers/tasks/image_classification) guide first from the Transformers documentation. When you're ready, come back and see how easy it is to drop PEFT in to your training!
-
-Before you begin, make sure you have all the necessary libraries installed.
-
-```bash
-pip install -q peft transformers datasets
-```
-
-## Dataset
-
-In this guide, you'll use the [Food-101](https://huggingface.co/datasets/food101) dataset which contains images of 101 food classes (take a look at the [dataset viewer](https://huggingface.co/datasets/food101/viewer/default/train) to get a better idea of what the dataset looks like).
-
-Load the dataset with the [`~datasets.load_dataset`] function.
-
-```py
-from datasets import load_dataset
-
-ds = load_dataset("food101")
-```
-
-Each food class is labeled with an integer, so to make it easier to understand what these integers represent, you'll create a `label2id` and `id2label` dictionary to map the integer to its class label.
-
-```py
-labels = ds["train"].features["label"].names
-label2id, id2label = dict(), dict()
-for i, label in enumerate(labels):
- label2id[label] = i
- id2label[i] = label
-
-id2label[2]
-"baklava"
-```
-
-Load an image processor to properly resize and normalize the pixel values of the training and evaluation images.
-
-```py
-from transformers import AutoImageProcessor
-
-image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
-```
-
-You can also use the image processor to prepare some transformation functions for data augmentation and pixel scaling.
-
-```py
-from torchvision.transforms import (
- CenterCrop,
- Compose,
- Normalize,
- RandomHorizontalFlip,
- RandomResizedCrop,
- Resize,
- ToTensor,
-)
-
-normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
-train_transforms = Compose(
- [
- RandomResizedCrop(image_processor.size["height"]),
- RandomHorizontalFlip(),
- ToTensor(),
- normalize,
- ]
-)
-
-val_transforms = Compose(
- [
- Resize(image_processor.size["height"]),
- CenterCrop(image_processor.size["height"]),
- ToTensor(),
- normalize,
- ]
-)
-
-def preprocess_train(example_batch):
- example_batch["pixel_values"] = [train_transforms(image.convert("RGB")) for image in example_batch["image"]]
- return example_batch
-
-def preprocess_val(example_batch):
- example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["image"]]
- return example_batch
-```
-
-Define the training and validation datasets, and use the [`~datasets.Dataset.set_transform`] function to apply the transformations on-the-fly.
-
-```py
-train_ds = ds["train"]
-val_ds = ds["validation"]
-
-train_ds.set_transform(preprocess_train)
-val_ds.set_transform(preprocess_val)
-```
-
-Finally, you'll need a data collator to create a batch of training and evaluation data and convert the labels to `torch.tensor` objects.
-
-```py
-import torch
-
-def collate_fn(examples):
- pixel_values = torch.stack([example["pixel_values"] for example in examples])
- labels = torch.tensor([example["label"] for example in examples])
- return {"pixel_values": pixel_values, "labels": labels}
-```
-
-## Model
-
-Now let's load a pretrained model to use as the base model. This guide uses the [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) model, but you can use any image classification model you want. Pass the `label2id` and `id2label` dictionaries to the model so it knows how to map the integer labels to their class labels, and you can optionally pass the `ignore_mismatched_sizes=True` parameter if you're finetuning a checkpoint that has already been finetuned.
-
-```py
-from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
-
-model = AutoModelForImageClassification.from_pretrained(
- "google/vit-base-patch16-224-in21k",
- label2id=label2id,
- id2label=id2label,
- ignore_mismatched_sizes=True,
-)
-```
-
-### PEFT configuration and model
-
-Every PEFT method requires a configuration that holds all the parameters specifying how the PEFT method should be applied. Once the configuration is setup, pass it to the [`~peft.get_peft_model`] function along with the base model to create a trainable [`PeftModel`].
-
-> [!TIP]
-> Call the [`~PeftModel.print_trainable_parameters`] method to compare the number of parameters of [`PeftModel`] versus the number of parameters in the base model!
-
-
-
-
-[LoRA](../conceptual_guides/adapter#low-rank-adaptation-lora) decomposes the weight update matrix into *two* smaller matrices. The size of these low-rank matrices is determined by its *rank* or `r`. A higher rank means the model has more parameters to train, but it also means the model has more learning capacity. You'll also want to specify the `target_modules` which determine where the smaller matrices are inserted. For this guide, you'll target the *query* and *value* matrices of the attention blocks. Other important parameters to set are `lora_alpha` (scaling factor), `bias` (whether `none`, `all` or only the LoRA bias parameters should be trained), and `modules_to_save` (the modules apart from the LoRA layers to be trained and saved). All of these parameters - and more - are found in the [`LoraConfig`].
