- - - Get your Frontend JavaScript Code Covered - - - So finally you're testing your frontend JavaScript code? Great! The more you -write tests, the more confident you are with your code… but how much precisely? -That's where code coverage might -help. - - The idea behind code coverage is to record which parts of your code (functions, - statements, conditionals and so on) have been executed by your test suite, - to compute metrics out of these data and usually to provide tools for navigating - and inspecting them. - Not a lot of frontend developers I know actually test their frontend code, - and I can barely imagine how many of them have ever setup code coverage… - Mostly because there are not many frontend-oriented tools in this area - I guess. - Actually I've only found one which provides an adapter for Mocha and - actually works… - - Drinking game for web devs: - (1) Think of a noun - (2) Google "<noun>.js" - (3) If a library with that name exists - drink— Shay Friedman (@ironshay) - August 22, 2013 - - Blanket.js is an easy to install, easy to configure, -and easy to use JavaScript code coverage library that works both in-browser and -with nodejs. - - Its use is dead easy, adding Blanket support to your Mocha test suite - is just matter of adding this simple line to your HTML test file: -<script src="vendor/blanket.js" - data-cover-adapter="vendor/mocha-blanket.js"></script> - - - Source files: blanket.js, - mocha-blanket.js - - As an example, let's reuse the silly Cow example we used - in a previous episode: -// cow.js -(function(exports) { - "use strict"; - - function Cow(name) { - this.name = name || "Anon cow"; - } - exports.Cow = Cow; - - Cow.prototype = { - greets: function(target) { - if (!target) - throw new Error("missing target"); - return this.name + " greets " + target; - } - }; -})(this); - - - And its test suite, powered by Mocha and Chai: -var expect = chai.expect; - -describe("Cow", function() { - describe("constructor", function() { - it("should have a default name", function() { - var cow = new Cow(); - expect(cow.name).to.equal("Anon cow"); - }); - - it("should set cow's name if provided", function() { - var cow = new Cow("Kate"); - expect(cow.name).to.equal("Kate"); - }); - }); - - describe("#greets", function() { - it("should greet passed target", function() { - var greetings = (new Cow("Kate")).greets("Baby"); - expect(greetings).to.equal("Kate greets Baby"); - }); - }); -}); - - - Let's create the HTML test file for it, featuring Blanket and its adapter - for Mocha: -<!DOCTYPE html> -<html> -<head> - <meta charset="utf-8"> - <title>Test</title> - <link rel="stylesheet" media="all" href="vendor/mocha.css"> -</head> -<body> - <div id="mocha"></div> - <div id="messages"></div> - <div id="fixtures"></div> - <script src="vendor/mocha.js"></script> - <script src="vendor/chai.js"></script> - <script src="vendor/blanket.js" - data-cover-adapter="vendor/mocha-blanket.js"></script> - <script>mocha.setup('bdd');</script> - <script src="cow.js" data-cover></script> - <script src="cow_test.js"></script> - <script>mocha.run();</script> -</body> -</html> - - - Notes: - - Notice the data-cover attribute we added to the script tag - loading the source of our library; - The HTML test file must be served over HTTP for the adapter to - be loaded. - - Running the tests now gives us something like this: - - - - As you can see, the report at the bottom highlights that we haven't actually - tested the case where an error is raised in case a target name is missing. - We've been informed of that, nothing more, nothing less. We simply know - we're missing a test here. Isn't this cool? I think so! - Just remember that code coverage will only bring you numbers and - raw information, not actual proofs that the whole of your code logic has - been actually covered. If you ask me, the best inputs you can get about - your code logic and implementation ever are the ones issued out of pair programming -sessions - and code reviews — - but that's another story. - So is code coverage silver bullet? No. Is it useful? Definitely. Happy testing! - - - - - Functional JavaScript for crawling the Web -| - Testing your frontend JavaScript code using mocha, chai, and sinon - -
- For more than a decade the Web has used XMLHttpRequest (XHR) to achieve asynchronous requests in JavaScript. While very useful, XHR is not a very nice API. It suffers from lack of separation of concerns. The input, output and state are all managed by interacting with one object, and state is tracked using events. Also, the event-based model doesn’t play well with JavaScript’s recent focus on Promise- and generator-based asynchronous programming. - The Fetch API intends to fix most of these problems. It does this by introducing the same primitives to JS that are used in the HTTP protocol. In addition, it introduces a utility function fetch() that succinctly captures the intention of retrieving a resource from the network. - The Fetch specification, which defines the API, nails down the semantics of a user agent fetching a resource. This, combined with ServiceWorkers, is an attempt to: - - Improve the offline experience. - Expose the building blocks of the Web to the platform as part of the extensible web movement. - - As of this writing, the Fetch API is available in Firefox 39 (currently Nightly) and Chrome 42 (currently dev). Github has a Fetch polyfill. - Feature detection - Fetch API support can be detected by checking for Headers,Request, Response or fetch on the window or worker scope. - Simple fetching - The most useful, high-level part of the Fetch API is the fetch() function. In its simplest form it takes a URL and returns a promise that resolves to the response. The response is captured as a Response object. - - - - - fetch("/data.json").then(function(res) { - // res instanceof Response == true. - if (res.ok) { - res.json().then(function(data) { - console.log(data.entries); - }); - } else { - console.log("Looks like the response wasn't perfect, got status", res.status); - } -}, function(e) { - console.log("Fetch failed!", e); -}); - - - - - Submitting some parameters, it would look like this: - - - - - fetch("http://www.example.org/submit.php", { - method: "POST", - headers: { - "Content-Type": "application/x-www-form-urlencoded" - }, - body: "firstName=Nikhil&favColor=blue&password=easytoguess" -}).then(function(res) { - if (res.ok) { - alert("Perfect! Your settings are saved."); - } else if (res.status == 401) { - alert("Oops! You are not authorized."); - } -}, function(e) { - alert("Error submitting form!"); -}); - - - - - The fetch() function’s arguments are the same as those passed to the Request() constructor, so you may directly pass arbitrarily complex requests to fetch() as discussed below. - Headers - Fetch introduces 3 interfaces. These are Headers, Request and Response. They map directly to the underlying HTTP concepts, but have certain visibility filters in place for privacy and security reasons, such as supporting CORS rules and ensuring cookies aren’t readable by third parties. - The Headers interface is a simple multi-map of names to values: - - - - - var content = "Hello World"; -var reqHeaders = new Headers(); -reqHeaders.append("Content-Type", "text/plain" -reqHeaders.append("Content-Length", content.length.toString()); -reqHeaders.append("X-Custom-Header", "ProcessThisImmediately"); - - - - - The same can be achieved by passing an array of arrays or a JS object literal to the constructor: - - - - - reqHeaders = new Headers({ - "Content-Type": "text/plain", - "Content-Length": content.length.toString(), - "X-Custom-Header": "ProcessThisImmediately", -}); - - - - - The contents can be queried and retrieved: - - - - - console.log(reqHeaders.has("Content-Type")); // true -console.log(reqHeaders.has("Set-Cookie")); // false -reqHeaders.set("Content-Type", "text/html"); -reqHeaders.append("X-Custom-Header", "AnotherValue"); - -console.log(reqHeaders.get("Content-Length")); // 11 -console.log(reqHeaders.getAll("X-Custom-Header")); // ["ProcessThisImmediately", "AnotherValue"] - -reqHeaders.delete("X-Custom-Header"); -console.log(reqHeaders.getAll("X-Custom-Header")); // [] - - - - - Some of these operations are only useful in ServiceWorkers, but they provide a much nicer API to Headers. - Since Headers can be sent in requests, or received in responses, and have various limitations about what information can and should be mutable, Headers objects have a guard property. This is not exposed to the Web, but it affects which mutation operations are allowed on the Headers object. Possible values are: - - “none”: default. - “request”: guard for a Headers object obtained from a Request (Request.headers). - “request-no-cors”: guard for a Headers object obtained from a Request created with mode “no-cors”. - “response”: naturally, for Headers obtained from Response (Response.headers). - “immutable”: Mostly used for ServiceWorkers, renders a Headers object read-only. - - The details of how each guard affects the behaviors of the Headers object are in the specification. For example, you may not append or set a “request” guarded Headers’ “Content-Length” header. Similarly, inserting “Set-Cookie” into a Response header is not allowed so that ServiceWorkers may not set cookies via synthesized Responses. - All of the Headers methods throw TypeError if name is not a valid HTTP Header name. The mutation operations will throw TypeError if there is an immutable guard. Otherwise they fail silently. For example: - - - - - var res = Response.error(); -try { - res.headers.set("Origin", "http://mybank.com"); -} catch(e) { - console.log("Cannot pretend to be a bank!"); -} - - - - - Request - The Request interface defines a request to fetch a resource over HTTP. URL, method and headers are expected, but the Request also allows specifying a body, a request mode, credentials and cache hints. - The simplest Request is of course, just a URL, as you may do to GET a resource. - - - - - var req = new Request("/index.html"); -console.log(req.method); // "GET" -console.log(req.url); // "http://example.com/index.html" - - - - - You may also pass a Request to the Request() constructor to create a copy. (This is not the same as calling the clone() method, which is covered in the “Reading bodies” section.). - - - - - var copy = new Request(req); -console.log(copy.method); // "GET" -console.log(copy.url); // "http://example.com/index.html" - - - - - Again, this form is probably only useful in ServiceWorkers. - The non-URL attributes of the Request can only be set by passing initial values as a second argument to the constructor. This argument is a dictionary. - - - - - var uploadReq = new Request("/uploadImage", { - method: "POST", - headers: { - "Content-Type": "image/png", - }, - body: "image data" -}); - - - - - The Request’s mode is used to determine if cross-origin requests lead to valid responses, and which properties on the response are readable. Legal mode values are "same-origin", "no-cors" (default) and "cors". - The "same-origin" mode is simple, if a request is made to another origin with this mode set, the result is simply an error. You could use this to ensure that a request is always being made to your origin. - - - - - var arbitraryUrl = document.getElementById("url-input").value; -fetch(arbitraryUrl, { mode: "same-origin" }).then(function(res) { - console.log("Response succeeded?", res.ok); -}, function(e) { - console.log("Please enter a same-origin URL!"); -}); - - - - - The "no-cors" mode captures what the web platform does by default for scripts you import from CDNs, images hosted on other domains, and so on. First, it prevents the method from being anything other than “HEAD”, “GET” or “POST”. Second, if any ServiceWorkers intercept these requests, they may not add or override any headers except for these. Third, JavaScript may not access any properties of the resulting Response. This ensures that ServiceWorkers do not affect the semantics of the Web and prevents security and privacy issues that could arise from leaking data across domains. - "cors" mode is what you’ll usually use to make known cross-origin requests to access various APIs offered by other vendors. These are expected to adhere to the CORS protocol. Only a limited set of headers is exposed in the Response, but the body is readable. For example, you could get a list of Flickr’s most interesting photos today like