thanks the authors for this promising work!
In the paper, the convolution in the ith head is conducted with only the selected emphasized channels and the corresponding filters:

In the code, the unselected channels is also computed with the corresponding filters, instead the unselected channels is masked with 0:

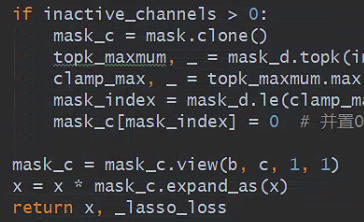
I want know if the actual MACs or flops or computation-cost are effectively reduced in the pytorch implementation?
thanks the authors for this promising work!
In the paper, the convolution in the ith head is conducted with only the selected emphasized channels and the corresponding filters:

In the code, the unselected channels is also computed with the corresponding filters, instead the unselected channels is masked with 0:


I want know if the actual MACs or flops or computation-cost are effectively reduced in the pytorch implementation?