-
-```py
-from peft import LoraConfig, get_peft_model
-
-config = LoraConfig(
- r=16,
- lora_alpha=16,
- target_modules=["query", "value"],
- lora_dropout=0.1,
- bias="none",
- modules_to_save=["classifier"],
-)
-model = get_peft_model(model, config)
-model.print_trainable_parameters()
-"trainable params: 667,493 || all params: 86,543,818 || trainable%: 0.7712775047664294"
-```
-
-
-
-
-[LoHa](../conceptual_guides/adapter#low-rank-hadamard-product-loha) decomposes the weight update matrix into *four* smaller matrices and each pair of smaller matrices is combined with the Hadamard product. This allows the weight update matrix to keep the same number of trainable parameters when compared to LoRA, but with a higher rank (`r^2` for LoHA when compared to `2*r` for LoRA). The size of the smaller matrices is determined by its *rank* or `r`. You'll also want to specify the `target_modules` which determines where the smaller matrices are inserted. For this guide, you'll target the *query* and *value* matrices of the attention blocks. Other important parameters to set are `alpha` (scaling factor), and `modules_to_save` (the modules apart from the LoHa layers to be trained and saved). All of these parameters - and more - are found in the [`LoHaConfig`].
-
-```py
-from peft import LoHaConfig, get_peft_model
-
-config = LoHaConfig(
- r=16,
- alpha=16,
- target_modules=["query", "value"],
- module_dropout=0.1,
- modules_to_save=["classifier"],
-)
-model = get_peft_model(model, config)
-model.print_trainable_parameters()
-"trainable params: 1,257,317 || all params: 87,133,642 || trainable%: 1.4429753779831676"
-```
-
-
-
-
-[LoKr](../conceptual_guides/adapter#low-rank-kronecker-product-lokr) expresses the weight update matrix as a decomposition of a Kronecker product, creating a block matrix that is able to preserve the rank of the original weight matrix. The size of the smaller matrices are determined by its *rank* or `r`. You'll also want to specify the `target_modules` which determines where the smaller matrices are inserted. For this guide, you'll target the *query* and *value* matrices of the attention blocks. Other important parameters to set are `alpha` (scaling factor), and `modules_to_save` (the modules apart from the LoKr layers to be trained and saved). All of these parameters - and more - are found in the [`LoKrConfig`].
-
-```py
-from peft import LoKrConfig, get_peft_model
-
-config = LoKrConfig(
- r=16,
- alpha=16,
- target_modules=["query", "value"],
- module_dropout=0.1,
- modules_to_save=["classifier"],
-)
-model = get_peft_model(model, config)
-model.print_trainable_parameters()
-"trainable params: 116,069 || all params: 87,172,042 || trainable%: 0.13314934162033282"
-```
-
-
-
-
-[AdaLoRA](../conceptual_guides/adapter#adaptive-low-rank-adaptation-adalora) efficiently manages the LoRA parameter budget by assigning important weight matrices more parameters and pruning less important ones. In contrast, LoRA evenly distributes parameters across all modules. You can control the average desired *rank* or `r` of the matrices, and which modules to apply AdaLoRA to with `target_modules`. Other important parameters to set are `lora_alpha` (scaling factor), and `modules_to_save` (the modules apart from the AdaLoRA layers to be trained and saved). All of these parameters - and more - are found in the [`AdaLoraConfig`].
-
-```py
-from peft import AdaLoraConfig, get_peft_model
-
-config = AdaLoraConfig(
- r=8,
- init_r=12,
- tinit=200,
- tfinal=1000,
- deltaT=10,
- target_modules=["query", "value"],
- modules_to_save=["classifier"],
-)
-model = get_peft_model(model, config)
-model.print_trainable_parameters()
-"trainable params: 520,325 || all params: 87,614,722 || trainable%: 0.5938785036606062"
-```
-
-
-
-
-### Training
-
-For training, let's use the [`~transformers.Trainer`] class from Transformers. The [`Trainer`] contains a PyTorch training loop, and when you're ready, call [`~transformers.Trainer.train`] to start training. To customize the training run, configure the training hyperparameters in the [`~transformers.TrainingArguments`] class. With LoRA-like methods, you can afford to use a higher batch size and learning rate.