this: - - - - - var u = new URLSearchParams(); -u.append('method', 'flickr.interestingness.getList'); -u.append('api_key', '<insert api key here>'); -u.append('format', 'json'); -u.append('nojsoncallback', '1'); - -var apiCall = fetch('https://api.flickr.com/services/rest?' + u); - -apiCall.then(function(response) { - return response.json().then(function(json) { - // photo is a list of photos. - return json.photos.photo; - }); -}).then(function(photos) { - photos.forEach(function(photo) { - console.log(photo.title); - }); -}); - - - - - You may not read out the “Date” header since Flickr does not allow it via Access-Control-Expose-Headers. - - - - - response.headers.get("Date"); // null - - - - - The credentials enumeration determines if cookies for the other domain are sent to cross-origin requests. This is similar to XHR’s withCredentials flag, but tri-valued as "omit" (default), "same-origin" and "include". - The Request object will also give the ability to offer caching hints to the user-agent. This is currently undergoing some security review. Firefox exposes the attribute, but it has no effect. - Requests have two read-only attributes that are relevant to ServiceWorkers intercepting them. There is the string referrer, which is set by the UA to be the referrer of the Request. This may be an empty string. The other is context which is a rather large enumeration defining what sort of resource is being fetched. This could be “image” if the request is from an <img>tag in the controlled document, “worker” if it is an attempt to load a worker script, and so on. When used with the fetch() function, it is “fetch”. - Response - Response instances are returned by calls to fetch(). They can also be created by JS, but this is only useful in ServiceWorkers. - We have already seen some attributes of Response when we looked at fetch(). The most obvious candidates are status, an integer (default value 200) and statusText (default value “OK”), which correspond to the HTTP status code and reason. The ok attribute is just a shorthand for checking that status is in the range 200-299 inclusive. - headers is the Response’s Headers object, with guard “response”. The url attribute reflects the URL of the corresponding request. - Response also has a type, which is “basic”, “cors”, “default”, “error” or “opaque”. - - "basic": normal, same origin response, with all headers exposed except “Set-Cookie” and “Set-Cookie2″. - "cors": response was received from a valid cross-origin request. Certain headers and the bodymay be accessed. - "error": network error. No useful information describing the error is available. The Response’s status is 0, headers are empty and immutable. This is the type for a Response obtained from Response.error(). - "opaque": response for “no-cors” request to cross-origin resource. Severely restricted - - The “error” type results in the fetch() Promise rejecting with TypeError. - There are certain attributes that are useful only in a ServiceWorker scope. The idiomatic way to return a Response to an intercepted request in ServiceWorkers is: - - - - - addEventListener('fetch', function(event) { - event.respondWith(new Response("Response body", { - headers: { "Content-Type" : "text/plain" } - }); -}); - - - - - As you can see, Response has a two argument constructor, where both arguments are optional. The first argument is a body initializer, and the second is a dictionary to set the status, statusText and headers. - The static method Response.error() simply returns an error response. Similarly, Response.redirect(url, status) returns a Response resulting in a redirect to url. - Dealing with bodies - Both Requests and Responses may contain body data. We’ve been glossing over it because of the various data types body may contain, but we will cover it in detail now. - A body is an instance of any of the following types. - - ArrayBuffer - ArrayBufferView (Uint8Array and friends) - Blob/ File - string - URLSearchParams - FormData – currently not supported by either Gecko or Blink. Firefox expects to ship this in version 39 along with the rest of Fetch. - - In addition, Request and Response both offer the following methods to extract their body. These all return a Promise that is eventually resolved with the actual content. - - arrayBuffer() - blob() - json() - text() - formData() - - This is a significant improvement over XHR in terms of ease of use of non-text data! - Request bodies can be set by passing body parameters: - - - - - var form = new FormData(document.getElementById('login-form')); -fetch("/login", { - method: "POST", - body: form -}) - - - - - Responses take the first argument as the body. - - - - - var res = new Response(new File(["chunk", "chunk"], "archive.zip", - { type: "application/zip" })); - - - - - Both Request and Response (and by extension the fetch() function), will try to intelligently determine the content type. Request will also automatically set a “Content-Type” header if none is set in the dictionary. - Streams and cloning - It is important to realise that Request and Response bodies can only be read once! Both interfaces have a boolean attribute bodyUsed to determine if it is safe to read or not. - - - - - var res = new Response("one time use"); -console.log(res.bodyUsed); // false -res.text().then(function(v) { - console.log(res.bodyUsed); // true -}); -console.log(res.bodyUsed); // true - -res.text().catch(function(e) { - console.log("Tried to read already consumed Response"); -}); - - - - - This decision allows easing the transition to an eventual stream-based Fetch API. The intention is to let applications consume data as it arrives, allowing for JavaScript to deal with larger files like videos, and perform things like compression and editing on the fly. - Often, you’ll want access to the body multiple times. For example, you can use the upcoming Cache API to store Requests and Responses for offline use, and Cache requires bodies to be available for reading. - So how do you read out the body multiple times within such constraints? The API provides a clone() method on the two interfaces. This will return a clone of the object, with a ‘new’ body. clone() MUST be called before the body of the corresponding object has been used. That is, clone() first, read later. - - - - - addEventListener('fetch', function(evt) { - var sheep = new Response("Dolly"); - console.log(sheep.bodyUsed); // false - var clone = sheep.clone(); - console.log(clone.bodyUsed); // false - - clone.text(); - console.log(sheep.bodyUsed); // false - console.log(clone.bodyUsed); // true - - evt.respondWith(cache.add(sheep.clone()).then(function(e) { - return sheep; - }); -}); - - - - - Future improvements - Along with the transition to streams, Fetch will eventually have the ability to abort running fetch()es and some way to report the progress of a fetch. These are provided by XHR, but are a little tricky to fit in the Promise-based nature of the Fetch API. - You can contribute to the evolution of this API by participating in discussions on the WHATWG mailing list and in the issues in the Fetch and ServiceWorkerspecifications. - For a better web! - The author would like to thank Andrea Marchesini, Anne van Kesteren and Ben Kelly for helping with the specification and implementation. -
- For more than a decade the Web has used XMLHttpRequest (XHR) to achieve - asynchronous requests in JavaScript. While very useful, XHR is not a very - nice API. It suffers from lack of separation of concerns. The input, output - and state are all managed by interacting with one object, and state is - tracked using events. Also, the event-based model doesn’t play well with - JavaScript’s recent focus on Promise- and generator-based asynchronous - programming. - The Fetch API intends - to fix most of these problems. It does this by introducing the same primitives - to JS that are used in the HTTP protocol. In addition, it introduces a - utility function fetch() that succinctly captures the intention - of retrieving a resource from the network. - The Fetch specification, which - defines the API, nails down the semantics of a user agent fetching a resource. - This, combined with ServiceWorkers, is an attempt to: - - Improve the offline experience. - Expose the building blocks of the Web to the platform as part of the - extensible web movement. - - As of this writing, the Fetch API is available in Firefox 39 (currently - Nightly) and Chrome 42 (currently dev). Github has a Fetch polyfill. - -Feature detection - - Fetch API support can be detected by checking for Headers,Request, Response or fetch on - the window or worker scope. - -Simple fetching - - The most useful, high-level part of the Fetch API is the fetch() function. - In its simplest form it takes a URL and returns a promise that resolves - to the response. The response is captured as a Response object. - - - - - fetch("/data.json").then(function(res) { - // res instanceof Response == true. - if (res.ok) { - res.json().then(function(data) { - console.log(data.entries); - }); - } else { - console.log("Looks like the response wasn't perfect, got status", res.status); - } -}, function(e) { - console.log("Fetch failed!", e); -}); - - - - - - Submitting some parameters, it would look like this: - - - - - fetch("http://www.example.org/submit.php", { - method: "POST", - headers: { - "Content-Type": "application/x-www-form-urlencoded" - }, - body: "firstName=Nikhil&favColor=blue&password=easytoguess" -}).then(function(res) { - if (res.ok) { - alert("Perfect! Your settings are saved."); - } else if (res.status == 401) { - alert("Oops! You are not authorized."); - } -}, function(e) { - alert("Error submitting form!"); -}); - - - - - - The fetch() function’s arguments are the same as those passed - to the - -Request() constructor, so you may directly pass arbitrarily - complex requests to fetch() as discussed below. - -Headers - - Fetch introduces 3 interfaces. These are Headers, Request and - -Response. They map directly to the underlying HTTP concepts, - but have - certain visibility filters in place for privacy and security reasons, - such as - supporting CORS rules and ensuring cookies aren’t readable by third parties. - The Headers interface is - a simple multi-map of names to values: - - - - - var content = "Hello World"; -var reqHeaders = new Headers(); -reqHeaders.append("Content-Type", "text/plain" -reqHeaders.append("Content-Length", content.length.toString()); -reqHeaders.append("X-Custom-Header", "ProcessThisImmediately"); - - - - - - The same can be achieved by passing an array of arrays or a JS object - literal - to the constructor: - - - - - reqHeaders = new Headers({ - "Content-Type": "text/plain", - "Content-Length": content.length.toString(), - "X-Custom-Header": "ProcessThisImmediately", -}); - - - - - - The contents can be queried and retrieved: - - - - - console.log(reqHeaders.has("Content-Type")); // true -console.log(reqHeaders.has("Set-Cookie")); // false -reqHeaders.set("Content-Type", "text/html"); -reqHeaders.append("X-Custom-Header", "AnotherValue"); - -console.log(reqHeaders.get("Content-Length")); // 11 -console.log(reqHeaders.getAll("X-Custom-Header")); // ["ProcessThisImmediately", "AnotherValue"] - -reqHeaders.delete("X-Custom-Header"); -console.log(reqHeaders.getAll("X-Custom-Header")); // [] - - - - - - Some of these operations are only useful in ServiceWorkers, but they provide - a much nicer API to Headers. - Since Headers can be sent in requests, or received in responses, and have - various limitations about what information can and should be mutable, Headers objects - have a guard property. This is not exposed to the Web, but - it affects which mutation operations are allowed on the Headers object. - Possible values are: - - “none”: default. - “request”: guard for a Headers object obtained from a Request (Request.headers). - “request-no-cors”: guard for a Headers object obtained from a Request - created - with mode “no-cors”. - “response”: naturally, for Headers obtained from Response (Response.headers). - “immutable”: Mostly used for ServiceWorkers, renders a Headers object - read-only. - - The details of how each guard affects the behaviors of the Headers object - are - in the specification. For example, - you may not append or set a “request” guarded Headers’ “Content-Length” - header. Similarly, inserting “Set-Cookie” into a Response header is not - allowed so that ServiceWorkers may not set cookies via synthesized Responses. - All of the Headers methods throw TypeError if name is not a - valid HTTP Header name. The mutation operations will throw TypeError - if there is an immutable guard. Otherwise they fail silently. For example: - - - - - var res = Response.error(); -try { - res.headers.set("Origin", "http://mybank.com"); -} catch(e) { - console.log("Cannot pretend to be a bank!"); -} - - - - - - -Request - - The Request interface defines a request to fetch a resource over HTTP. - URL, method and headers are expected, but the Request also allows specifying - a body, a request mode, credentials and cache hints. - The simplest Request is of course, just a URL, as you may do to GET a - resource. - - - - - var req = new Request("/index.html"); -console.log(req.method); // "GET" -console.log(req.url); // "http://example.com/index.html" - - - - - - You may also pass a Request to the Request() constructor to - create a copy. - (This is not the same as calling the clone() method, which - is covered in - the “Reading bodies” section.). - - - - - var copy = new Request(req); -console.log(copy.method); // "GET" -console.log(copy.url); // "http://example.com/index.html" - - - - - - Again, this form is probably only useful in ServiceWorkers. - The non-URL attributes of the Request can only be set by passing - initial - values as a second argument to the constructor. This argument is a dictionary. - - - - - var uploadReq = new Request("/uploadImage", { - method: "POST", - headers: { - "Content-Type": "image/png", - }, - body: "image data" -}); - - - - - - The Request’s mode is used to determine if cross-origin requests lead - to valid responses, and which properties on the response are readable. - Legal mode values are "same-origin", "no-cors" (default) - and "cors". - The "same-origin" mode is simple, if a request is made to another - origin with this mode set, the result is simply an error. You could use - this to ensure that - a request is always being made to your origin. - - - - - var arbitraryUrl = document.getElementById("url-input").value; -fetch(arbitraryUrl, { mode: "same-origin" }).then(function(res) { - console.log("Response succeeded?", res.ok); -}, function(e) { - console.log("Please enter a same-origin URL!"); -}); - - - - - - The "no-cors" mode captures what the web platform does by default - for scripts you import from CDNs, images hosted on other domains, and so - on. First, it prevents the method from being anything other than “HEAD”, - “GET” or “POST”. Second, if any ServiceWorkers intercept these requests, - they may not add or override any headers except for these. - Third, JavaScript may not access any properties of the resulting Response. - This ensures that ServiceWorkers do not affect the semantics of the Web - and prevents security and privacy issues that could arise from leaking - data across domains. - "cors" mode is what you’ll usually use to make known cross-origin - requests to access various APIs offered by other vendors. These are expected - to adhere to - the CORS protocol. - Only a limited set of - headers is exposed in the Response, but the body is readable. For example, - you could get a list of Flickr’s most interesting photos - today like this: - - - - - var u = new URLSearchParams(); -u.append('method', 'flickr.interestingness.getList'); -u.append('api_key', '<insert api key here>'); -u.append('format', 'json'); -u.append('nojsoncallback', '1'); - -var apiCall = fetch('https://api.flickr.com/services/rest?' + u); - -apiCall.then(function(response) { - return response.json().then(function(json) { - // photo is a list of photos. - return json.photos.photo; - }); -}).then(function(photos) { - photos.forEach(function(photo) { - console.log(photo.title); - }); -}); - - - - - - You may not read out the “Date” header since Flickr does not allow it - via - -Access-Control-Expose-Headers. - - - - - response.headers.get("Date"); // null - - - - - - The credentials enumeration determines if cookies for the other - domain are - sent to cross-origin requests. This is similar to XHR’s withCredentials - flag, but tri-valued as "omit" (default), "same-origin" and "include". - The Request object will also give the ability to offer caching hints to - the user-agent. This is currently undergoing some security review. - Firefox exposes the attribute, but it has no effect. - Requests have two read-only attributes that are relevant to ServiceWorkers - intercepting them. There is the string referrer, which is - set by the UA to be - the referrer of the Request. This may be an empty string. The other is - -context which is a rather large enumeration defining - what sort of resource is being fetched. This could be “image” if the request - is from an - <img>tag in the controlled document, “worker” if it is an attempt to load a - worker script, and so on. When used with the fetch() function, - it is “fetch”. - -Response - - Response instances are returned by calls to fetch(). - They can also be created by JS, but this is only useful in ServiceWorkers. - We have already seen some attributes of Response when we looked at fetch(). - The most obvious candidates are status, an integer (default - value 200) and statusText (default value “OK”), which correspond - to the HTTP status code and reason. The ok attribute is just - a shorthand for checking that status is in the range 200-299 - inclusive. - headers is the Response’s Headers object, with guard “response”. - The url attribute reflects the URL of the corresponding request. - Response also has a type, which is “basic”, “cors”, “default”, - “error” or - “opaque”. - - "basic": normal, same origin response, with all headers exposed - except - “Set-Cookie” and “Set-Cookie2″. - "cors": response was received from a valid cross-origin request. - Certain headers and the bodymay be accessed. - "error": network error. No useful information describing - the error is available. The Response’s status is 0, headers are empty and - immutable. This is the type for a Response obtained from Response.error(). - "opaque": response for “no-cors” request to cross-origin - resource. Severely - restricted - - - The “error” type results in the fetch() Promise rejecting with - TypeError. - There are certain attributes that are useful only in a ServiceWorker scope. - The - idiomatic way to return a Response to an intercepted request in ServiceWorkers - is: - - - - - addEventListener('fetch', function(event) { - event.respondWith(new Response("Response body", { - headers: { "Content-Type" : "text/plain" } - }); -}); - - - - - - As you can see, Response has a two argument constructor, where both arguments - are optional. The first argument is a body initializer, and the second - is a dictionary to set the status, statusText and headers. - The static method Response.error() simply returns an error - response. Similarly, Response.redirect(url, status) returns - a Response resulting in - a redirect to url. - -Dealing with bodies - - Both Requests and Responses may contain body data. We’ve been glossing - over it because of the various data types body may contain, but we will - cover it in detail now. - A body is an instance of any of the following types. - - ArrayBuffer - - ArrayBufferView (Uint8Array - and friends) - Blob/ - File - - string - URLSearchParams - - FormData – - currently not supported by either Gecko or Blink. Firefox expects to ship - this in version 39 along with the rest of Fetch. - - In addition, Request and Response both offer the following methods to - extract their body. These all return a Promise that is eventually resolved - with the actual content. - - arrayBuffer() - - blob() - - json() - - text() - - formData() - - - This is a significant improvement over XHR in terms of ease of use of - non-text data! - Request bodies can be set by passing body parameters: - - - - - var form = new FormData(document.getElementById('login-form')); -fetch("/login", { - method: "POST", - body: form -}) - - - - - - Responses take the first argument as the body. - - - - - var res = new Response(new File(["chunk", "chunk"], "archive.zip", - { type: "application/zip" })); - - - - - - Both Request and Response (and by extension the fetch() function), - will try to intelligently determine the content type. - Request will also automatically set a “Content-Type” header if none is - set in the dictionary. - -Streams and cloning - - It is important to realise that Request and Response bodies can only be - read once! Both interfaces have a boolean attribute bodyUsed to - determine if it is safe to read or not. - - - - - var res = new Response("one time use"); -console.log(res.bodyUsed); // false -res.text().then(function(v) { - console.log(res.bodyUsed); // true -}); -console.log(res.bodyUsed); // true - -res.text().catch(function(e) { - console.log("Tried to read already consumed Response"); -}); - - - - - - This decision allows easing the transition to an eventual stream-based Fetch - API. The intention is to let applications consume data as it arrives, allowing - for JavaScript to deal with larger files like videos, and perform things - like compression and editing on the fly. - Often, you’ll want access to the body multiple times. For example, you - can use the upcoming Cache API to - store Requests and Responses for offline use, and Cache requires bodies - to be available for reading. - So how do you read out the body multiple times within such constraints? - The API provides a clone() method on the two interfaces. This - will return a clone of the object, with a ‘new’ body. clone() MUST - be called before the body of the corresponding object has been used. That - is, clone() first, read later. - - - - - addEventListener('fetch', function(evt) { - var sheep = new Response("Dolly"); - console.log(sheep.bodyUsed); // false - var clone = sheep.clone(); - console.log(clone.bodyUsed); // false - - clone.text(); - console.log(sheep.bodyUsed); // false - console.log(clone.bodyUsed); // true - - evt.respondWith(cache.add(sheep.clone()).then(function(e) { - return sheep; - }); -}); - - - - - - -Future improvements - - Along with the transition to streams, Fetch will eventually have the ability - to abort running fetch()es and some way to report the progress - of a fetch. These are provided by XHR, but are a little tricky to fit in - the Promise-based nature of the Fetch API. - You can contribute to the evolution of this API by participating in discussions - on the WHATWG mailing list and - in the issues in the Fetch and - ServiceWorkerspecifications. - For a better web! - The author would like to thank Andrea Marchesini, Anne van Kesteren and Ben -Kelly for helping with the specification and implementation. - - -