-
-> [!WARNING]
-> AdaLoRA has an [`~AdaLoraModel.update_and_allocate`] method that should be called at each training step to update the parameter budget and mask, otherwise the adaptation step is not performed. This requires writing a custom training loop or subclassing the [`~transformers.Trainer`] to incorporate this method. As an example, take a look at this [custom training loop](https://github.com/huggingface/peft/blob/912ad41e96e03652cabf47522cd876076f7a0c4f/examples/conditional_generation/peft_adalora_seq2seq.py#L120).
-
-```py
-from transformers import TrainingArguments, Trainer
-
-account = "stevhliu"
-peft_model_id = f"{account}/google/vit-base-patch16-224-in21k-lora"
-batch_size = 128
-
-args = TrainingArguments(
- peft_model_id,
- remove_unused_columns=False,
- eval_strategy="epoch",
- save_strategy="epoch",
- learning_rate=5e-3,
- per_device_train_batch_size=batch_size,
- gradient_accumulation_steps=4,
- per_device_eval_batch_size=batch_size,
- fp16=True,
- num_train_epochs=5,
- logging_steps=10,
- load_best_model_at_end=True,
- label_names=["labels"],
-)
-```
-
-Begin training with [`~transformers.Trainer.train`].
-
-```py
-trainer = Trainer(
- model,
- args,
- train_dataset=train_ds,
- eval_dataset=val_ds,
- processing_class=image_processor,
- data_collator=collate_fn,
-)
-trainer.train()
-```
-
-## Share your model
-
-Once training is complete, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method. You’ll need to login to your Hugging Face account first and enter your token when prompted.
-
-```py
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Call [`~transformers.PreTrainedModel.push_to_hub`] to save your model to your repositoy.
-
-```py
-model.push_to_hub(peft_model_id)
-```
-
-## Inference
-
-Let's load the model from the Hub and test it out on a food image.
-
-```py
-from peft import PeftConfig, PeftModel
-from transformers import AutoImageProcessor
-from PIL import Image
-import requests