- - Just-released Minecraft exploit makes it easy to crash game servers - Two-year-old bug exposes thousands of servers to crippling attack. - - by Dan Goodin - Apr 16, 2015 8:02 pm UTC - - - - Share - - - Tweet - - - Google - - - Reddit - - 75 - - - - - - - Kevin - - - - - A flaw in the wildly popular online game Minecraft makes it easy for just about anyone to crash the server hosting the game, according to a computer programmer who has released proof-of-concept code that exploits the vulnerability. - "I thought a lot before writing this post," Pakistan-based developer Ammar Askar wrote in a blog post published Thursday, 21 months, he said, after privately reporting the bug to Minecraft developer Mojang. "On the one hand I don't want to expose thousands of servers to a major vulnerability, yet on the other hand Mojang has failed to act on it." - The bug resides in the networking internals of the Minecraft protocol. It allows the contents of inventory slots to be exchanged, so that, among other things, items in players' hotbars are displayed automatically after logging in. Minecraft items can also store arbitrary metadata in a file format known as Named Binary Tag (NBT), which allows complex data structures to be kept in hierarchical nests. Askar has released proof-of-concept attack code he said exploits the vulnerability to crash any server hosting the game. Here's how it works. - - The vulnerability stems from the fact that the client is allowed to send the server information about certain slots. This, coupled with the NBT format’s nesting allows us to craft a packet that is incredibly complex for the server to deserialize but trivial for us to generate. - In my case, I chose to create lists within lists, down to five levels. This is a json representation of what it looks like. - rekt: { - list: [ - list: [ - list: [ - list: [ - list: [ - list: [ - ] - list: [ - ] - list: [ - ] - list: [ - ] - ... - ] - ... - ] - ... - ] - ... - ] - ... - ] - ... -} - The root of the object, rekt, contains 300 lists. Each list has a list with 10 sublists, and each of those sublists has 10 of their own, up until 5 levels of recursion. That’s a total of 10^5 * 300 = 30,000,000 lists. - And this isn’t even the theoretical maximum for this attack. Just the nbt data for this payload is 26.6 megabytes. But luckily Minecraft implements a way to compress large packets, lucky us! zlib shrinks down our evil data to a mere 39 kilobytes. - Note: in previous versions of Minecraft, there was no protocol wide compression for big packets. Previously, NBT was sent compressed with gzip and prefixed with a signed short of its length, which reduced our maximum payload size to 2^15 - 1. Now that the length is a varint capable of storing integers up to 2^28, our potential for attack has increased significantly. - When the server will decompress our data, it’ll have 27 megs in a buffer somewhere in memory, but that isn’t the bit that’ll kill it. When it attempts to parse it into NBT, it’ll create java representations of the objects meaning suddenly, the sever is having to create several million java objects including ArrayLists. This runs the server out of memory and causes tremendous CPU load. - This vulnerability exists on almost all previous and current Minecraft versions as of 1.8.3, the packets used as attack vectors are the 0x08: Block Placement Packet and 0x10: Creative Inventory Action. - The fix for this vulnerability isn’t exactly that hard, the client should never really send a data structure as complex as NBT of arbitrary size and if it must, some form of recursion and size limits should be implemented. - These were the fixes that I recommended to Mojang 2 years ago. - - Ars is asking Mojang for comment and will update this post if company officials respond. - - - Expand full story - - - -
- - Feature Story (7 pages) - Review: The absolutely optional Apple Watch and Watch OS 1.0 - A pragmatist's guide to a nice but not quite necessary gadget. -
- Lorem - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Links - link - link - link - link - link - link - link - link - Images - - - - - - Foo - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Links - link - link - link - link - link - link - link - link - Images - - - - - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. - Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - Iframe fallback test - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - - - - - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- - 'Neutral' Snopes Fact-Checker David Emery: 'Are There Any Un-Angry Trump Supporters?' - - - 6366 - - 12 - - - - - - - - JIM WATSON/AFP/Getty Images - - - by Lucas Nolan22 Dec 2016651 22 Dec, 2016 - 22 Dec, 2016 - - - - - - SIGN UP FOR OUR NEWSLETTER - - - - - - - - - - - - Snopes fact checker and staff writer David Emery posted to Twitter asking if there were “any un-angry Trump supporters?” - Emery, a writer for partisan “fact-checking” website Snopes.com which soon will be in charge of labelling “fake news” alongside ABC News and Politifact, retweeted an article by Vulture magazine relating to the protests of the Hamilton musical following the decision by the cast of the show to make a public announcement to Vice-president elect Mike Pence while he watched the performance with his family. - - SIGN UP FOR OUR NEWSLETTER - - - - - - - - - - - - The tweet from Vulture magazine reads, “#Hamilton Chicago show interrupted by angry Trump supporter.” Emery retweeted the story, saying, “Are there un-angry Trump supporters?” - - - - - - - - - - - This isn’t the first time the Snopes.com writer has expressed anti-Trump sentiment on his Twitter page. In another tweet in which Emery links to an article that falsely attributes a quote to President-elect Trump, Emery states, “Incredibly, some people actually think they have to put words in Trump’s mouth to make him look bad.” - - - - - Emery also retweeted an article by New York magazine that claimed President-elect Trump relied on lies to win during his campaign and that we now lived in a “post-truth” society. “Before long we’ll all have forgotten what it was like to live in the same universe; or maybe we already have,” Emery tweeted. - - - - - - - - - - - Facebook believe that Emery, along with other Snopes writers, ABC News, and Politifact are impartial enough to label and silence what they believe to be “fake news” on social media. - Lucas Nolan is a reporter for Breitbart Tech covering issues of free speech and online censorship. Follow him on Twitter @LucasNolan_ or email him at lnolan@breitbart.com - - - - - - - - -
- - - - - - - - - - - - - News - Business - Business News - - The seven secrets that hotel owners don't want you to know - - - - Hotel bosses spill the beans on cost cutting and horrible hygiene - - - - Hazel Sheffield - - Friday 25 December 2015 - - 0 comments - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Click here to receive live updates on the US election - - - - - - - - - - - - - - - - - - - Even luxury hotels aren’t always cleaned as often as they should be Getty Images - - - - - - - Most people go to hotels for the pleasure of sleeping in a giant bed with clean white sheets and waking up to fresh towels in the morning. - - But those towels and sheets might not be as clean as they look, according to the hotel bosses that responded to an online thread about the things hotel owners don’t want you to know. - - Zeev Sharon and Michael Forrest Jones both run hotel start-ups in the US. Forrest Jones runs the start-up Beechmont Hotels Corporation, a hotel operating company that consults with hotel owners on how they can improve their business. Sharon is the CEO of Hotelied, a start-up that allows people to sign up for discounts at luxury hotels. - - But even luxury hotels aren’t always cleaned as often as they should be. - - Here are some of the secrets that the receptionist will never tell you when you check in, according to answers posted on Quora. - - - - - - - - - - - Even posh hotels might not wash a blanket in between stays - - - - - 1. Take any blankets or duvets off the bed - - Forrest Jones said that anything that comes into contact with any of the previous guest’s skin should be taken out and washed every time the room is made, but that even the fanciest hotels don’t always do so. "Hotels are getting away from comforters. Blankets are here to stay, however. But some hotels are still hesitant about washing them every day if they think they can get out of it," he said. - - - - - - - - - - - - - - - Play Video - - Play - - - - - - - - Mute - - Current Time 0:00 - - - / - - - Duration Time 0:00 - - - - Loaded: 0% - - - Progress: 0% - - - - - Stream TypeLIVE - - - Remaining Time -0:00 - - - Share - - - - Playback Rate - 1 - - - - - Chapters - - Chapters - - - - descriptions off, selected - - Descriptions - - - - subtitles off, selected - - Subtitles - - - - captions settings, opens captions settings dialog - captions off, selected - - Captions - - - - default, selected - - - Fullscreen - - - This is a modal window. - - - - - - - Foreground - - --- - White - Black - Red - Green - Blue - Yellow - Magenta - Cyan - - - - --- - Opaque - Semi-Opaque - - - - - - Background - - --- - White - Black - Red - Green - Blue - Yellow - Magenta - Cyan - - - - --- - Opaque - Semi-Transparent - Transparent - - - - - - Window - - --- - White - Black - Red - Green - Blue - Yellow - Magenta - Cyan - - - - --- - Opaque - Semi-Transparent - Transparent - - - - - - - - - Font Size - - 50% - 75% - 100% - 125% - 150% - 175% - 200% - 300% - 400% - - - - - Text Edge Style - - None - Raised - Depressed - Uniform - Dropshadow - - - - - Font Family - - Default - Monospace Serif - Proportional Serif - Monospace Sans-Serif - Proportional Sans-Serif - Casual - Script - Small Caps - - - - - - - Defaults - Done - - - - Close - This is a modal window. This modal can be closed by pressing the Escape key or activating the close button. - - - - - - - - - - - Video shows bed bug infestation at New York hotel - - - - - - - - - - - - Forrest Jones advised stuffing the peep hole with a strip of rolled up notepaper when not in use. - - - - - 2. Check the peep hole has not been tampered with - - This is not common, but can happen, Forrest Jones said. He advised stuffing the peep hole with a strip of rolled up notepaper when not in use. When someone knocks on the door, the paper can be removed to check who is there. If no one is visible, he recommends calling the front desk immediately. “I look forward to the day when I can tell you to choose only hotels where every employee who has access to guestroom keys is subjected to a complete public records background check, prior to hire, and every year or two thereafter. But for now, I can't,” he said. - - - - - - - - - - - Put luggage on the floor - - - - - 3. Don’t use a wooden luggage rack - - Bedbugs love wood. Even though a wooden luggage rack might look nicer and more expensive than a metal one, it’s a breeding ground for bugs. Forrest Jones says guests should put the items they plan to take from bags on other pieces of furniture and leave the bag on the floor. - - - - - - - - - - - The old rule of thumb is that for every 00 invested in a room, the hotel should charge in average daily rate - - - - - 4. Hotel rooms are priced according to how expensive they were to build - - Zeev Sharon said that the old rule of thumb is that for every $1000 invested in a room, the hotel should charge $1 in average daily rate. So a room that cost $300,000 to build, should sell on average for $300/night. - - - Read more - - - Man rents out flatmate's room on Airbnb - without telling him - Upmarket holiday company goes bust on eve of bank holiday - It’s possible for a city to have too many tourists - - - - 5. Beware the wall-mounted hairdryer - - It contains the most germs of anything in the room. Other studies have said the TV remote and bedside lamp switches are the most unhygienic. “Perhaps because it's something that's easy for the housekeepers to forget to check or to squirt down with disinfectant,” Forrest Jones said. - - - - - - - - - - Business news in pictures - - - - - - - - - - - - - - - - - - - 50 - show all - - - - - - - - - - Business news in pictures - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1/50 - - United goin down - - Manchester United's absence from the Champions League hurt more than the fans' pride last year - it also dented the bottom line. Revenues at the New Uork listed club dipped 8.8 per cent to £395.2m in the year to June, triggering a £1.2 million loss after broadcasting and sponsorship deals dried up. The club said it was now looking to raise $400m from a share issue. - - GETTY IMAGES - - - - 2/50 - - Star Wars boosts economy - - Production of the next Star Wars movie has brought an economic impact of some £150 million to Britain, according to company accounts. The seventh movie in the series, The Force Awakens, will be released in December. - - - - - 3/50 - - Natalie Massenet Leaves Net-a-Porter - - The Net-a-Porter founder Natalie Massenet decided to quit the online fashion retailer during "a summer of reflection" that included a spectacular 50th birthday party on the Almalfi coast. - - Rex - - - - 4/50 - - I'll keep working, says Mayer - - The chief executive of Yahoo, Marissa Mayer, said that she was expecting twin girls in December. She said she would "approach the pregnancy and delivery the same way as I did with my son three years ago, taking limited time away and working throughout". In 2012, she took two weeks off when her first child was born. - - GETTY IMAGES - - - - 5/50 - - World's richest lose $182b - - Warren Buffett, the world’s third richest person, lost $3.6bn in last week’s market slump. Fears that China's economy is slowing took many indices into correction territory. The turmoil has wiped $182 billion off the wealth of the 400 richest billionaires, according to research by Bloomberg. - - Getty - - - - 6/50 - - City for sale - - London City Airport was put up for sale by the American hedge fund Global Infrastructure Partners, which also owns Gatwick and Edinburgh airports. It is expected to fetch around £2 billion - - Getty - - - - 7/50 - - Kicking up a skink Down Under - - An Australian court has overturned approval for Adani’s Carmichael coal mine in north Queensland, based on concerns over the impact of the project on the endangered yakka skink (pictured). Standard Chartered is under renewed pressure to stop financing the deal - - - - - 8/50 - - Scope to do more in the City? - - Damien Hirst's 7m statue, Charity, has been installed in the shadow of the Gherkin in London. It is based on an old Scope collection from the 1960s and has provoked a debate about the City and disability. The Lord Mayor of London says the City does not employ enough disabled people. - - Reuters/Corbis - - - - 9/50 - - Thousands more take a look at Sky - - Drama and football are a winning formula for Sky, which has recorded its best growth for 11 years, gaining 124,000 UK customers in the past quarter. Sky paid £4.2bn for Premier League rights, but also has 35 dramas planned, following successes such as the ‘The Enfield Haunting’ (pictured) with Timothy Spall. - - - - - 10/50 - - FirstGroup suffers over lost lines - - FirstGroup, the bus and rail operator, is paying the price for losing a string of rail franchises last year. Rail revenue will be “substantially lower” in 2015 after some big franchise losses, including ScotRail. The division lost out on tenders for the East Coast and West Coast (pictured) mainlines, which went to Virgin Trains. - - GETTY - - - - 11/50 - - US retail rush hour slows down again - - US retail sales unexpectedly fell in June as households cut purchases of cars and a range of other goods. Sales fell 0.3 per cent, while economists had forecast a small rise. - - AFP - - - - 12/50 - - Blockbusters aid Pinewood expansion - - Pinewood Studios revealed it is having to turn away major films until the five new stages it is building come on stream next summer. The group still saw operating profits rise from £4.9m to £5.8m in the past year, which saw it host the new Star Wars and Avengers films (Scarlett Johansson, pictured, stars in ‘Avengers: Age Of Ultron’) as well as the latest Bond release, ‘Spectre’ - - Marvel 2015 - - - - 13/50 - - Rogue trader freed - - Kweku Adoboli, the former UBS trader who was convicted of the UK’s biggest banking fraud, has been released from jail after serving half of his seven-year sentence. He was imprisoned in 2012 on two counts of fraud that resulted in losses of £1.4bn, the largest trading loss in British banking history - - Getty - - - - 14/50 - - Burberry’s autumn ad campaign - - Burberry is launching its autumn ad campaign today with a cast of models including the singer Tom Odell and the actress Holliday Grainger - - Burberry/Testino - - - - 15/50 - - Sneak peak at console battlefield - - Videogame titans Microsoft and Sony vied for attention ahead of the industry’s annual E3 conference yesterday, giving fans sneak peaks of the latest games for their Xbox and PlayStation consoles, including Sony’s new ‘Assassin’s Creed Syndicate’ - - Getty Images - - - - 16/50 - - High street shops hit by exodus - - The number of Britons out shopping has fallen for the second month in a row. High streets saw 1.5 per cent fewer shoppers and shopping centres 2 per cent fewer in May compared with a year ago. Only out-of-town retail parks saw a rise, with 1.4 per cent more visitors, the British Retail Consortium said. Overall shopper numbers fell by 1 per cent. - - Getty - - - - 17/50 - - Argentina hit by strikes - - Daily life ground to a halt in Buenos Aires yesterday amid a 24-hour general strike protesting against moves to limit pay rises and increase taxes. - - AFP/Getty Images - - - - 18/50 - - Duty rises blamed for beer woes - - Beer sales are still “fragile” after a decade of “devastating” duty hikes, according to the British Beer and Pub Association. The industry lobbyists said sales in pubs and shops were up 1.5 per cent in the past year, but fell by 0.8 per cent in the first quarter. Sales have fallen 24 per cent in the past decade. - - - - - 19/50 - - New Look in push for men - - New Look is planning a menswear push after poaching Christopher Englinde, H&M’s menswear chief. Like-for-like sales at the fashion chain rose 5 per cent - - Victoria Middleton - - - - 20/50 - - Court halts Airbus insider trading trial - - A French court has quashed an insider trading case against seven current and former Airbus executives as well as Lagardère and Daimler, who were investors in the plane maker. Judges said the trial was dropped as they had all been cleared by France’s market regulator AMF, and it would have breached safeguards against double prosecutions - - - - - 21/50 - - Alibaba hits back over ‘fake’ claims - - Alibaba has hit out at Gucci’s owner, Kering, for “wasteful litigation instead of the path of constructive co-operation”, after the French luxury giant filed a lawsuit in New York alleging the Chinese online retailer allows sales of fake goods on its websites. Gucci unveiled its Fall-Winter 2015-2016 women’s range at this year’s Milan Fashion Week - - Getty Images - - - - 22/50 - - Hats off to Ralph Lauren - - The upmarket US clothing company Ralph Lauren saw sales climb 1 per cent to $1.9bn (£1.2bn) in the quarter to 28 March. The company said it opened several stores across key markets around the world, fuelling momentum for its luxury accessories business. However, net income decreased to $124m, compared with $153m in the same quarter last year, partly as a result of exchange-rate impacts. - - EPA - - - - 23/50 - - With this ring… arts sales jump - - Sotheby’s raised $380m (£241m) in its New York contemporary art sale, a day after rival Christie’s sold a Picasso for a record $179m, with the auction house describing bidding as a “rush for art”. The top lots included Roy Lichtenstein’s ‘The Ring (Engagement)’ Estate of Roy Lichtenstein - - AP - - - - 24/50 - - Brewdog’s dead cat bounce - - Brewdog parachuted taxidermy “fats cats” holding its latest prospectus out of a helicopter over the City of London as the Scottish brewer looks to drum up publicity for its latest “punk” fundraising. The craft beer group has already raised £5m of the £25m it is seeking from investors to fund a new brewhouse and set up a US operation - - - - - 25/50 - - Change at the top for Alibaba - - Chinese ecommerce giant Alibaba replaced its chief executive yesterday. Daniel Zhang, chief operating officer, will replace Jonathan Lu. The move follows the share price briefly dipping below $80 this week, its lowest since its New York flotation in September. - - ChinaFotoPress/ChinaFotoPress via Getty Images - - - - 26/50 - - Put that light out - - New York City officials have been informed by the American Government that the Big Apple’s dazzling neon billboards violate a 2012 highways ruling and must be taken down. The city could forfeit up to $90m (£59m) in federal highway money if it fails to comply. New York is debating getting an exemption from the rule. - - AP - - - - 27/50 - - Lionsgate wants the lion’s share - - Lionsgate yesterday announced plans to finance and co-invest in up to 25 British independent films over the next four years. The Canadian-US entertainment company has previously invested in such UK films as A Little Chaos, starring Kate Winslet - - - - - 28/50 - - Tillman planning a ‘new Jaeger’ - - The fashion entrepreneur Harold Tillman (centre) has spoken out against the way Jon Moulton’s Better Capital has run Jaeger since taking it over from him and declared he would start a rival business to serve disappointed Jaeger customers. Mr Tillman said turnover at the group had fallen and losses widened since the private equity firm took over. - - 2011 Getty Images - - - - 29/50 - - Aer Lingus: end in sight to Irish talks with IAG - - Aer Lingus, the Irish carrier being bid for by British Airways’ owner IAG, yesterday said it is hopeful talks between its suitor and the Irish government will conclude soon. Ireland owns a 25 per cent stake in the airline, which posted a €48m (£35m) first-quarter loss yesterday but said its long-haul business had performed well - - - - - 30/50 - - Weir sheds more jobs in oil slump - - Slumping orders for oil and gas projects in the wake of the oil price collapse have forced the engineer Weir to cut another 125 jobs. Since the start of the year, the US oil-rig count has more than halved, sending orders in Weir’s oil and gas division down 23 per cent in the first quarter. Weir has already shed 1,300 staff in the past year - - - - - 31/50 - - Williams F1 team drives into the red - - Formula 1 team Williams drove £34m into the red for 2014 after the worst season in its history. A fall in prize money for 2013 – paid a year in arrears – meant the Frankfurt-listed group went into reverse after a £12m profit the year before. But Williams said this year’s figures would be better after it finished third in the 2014 Constructors’ Championship. Its driver Felipe Massa, pictured in Bahrain, is 5th in this year’s driver’s contest - - - - - 32/50 - - Rivals roar as Harley stalls - - A strong dollar allowed US motorcycle-maker Harley-Davidson’s foreign competitors to undercut its prices in the first quarter, hurting its sales and market share and prompting it to lower 2015 shipment forecasts. The news sent its shares down 10 per cent in early trading - - - - - 33/50 - - Climate changes for BP - - BP will be more accountable for its role in climate change after 98 per cent of investors backed a resolution to make it more transparent on the issue. BP’s annual shareholders’ meeting was held in London yesterday and attracted a protest against offshore oil drilling. - - - - - 34/50 - - Car sales lift in Europe - - Demand for new cars in Europe soared last month, particularly in Spain and Portugal where sales increased by more than 40 per cent on March last year. Meanwhile UK sales were up 6.1 per cent on March 2014, according to the European Automobile Manufacturer Association. - - - - - 35/50 - - Ricci heir guilt of tax fraud - - Arlette Ricci, the heir to the Nina Ricci perfume and fashion fortune, has been convicted of tax fraud by a Paris court, after hiding millions in an offshore HSBC account. Ms Ricci, 73, was sentenced to a year in prison and ordered to pay a €1m (£72,000) fine. - - Rex - - - - 36/50 - - Camden set for a makeover - - Teddy Sagi, Camden Market’s new Israeli billionaire owner, has appointed Mace as project manager to oversee the redevelopment of Camden Lock Village, with 170 homes as well as shops and offices in the north London district. - - Getty - - - - 37/50 - - All aboard the iron ore train - - Australia is reportedly examining how BHP Billiton and Rio Tinto shift billions of dollars in iron ore profits through low tax hubs in Singapore. - - AFP/Getty Images - - - - 38/50 - - Shell’s Arctic plans under fire - - Greenpeace activists have climbed aboard a Shell oil rig in the Pacific Ocean bound for the Arctic. They plan to camp under the rig’s main deck in protest against the oil giant’s plans to restart drilling off the coast of Alaska. The group said the six protesters would occupy the underside of the Polar Pioneer’s main deck but would not interfere with the vessel. - - Vincenzo Floramo / Greenpeace - - - - 39/50 - - GoDaddy off to flying start in New York - - GoDaddy shares jumped 34 per cent as they started trading on the NYSE Wednesday, valuing the website group at more than $5bn (£3bn). The firm, which manages 59 million web domains – a fifth of the world’s total – raised $460m. It sponsors race car driver Danica Patrick (pictured with chief executive Blake Irving) and is backed by private equity firms KKR and Silver Lake - - EPA/ANDREW GOMBERT - - - - 40/50 - - The first lady of high street banks - - Shriti Vadera, a former adviser to Gordon Brown, has become the first female chairman of a UK high street bank, succeeding Sir Terry Burns at the helm of Santander UK. Baroness Vadera will be paid £650,000 and work alongside Santander’s new CEO, Nathan Bostock - - Paul Morigi/Getty Images - - - - 41/50 - - Sterling returns for Compass - - Compass could see £30m added to its annual profits, thanks to the strength of the pound. The catering giant, which serves up strawberries and cream at Wimbledon each year, said underlying revenues are up 5.5 per cent in the first half, while gains from sterling against the euro, yen and Brazil’s