-
-config = PeftConfig.from_pretrained("stevhliu/vit-base-patch16-224-in21k-lora")
-model = AutoModelForImageClassification.from_pretrained(
- config.base_model_name_or_path,
- label2id=label2id,
- id2label=id2label,
- ignore_mismatched_sizes=True,
-)
-model = PeftModel.from_pretrained(model, "stevhliu/vit-base-patch16-224-in21k-lora")
-
-url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg"
-image = Image.open(requests.get(url, stream=True).raw)
-image
-```
-
-
-

-
-

-
For example, the adapter weights for a opt-350m model stored on the Hub are only ~6MB compared to the full model size which can be ~700MB.
-
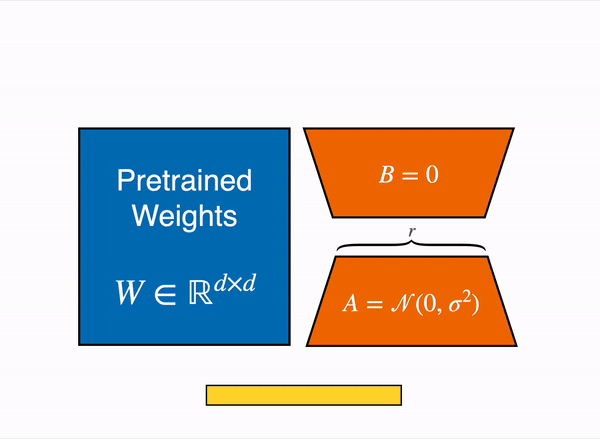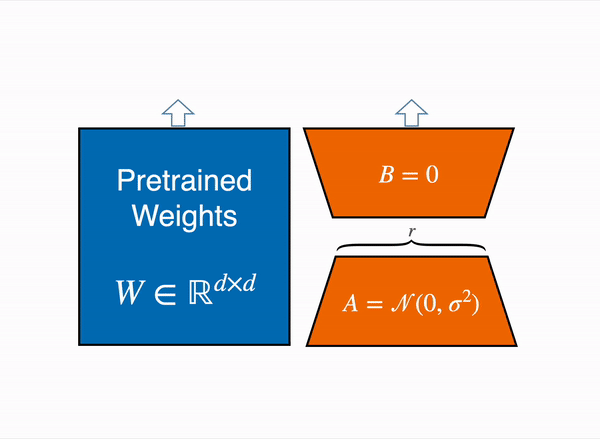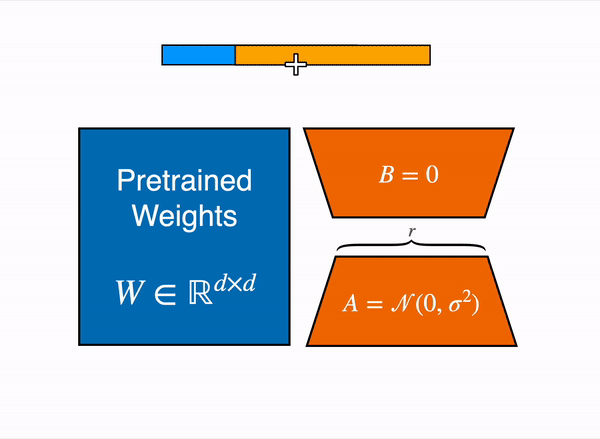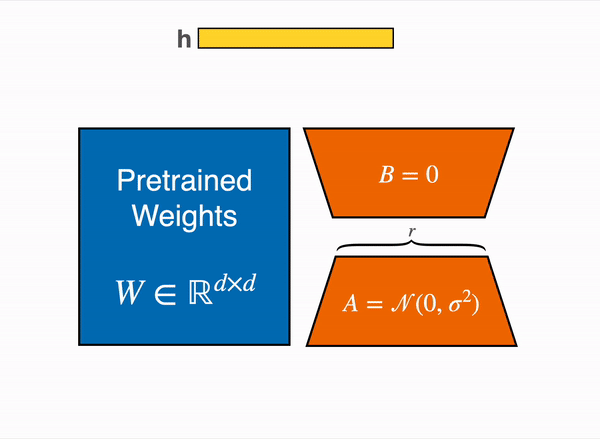 -
-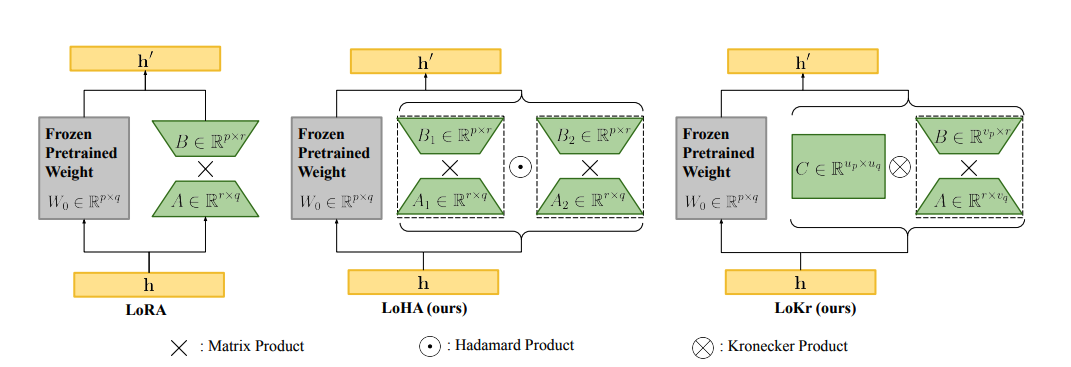 -
-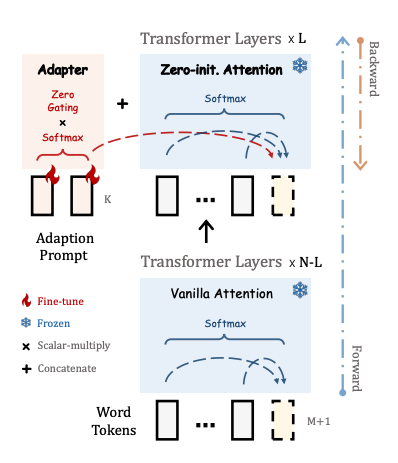 -
- -
-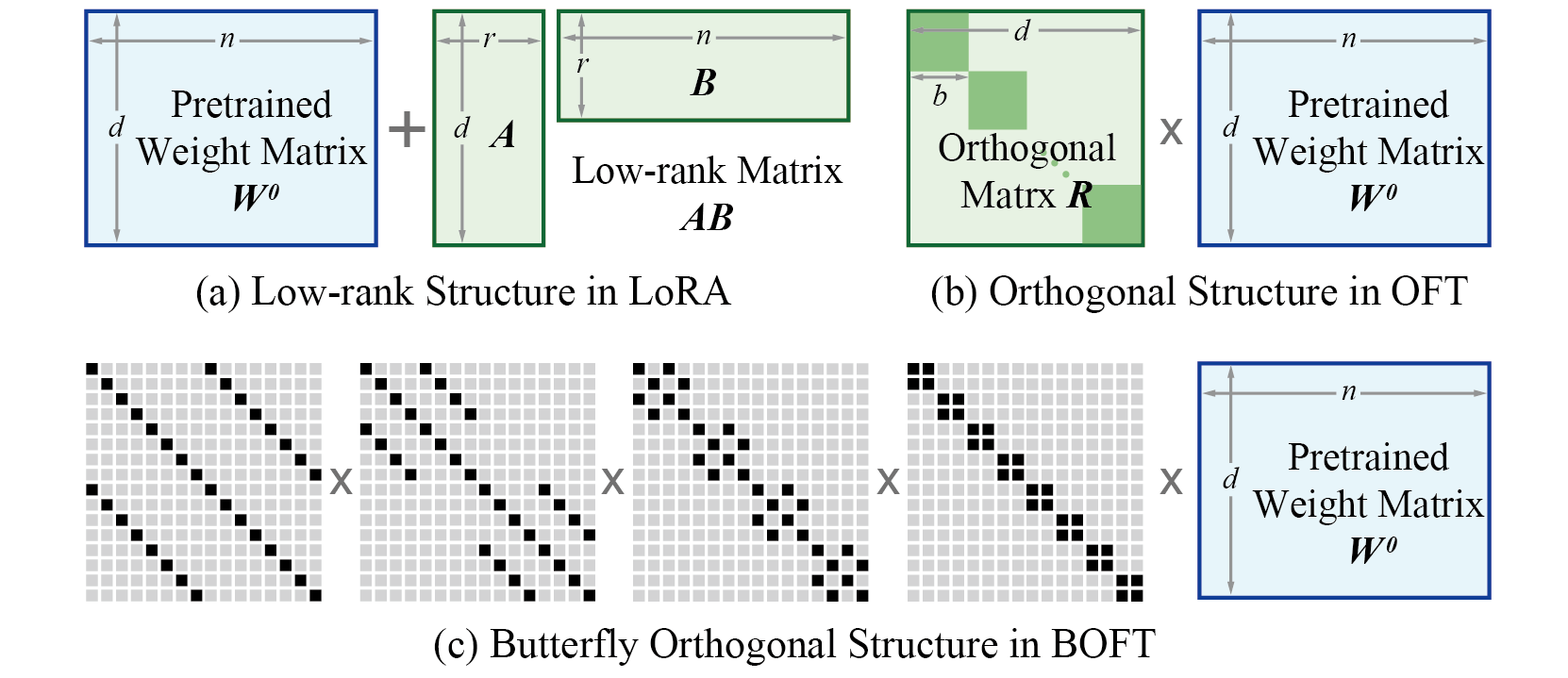 -
- -
- -
-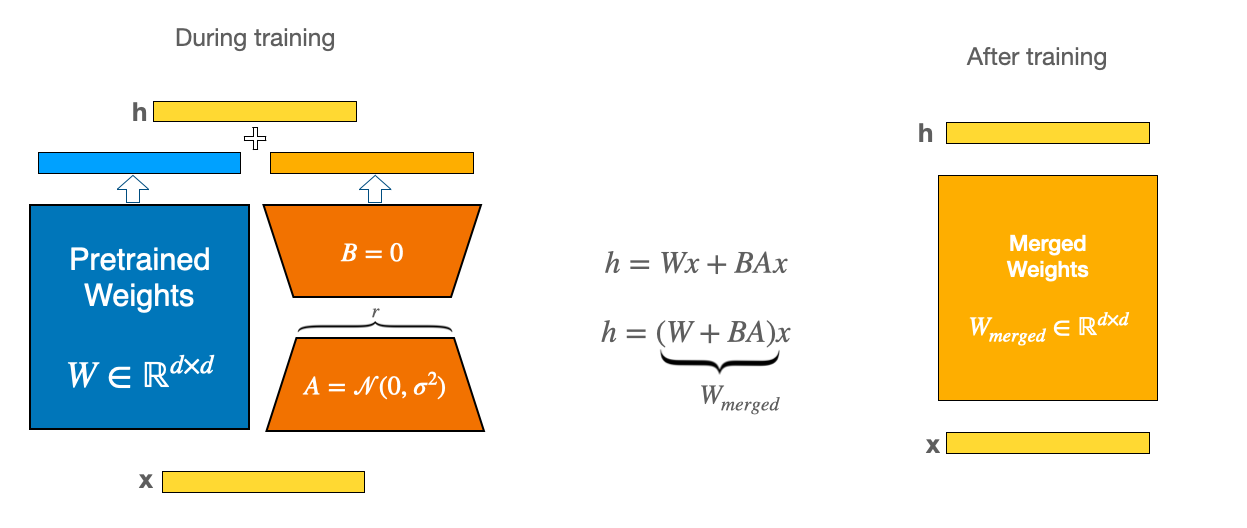 -
-