real are set to offset any weakness of the pound against the dollar - - Peter Macdiarmid/Getty Images - - - - 42/50 - - Serco sells Australian rail unit - - Serco has sold its Great Southern Rail to the Australian private equity firm Allegro Funds in a £2.5m deal. The disposal of the luxury business, which runs tourist trains such as The Ghan (pictured) across Australia, is part of the outsourcing group’s move to focus on core businesses under its new chief executive, Rupert Soames - - Mark Metcalfe/Getty Images - - - - 43/50 - - Italian Retailer Yoox eyes Net-a-Porter - - The Italian internet retailer Yoox in the latest contender to swoop in with an offer for the luxury fashion business Net-a-Porter that could value the London-based firm at £1.3 billion - - Splash News/Corbis - - - - 44/50 - - Li Ka-shing buys O2 for £10bn - - Li Ka-shing’s Hutchison Whampoa has finalised a £10.25bn deal to buy the UK mobile business O2 from Spain’s Telefonica. Hutchison, the Hong Kong conglomerate that already owns Three in the UK, entered exclusive talks with Telefonica in January. - - AP - - - - 45/50 - - Jaguar climbs high in the City - - A Hollywood stuntman in a Jaguar XF crosses the River Thames by highwire to promote the latest model. The stunt was supported by 34mm-wide carbon wires. - - PA - - - - 46/50 - - Pubs get protected - - New rules have been announced to mark Community Pubs Day today which protect local pubs and give communities a greater say in planning processes. - - Oli Scarff | Getty Images - - - - - 47/50 - - Tesco jet still left on shelf - - Tesco has been forced to cut the price of its Gulfstream G550 jet by £3.5m in an attempt to shift it. The retailer has already sold three of its fleet of five jets since October but has cut the price of the 14-seater jet from $35m (£23.5m) to $30m. It also still has a Hawker 800XP. - - Getty - - - - 48/50 - - Uber called to account in Paris - - Uber’s Paris offices have been raided by French police as part of an investigation into its UberPOP service that lets anyone offer taxi rides. The French headquarters of the US taxi-booking app have been targeted by authorities as part of investigations into the feature, which is not available in the UK, that allows non-professional drivers to sign up - - Reuters - - - - 49/50 - - P&G on the scent of a sale? - - Procter & Gamble is believed to be looking at a sale or IPO of some of its beauty brands, which range from Herbal Essence shampoos to Olay creams and Boss perfumes (as advertised by Sienna Miller, pictured). Shares in the US consumer products giant rose 2 per cent on the prospect of a sale yesterday, even though P&G said the report, on Bloomberg, was “speculation” - - - - - 50/50 - - Blackpool pier is on sale for £12.6m - - Blackpool’s central pier has been put up for sale by its owner Cuerden as the attractions organiser looks to restructure its operations. The group is asking for offers of about £12.6m for a package of three piers – including Blackpool’s 19th-century central and southern piers and a third in Landudno in Wales - - Getty - - - - - - - - - - - 6. Mini bars almost always lose money - - Despite the snacks in the minibar seeming like the most overpriced food you have ever seen, hotel owners are still struggling to make a profit from those snacks. "Minibars almost always lose money, even when they charge $10 for a Diet Coke,” Sharon said. - - - - - - - - - - - Towels should always be cleaned between stays - - - - - 7. Always made sure the hand towels are clean when you arrive - - Forrest Jones made a discovery when he was helping out with the housekeepers. “You know where you almost always find a hand towel in any recently-vacated hotel room that was occupied by a guy? On the floor, next to the bed, about halfway down, maybe a little toward the foot of the bed. Same spot in the floor, next to almost every bed occupied by a man, in every room. I'll leave the rest to your imagination,” he said. - - - - More about: - - Hotels - Hygiene - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Reuse content - - - - - - - - - - - - - - by Taboola by Taboola - Sponsored Links Sponsored Links - Promoted Links Promoted Links - - - - - - - Babbel - - - 1,000,000 are using this app to learn a new languageBabbel - - - Undo - - - - Soldiers: Free Online Game - - - This Is The Most Addicting Game Of The YearSoldiers: Free Online Game - - - Undo - - - - Everykey - - - You Don't Need to Remember You Passwords Anymore T…Everykey - - - Undo - - - - Xtra-PC - - - Tiny Device Turns Old Computer into New Fast PCXtra-PC - - - Undo - - - - Sparta Free Online Game - - - Are you a strategic thinker? Test your skills with millions of addict…Sparta Free Online Game - - - Undo - - - - InsideGov — By Graphiq - - - Here Are the 15 Presidents with the Lowest IQ ScoresInsideGov — By Graphiq - - - Undo - - - - Save70 - - - That's How You Find Super Cheap Hotels!Save70 - - - Undo - - - - Rapid Reflux Relief eBook - - - The Silent Killer: Can Acid Reflux Become A Life Threatening Condi…Rapid Reflux Relief eBook - - - Undo - - - - Financial Times for CapGemini - - - What will cognitive computing change?Financial Times for CapGemini - - - Undo - - - - HealthGrove — By Graphiq - - - Here's Why These Are the Most Dangerous Countries for TravelHealthGrove — By Graphiq - - - Undo - - - - PrettyFamous — By Graphiq - - - Ranking Every Tom Hanks Film from Worst to FirstPrettyFamous — By Graphiq - - - Undo - - - - Reuters TV - - - Taliban Names Its New LeaderReuters TV - - - Undo - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Comments - - - - - - Login - - - - Login - Or - Guest - - - - - - - - (Logout) - - - - - - - - - - - - - - - - - - 0 Comments - - - Sort - Subscribe - RSS - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - Student Dies After Diet Pills She Bought Online “Burned Her Up From Within” - - An inquest into Eloise Parry’s death has been adjourned until July. - - - - - - - - - - - - - - - - posted on April 21, 2015, at 11:29 a.m. - - - - - - - - - - Mark Di Stefano - BuzzFeed News Reporter - - - - - - - - - - - - - - Tweet - - - - - - - - - - - - - - - - - Bookmark it - - - - - - - - - - - - - - - - - - - - - - - Tweet - - - - - - - - - - - - - Tweet - - - - - - - - - - - - - - - - - - - - - - - - - The mother of a woman who took suspected diet pills bought online has described how her daughter was “literally burning up from within” moments before her death. - - - - - - - - View this image › - - West Merica Police - - - Eloise Parry, 21, was taken to Royal Shrewsbury hospital on 12 April after taking a lethal dose of highly toxic “slimming tablets”. - “The drug was in her system, there was no anti-dote, two tablets was a lethal dose – and she had taken eight,” her mother, Fiona, said in a statement yesterday. - “As Eloise deteriorated, the staff in A&E did all they could to stabilise her. As the drug kicked in and started to make her metabolism soar, they attempted to cool her down, but they were fighting an uphill battle. - “She was literally burning up from within.” - She added: “They never stood a chance of saving her. She burned and crashed.” - - - - - - - - - - - - - - Facebook - - - - - - - - - - - - - Facebook - - - - - - - - West Mercia police said the tablets were believed to contain dinitrophenol, known as DNP, which is a highly toxic industrial chemical. - “We are undoubtedly concerned over the origin and sale of these pills and are working with partner agencies to establish where they were bought from and how they were advertised,” said chief inspector Jennifer Mattinson from the West Mercia police. - The Food Standards Agency warned people to stay away from slimming products that contained DNP. - “We advise the public not to take any tablets or powders containing DNP, as it is an industrial chemical and not fit for human consumption,” it said in a statement. - - - Fiona Parry issued a plea for people to stay away from pills containing the chemical. - - “[Eloise] just never really understood how dangerous the tablets that she took were,” she said. “Most of us don’t believe that a slimming tablet could possibly kill us. - “DNP is not a miracle slimming pill. It is a deadly toxin.” - - - Check out more articles on BuzzFeed.com! - - - Mark di Stefano is a breaking news reporter for BuzzFeed News and is based in Sydney, Australia. - - Contact Mark Di Stefano at mark.distefano@buzzfeed.com - - - - - - - - - - - - - - - - - - Tweet - - - - - - - - - - - - - - - - - - - - - - More ▾ - - - - - - - - Rebuzz - - - - - - - - - Stumble - - - - - - - - - - - - - - - - Facebook Conversations - - - - - - - - - - - - - - - - - - Next On BuzzFeed News › - - - The Bride Paradox Of "Four Weddings" - - - - - - - - - - - - Next On BuzzFeed News › - - - Rihanna And The Radical Power Of "Carefree Black Girl"... - - - - - - - - - - - - - - Next On BuzzFeed News › - - - This Is Why Streaking During A Rugby Match Is Never... - - - - - - - - - - - - Next On BuzzFeed News › - - - People In Nepal Are Letting Their Loved Ones Know They... - - - - - - - - - - - Saving... - - - Saving... - - - Saving... - - - Rebuzzed! This post has been added to your Feed - - - I know, right? And there’s more where that came from. - - - Totally! And there’s plenty more to love! - - - Broken hearted? Maybe you’ll like something over here instead? - - - - - I know, right? Will your friends agree? - Share this Link - - - - - - - Student Dies After Diet Pills She Bought Online "Burned Her Up From Within" - http://www.buzzfeed.com/markdistefano/diet-pill... - An inquest into Eloise Parry's death has been adjourned until July. - - - - - - - - Your link was successfully shared! - - - - - - - - - - - - EDIT - - - More Buzz - - - - - - - - Police Arrest Three Students And Use CS Spray During Anti-Fees Protest At Warwick - × - - - - Durham Student Newspaper Publishes Powerful Front Page Calling For Action After Student Drownings - × - - - - University College London Closed An Exhibition That Displayed Students’ Stories Of Sexual Harrassment - × - - - - Durham Student Rescued From River “Lucky To Be Alive” Following Deaths Of Three Others - × - - - - - - - Related Links - × - - - Note: once you save these links, they will no longer update automatically. - - 1. - - 2. - - 3. - - 4. - - - - - - - Save Changes - Cancel - - - - - - - - - EDIT - - - More Buzz - - - - - - - - Police Arrest Three Students And Use CS Spray During Anti-Fees Protest At Warwick - × - - - - Durham Student Newspaper Publishes Powerful Front Page Calling For Action After Student Drownings - × - - - - University College London Closed An Exhibition That Displayed Students’ Stories Of Sexual Harrassment - × - - - - Durham Student Rescued From River “Lucky To Be Alive” Following Deaths Of Three Others - × - - - - - - - Related Links - × - - - Note: once you save these links, they will no longer update automatically. - - 1. - - 2. - - 3. - - 4. - - - - - - - Save Changes - Cancel - - - - - - - - - - - - Facebook Conversations - - - - - -
- - - - - - - - - - - - - - - Twitter Lite estará disponible en Google Play Store en 11 países de América Latina. - Twitter - - - Twitter ha dado a conocer que Twitter Lite llegará a un total de 24 nuevos países a partir de hoy, 11 de ellos de América Latina. - Según explicó en un comunicado Twitter Lite ahora estará disponible en Bolivia, Brasil, Chile, Colombia, Costa Rica, Ecuador, México, Panamá, Perú, El Salvador y Venezuela. - Twitter Lite es la versión ligera de la aplicación de la red social para Android, disponible en la Google Play Store. Con este app los usuarios que experimentan fallos de red o que viven en países con redes con poca velocidad de conexión como Venezuela podrán descargar los tuits de forma más rápida. - - Artículos Relacionados - - Este es el hombre que eliminó la cuenta de Twitter de Trump - Twitter muestra avances de Bookmarks, su herramienta para guardar enlaces - Twitter mostrará cuántas personas están hablando sobre un mismo tuit - - - Entre sus novedades, Twitter Lite permite la carga rápida de tuits en redes 2G y 3G, y ofrece ayuda offline en caso de que pierdas tu conexión; a eso debemos sumar que minimiza el uso de datos y ofrece un modo de ahorro, en el que únicamente se descargan las fotos o videos de los tuits que quieres ver. - - - - - - - Además, el app ocupa menos espacio en tu teléfono móvil, al reducir a 3MB su peso. - Twitter dio a conocer Twitter Lite en abril en India, y desde entonces ha estado trabajando para llevarlo a más países. La empresa en los últimos meses también se ha involucrado de forma definitiva en la eliminación de los abusos en la red social, tomando medidas incluso en la verificación de cuentas. - - - - - - - Reproduciendo: Mira esto: Google Assistant mejora, hay más cambios en Twitter y... - - 8:09 - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - Tech Industry - - - - - - - - - - - by - - - Steven Musil - - - - January 18, 2017 11:00 PM PST - - - - - - - - - @stevenmusil - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Up Next - - Governments suck at social media, but you deserve some blame - - - - - - - - - - - Facebook CEO Mark Zuckerberg, the man with the acquisition plan.Photo by James Martin/CNET - - - Anyone who has ever been involved in closing a billion-dollar acquisition deal will tell you that you don't go in without a clear, well thought out plan. - - - ADVERTISING - - inRead invented by Teads - - - Facebook CEO Mark Zuckerberg knows a thing or two about how to seal the deal on blockbuster buys. After all, he's the man behind his company's $19 billion acquisition of WhatsApp, he personally brokered its $1 billion buyout of Instagram and closed the $3 billion deal to buy Oculus VR. - Zuckerberg offered a primer on the strategies he and his company employ when they see an attractive target during testimony Tuesday in a lawsuit with ZeniMax Media, which accuses Oculus and Facebook of "misappropriating" trade secrets and copyright infringement. At the heart of the lawsuit is technology that helped create liftoff for virtual reality, one of the hottest gadget trends today. - A key Facebook approach is building a long-term relationship with your target, Zuckerberg said at the trial. These deals don't just pop up over night, he said according to a transcript reviewed by Business Insider. They take time to cultivate. - - I've been building relationships, at least in Instagram and the WhatsApp cases, for years with the founders and the people that are involved in these companies, which made [it] so that when it became time or when we thought it was the right time to move, we felt like we had a good amount of context and had good relationships so that we could move quickly, which was competitively important and why a lot of these acquisitions, I think, came to us instead of our competitors and ended up being very good acquisitions over time that a lot of competitors wished they had gotten instead. - - He also stressed the need assure your target that you have a shared vision about how you will collaborate after the deal is put to bed. Zuckerberg said this was reason Facebook was able to acquire Oculus for less than its original $4 billion asking price. - If this [deal] is going to happen, it's not going to be because we offer a lot of money, although we're going to have to offer a fair price for the company that is more than what they felt like they could do on their own. But they also need to feel like this was actually going to help their mission. - - - - - - - - - When that doesn't work, Zuckerberg said scare tactics is an effective, if undesirable, way of persuading small startups that they face a better chance of survival if they have Facebook to guide their way rather than going it alone. - That's less my thing, but I think if you are trying to help convince people that they want to join you, helping them understand all the pain that they would have to go through to build it out independently is a valuable tactic. - It also pays to be weary of competing suitors for your startup, Zuckerberg said, and be willing to move fast to stave off rivals and get the deal done. - Often, if a company knows we're offering something, they will offer more. So being able to move quickly not only increases our chance of being able to get a deal done if we want to, but it makes it so we don't have end up having to pay a lot more because the process drags out. - It wasn't clear why these strategies didn't work on Snapchat CEO Evan Spiegel, who famously rebuffed a $3 billion takeover offer from Facebook in 2013. - - - - - - - - - Tech Enabled: CNET chronicles tech's role in providing new kinds of accessibility. Check it out here. - Technically Literate: Original works of short fiction with unique perspectives on tech, exclusively on CNET. Here. - - - - - - - - - - - Taboola Taboola - Sponsored Links by Sponsored Links by - Promoted Links Promoted Links - YOU MAY ALSO LIKE - - - - - - - <span class=firstTabBranding>Sponsored by </span>TrackR Bravo - - - Best Tracking Device Ever is Selling Like CrazySponsored by TrackR Bravo - - - Undo - - - - <span class=firstTabBranding>Sponsored by </span>Lumify X9 - - - Crazy Cheap Flashlight - Selling Like Hotcakes!Sponsored by Lumify X9 - - - Undo - - - - <span class=firstTabBranding>Sponsored by </span>Babbel - - - How this app teaches you a language in 3 weeks!Sponsored by Babbel - - - Undo - - - - <span class=firstTabBranding>Sponsored by </span>Save70.com - - - The Ultimate Way to Get Cheap Hotel RoomsSponsored by Save70.com - - - Undo - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - Replay - - - - - - - The priest saving LA's gang members - Your video will play in 00:25 - - - - - - - - - - - - - - - - The U.S. has long been heralded as a land of opportunity -- a place where anyone can succeed regardless of the economic class they were born into. - But a new report released on Monday by Stanford University's Center on Poverty and Inequality calls that into question. - - - - The report assessed poverty levels, income and wealth inequality, economic mobility and unemployment levels among 10 wealthy countries with social welfare programs. - - - - - - - - - - - - Powered by SmartAsset.com - - - - - - Disclosures - SmartAsset.com - - - - - - - - - - - - Among its key findings: the class you're born into matters much more in the U.S. than many of the other countries. - As the report states: "[T]he birth lottery matters more in the U.S. than in most well-off countries." - - - - But this wasn't the only finding that suggests the U.S. isn't quite living up to its reputation as a country where everyone has an equal chance to get ahead through sheer will and hard work. - Related: Rich are paying more in taxes but not as much as they used to - - - ADVERTISING - - inRead invented by Teads - - - The report also suggested the U.S. might not be the "jobs machine" it thinks it is, when compared to other countries. - It ranked near the bottom of the pack based on the levels of unemployment among men and women of prime working age. The study determined this by taking the ratio of employed men and women between the ages of 25 and 54 compared to the total population of each country. - The overall rankings of the countries were as follows: 1. Finland 2. Norway 3. Australia 4. Canada 5. Germany 6. France 7. United Kingdom 8. Italy 9. Spain 10. United States - - - - - - - - - - The low ranking the U.S. received was due to its extreme levels of wealth and income inequality and the ineffectiveness of its "safety net" -- social programs aimed at reducing poverty. - Related: Chicago is America's most segregated city - The report concluded that the American safety net was ineffective because it provides only half the financial help people need. Additionally, the levels of assistance in the U.S. are generally lower than in other countries. - - - CNNMoney (New York) First published February 1, 2016: 1:28 AM ET - - - - - - - -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. - Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. - Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- - - - Graduation parties are a great way to commemorate the years of hard work teens and college co-eds devote to education. They’re also costly for mom and dad. - The average cost of a graduation party in 2013 was a whopping $1,200, according to Graduationparty.com; $700 of that was allocated for food. However that budget was based on Midwestern statistics, and parties in urban areas like New York City are thought to have a much higher price tag. - Thankfully, there are plenty of creative ways to trim a little grad party fat without sacrificing any of the fun or celebratory spirit. - - - - - - (Mike Watson Images/Moodboard/Getty) - - - - - - - - Parties hosted at restaurants, clubhouses and country clubs eliminate the need to spend hours cleaning up once party guests have gone home. But that convenience comes with a price tag. A country club may charge as much as $2,000 for room rental and restaurant food and beverage will almost always cost more than food prepped and served at home. - - - - - - Thomas Jackson/Digital Vision/Getty Images - - - - - - - - Instead of hiring a DJ, use your iPod or Smartphone to spin the tunes. Both easily hook up to most speakers or mp3 compatible docks to play music from your music library. Or download Pandora, the free online radio app, and play hours of music for free. Personalize the music with a playlist of the grad’s favorite songs or songs that were big hits during his or her years in school. - - - - - - Spencer Platt/Getty Images News/Getty Images - - - - - - - - Avoid canned drinks, which guests often open, but don't finish. Serve pitchers of tap water with lemon and cucumber slices or sliced strawberries for an interesting and refreshing flavor. Opt for punches and non-alcoholic drinks for high school graduates that allow guests to dole out the exact amount they want to drink. - - - - - - evgenyb/iStock/Getty Images - - - - - - - - Instead of inviting everyone you – and the graduate – know or ever knew, scale back the guest list. Forgo inviting guests that you or your grad haven't seen for eons. There is no reason to provide provisions for people who are essentially out of your lives. Sticking to a small, but personal, guest list allows more time to mingle with loved ones during the party, too. - - - - - - Kane Skennar/Photodisc/Getty Images - - - - - - - - See if your grad and his best friend, girlfriend or close family member would consider hosting a joint party. You can split some of the expenses, especially when the two graduates share mutual friends. You'll also have another parent to bounce ideas off of and to help you stick to your budget when you're tempted to splurge. - - - - - - Mike Watson Images/Moodboard/Getty - - - - - - - - Skip carving stations of prime rib and jumbo shrimp as appetizers, especially for high school graduation parties. Instead, serve some of the graduate's favorite side dishes that are cost effective, like a big pot of spaghetti with breadsticks. Opt for easy and simple food such as pizza, finger food and mini appetizers. Avoid pre-packaged foods and pre-made deli platters. These can be quite costly. Instead, make your own cheese and deli platters for less than half the cost of pre-made. - - - - - - Mark Stout/iStock/Getty Images - - - - - - - - Instead of an evening dinner party, host a grad lunch or all appetizers party. Brunch and lunch fare or finger food costs less than dinner. Guests also tend to consume less alcohol in the middle of the day, which keeps cost down. - - - - - - Mark Stout/iStock/Getty Images - - - - - - - - Decorate your party in the graduate's current school colors or the colors of the school he or she will be headed to next. Décor that is not specifically graduation-themed may cost a bit less, and any leftovers can be re-used for future parties, picnics and events. - - - - - - jethuynh/iStock/Getty Images - - - - Related Searches - Promoted By Zergnet -
- - - - Graduation parties are a great way to commemorate the years of hard work teens and college co-eds devote to education. They’re also costly for mom and dad. - The average cost of a graduation party in 2013 was a whopping $1,200, according to Graduationparty.com; $700 of that was allocated for food. However that budget was based on Midwestern statistics, and parties in urban areas like New York City are thought to have a much higher price tag. - Thankfully, there are plenty of creative ways to trim a little grad party fat without sacrificing any of the fun or celebratory spirit. - - - - - - (Mike Watson Images/Moodboard/Getty) - - - - - - - - - - - - -Parties hosted at restaurants, clubhouses and country clubs eliminate the need to spend hours cleaning up once party guests have gone home. But that convenience comes with a price tag. A country club may charge as much as $2,000 for room rental and restaurant food and beverage will almost always cost more than food prepped and served at home. - - - - - Thomas Jackson/Digital Vision/Getty Images - - - - - - - - - -Instead of hiring a DJ, use your iPod or Smartphone to spin the tunes. Both easily hook up to most speakers or mp3 compatible docks to play music from your music library. Or download Pandora, the free online radio app, and play hours of music for free. -Personalize the music with a playlist of the grad’s favorite songs or songs that were big hits during his or her years in school. - - - - - Spencer Platt/Getty Images News/Getty Images - - - - - - - - - -Avoid canned drinks, which guests often open, but don't finish. Serve pitchers of tap water with lemon and cucumber slices or sliced strawberries for an interesting and refreshing flavor. Opt for punches and non-alcoholic drinks for high school graduates that allow guests to dole out the exact amount they want to drink. - - - - - evgenyb/iStock/Getty Images - - - - - - - - - - - - - - - -Instead of inviting everyone you – and the graduate – know or ever knew, scale back the guest list. Forgo inviting guests that you or your grad haven't seen for eons. There is no reason to provide provisions for people who are essentially out of your lives. Sticking to a small, but personal, guest list allows more time to mingle with loved ones during the party, too. - - - - - Kane Skennar/Photodisc/Getty Images - - - - - - - - - -See if your grad and his best friend, girlfriend or close family member would consider hosting a joint party. You can split some of the expenses, especially when the two graduates share mutual friends. You'll also have another parent to bounce ideas off of and to help you stick to your budget when you're tempted to splurge. - - - - - Mike Watson Images/Moodboard/Getty - - - - - - - - - -Skip carving stations of prime rib and jumbo shrimp as appetizers, especially for high school graduation parties. Instead, serve some of the graduate's favorite side dishes that are cost effective, like a big pot of spaghetti with breadsticks. Opt for easy and simple food such as pizza, finger food and mini appetizers. -Avoid pre-packaged foods and pre-made deli platters. These can be quite costly. Instead, make your own cheese and deli platters for less than half the cost of pre-made. - - - - - Mark Stout/iStock/Getty Images - - - - - - - - - -Instead of an evening dinner party, host a grad lunch or all appetizers party. Brunch and lunch fare or finger food costs less than dinner. Guests also tend to consume less alcohol in the middle of the day, which keeps cost down. - - - - - Mark Stout/iStock/Getty Images - - - - - Other People Are Reading - - - - - - How to Throw a High School Graduation Party on a Budget - - - - - Cheap Graduation Party Meal Ideas - - - - - - - - - - - -Decorate your party in the graduate's current school colors or the colors of the school he or she will be headed to next. Décor that is not specifically graduation-themed may cost a bit less, and any leftovers can be re-used for future parties, picnics and events. - - - - - jethuynh/iStock/Getty Images - - - - - - - - - - - Related Searches - - - - - - Promoted By Zergnet - - Comments - - - Please enable JavaScript to view the comments powered by Disqus. - -
- Lorem - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Videos - At root - - - - In a paragraph - - In a div - - Foo - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Videos - At root - - - - In a paragraph - - In a div - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- 08.04.2015 12:46 - - - 1Password für Mac generiert Einmal-Passwörter - - - - - - - - - 1Password scannt auch QR-Codes. - - - (Bild: Hersteller) - - - - - - - - Das in der iOS-Version bereits enthaltene TOTP-Feature ist nun auch für OS X 10.10 verfügbar. Zudem gibt es neue Zusatzfelder in der Datenbank und weitere Verbesserungen. - AgileBits hat Version 5.3 seines bekannten Passwortmanagers 1Password für OS X freigegeben. Mit dem Update wird eine praktische Funktion nachgereicht, die die iOS-Version der Anwendung bereits seit längerem beherrscht: Das direkte Erstellen von Einmal-Passwörtern. Unterstützt wird dabei der TOTP-Standard (Time-Based One-Time Passwords), den unter anderem Firmen wie Evernote, Dropbox oder Google einsetzen, um ihre Zugänge besser abzusichern. Neben Account und regulärem Passwort wird dabei dann ein Zusatzcode verlangt, der nur kurze Zeit gilt. -Zur TOTP-Nutzung muss zunächst ein Startwert an 1Password übergeben werden. Das geht unter anderem per QR-Code, den die App über ein neues Scanfenster selbst einlesen kann – etwa aus dem Webbrowser. Eine Einführung in die Technik gibt ein kurzes Video. Die TOTP-Unterstützung in 1Password erlaubt es, auf ein zusätzliches Gerät (z.B. ein iPhone) neben dem Mac zu verzichten, das den Code liefert – was allerdings auch die Sicherheit verringert, weil es keinen "echten" zweiten Faktor mehr gibt. -Update 5.3 des Passwortmanagers liefert auch noch weitere Verbesserungen. So gibt es die Möglichkeit, FaceTime-Audio- oder Skype-Anrufe aus 1Password zu starten, die Zahl der Zusatzfelder in der Datenbank wurde erweitert und der Umgang mit unterschiedlichen Zeitzonen klappt besser. Die Engine zur Passworteingabe im Browser soll beschleunigt worden sein. -1Password kostet aktuell knapp 50 Euro im Mac App Store und setzt in seiner aktuellen Version mindestens OS X 10.10 voraus. - - - -(bsc) - - - - - - - - - - - -
- - - - - - - - - Getting LEAN with Digital Ad UX - 10.15.15 - By - Scott Cunningham - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - We messed up. As technologists, tasked with delivering content and services to users, we lost track of the user experience. -Twenty years ago we saw an explosion of websites, built by developers around the world, providing all forms of content. This was the beginning of an age of enlightenment, the intersection of content and technology. Many of us in the technical field felt compelled, and even empowered, to produce information as the distribution means for mass communication were no longer restricted by a high barrier to entry. -In 2000, the dark ages came when the dot-com bubble burst. We were told that our startups were gone or that our divisions sustained by corporate parent companies needed to be in the black. It was a wakeup call that led to a renaissance age. Digital advertising became the foundation of an economic engine that, still now, sustains the free and democratic World Wide Web. In digital publishing, we strived to balance content, commerce, and technology. The content management systems and communication gateways we built to inform and entertain populations around the world disrupted markets and in some cases governments, informed communities of imminent danger, and liberated new forms of art and entertainment—all while creating a digital middle class of small businesses. -We engineered not just the technical, but also the social and economic foundation that users around the world came to lean on for access to real time information. And users came to expect this information whenever and wherever they needed it. And more often than not, for anybody with a connected device, it was free. -This was choice—powered by digital advertising—and premised on user experience. -But we messed up. -Through our pursuit of further automation and maximization of margins during the industrial age of media technology, we built advertising technology to optimize publishers’ yield of marketing budgets that had eroded after the last recession. Looking back now, our scraping of dimes may have cost us dollars in consumer loyalty. The fast, scalable systems of targeting users with ever-heftier advertisements have slowed down the public internet and drained more than a few batteries. We were so clever and so good at it that we over-engineered the capabilities of the plumbing laid down by, well, ourselves. This steamrolled the users, depleted their devices, and tried their patience. -The rise of ad blocking poses a threat to the internet and could potentially drive users to an enclosed platform world dominated by a few companies. We have let the fine equilibrium of content, commerce, and technology get out of balance in the open web. We had, and still do have, a responsibility to educate the business side, and in some cases to push back. We lost sight of our social and ethical responsibility to provide a safe, usable experience for anyone and everyone wanting to consume the content of their choice. -We need to bring that back into alignment, starting right now. -Today, the IAB Tech Lab is launching the L.E.A.N. Ads program. Supported by the Executive Committee of the IAB Tech Lab Board, IABs around the world, and hundreds of member companies, L.E.A.N. stands for Light, Encrypted, Ad choice supported, Non-invasive ads. These are principles that will help guide the next phases of advertising technical standards for the global digital advertising supply chain. -As with any other industry, standards should be created by non-profit standards-setting bodies, with many diverse voices providing input. We will invite all parties for public comment, and make sure consumer interest groups have the opportunity to provide input. -L.E.A.N. Ads do not replace the current advertising standards many consumers still enjoy and engage with while consuming content on our sites across all IP enabled devices. Rather, these principles will guide an alternative set of standards that provide choice for marketers, content providers, and consumers. -Among the many areas of concentration, we must also address frequency capping on retargeting in Ad Tech and make sure a user is targeted appropriately before, but never AFTER they make a purchase. If we are so good at reach and scale, we can be just as good, if not better, at moderation. Additionally, we must address volume of ads per page as well as continue on the path to viewability. The dependencies here are critical to an optimized user experience. -The consumer is demanding these actions, challenging us to do better, and we must respond. -The IAB Tech Lab will continue to provide the tools for publishers in the digital supply chain to have a dialogue with users about their choices so that content providers can generate revenue while creating value. Publishers should have the opportunity to provide rich advertising experiences, L.E.A.N. advertising experiences, and subscription services. Or publishers can simply deny their service to users who choose to keep on blocking ads. That is all part of elasticity of consumer tolerance and choice. -Finally, we must do this in an increasingly fragmented market, across screens. We must do this in environments where entire sites are blocked, purposefully or not. Yes, it is disappointing that our development efforts will have to manage with multiple frameworks while we work to supply the economic engine to sustain an open internet. However, our goal is still to provide diverse content and voices to as many connected users as possible around the world. -That is user experience. - - - - -IAB Tech Lab Members can join the IAB Tech Lab Ad Blocking Working Group, please email adblocking@iab.com for more information. - - - -Read more about ad blocking here. - - - - - -
- - - - IAB Tech Lab Releases Updated ‘IAB HTML5 for Digital Advertising Guide’ for Public Comment - - 09.28.15 - - - -
- - - - - - IAB CEO Randall Rothenberg on Ad Blocking, Viewability, & Fraud in The Wall Street Journal - - 09.21.15 - - - -
- - - - IAB Tech Lab Releases Updated ‘Digital Video In-Stream Ad Format Guidelines & Best Practices... - - 09.16.15 - - - -
- - - - IAB Tech Lab Releases Updated ‘IAB Display Creative Guidelines’ For Public Comment - - 08.17.15 - - - -
- - - - - - - - - - - - - - - - - - - - - Inside the Deep Web Drug Lab - - - - Welcome to DoctorX’s Barcelona lab, where the drugs you bought online are tested for safety and purity. No questions asked. - - - - - - - - - - Standing at a table in a chemistry lab in Barcelona, Cristina Gil Lladanosa - tears open a silver, smell-proof protective envelope. She slides out a - transparent bag full of crystals. Around her, machines whir and hum, and - other researchers mill around in long, white coats. - She is holding the lab’s latest delivery of a drug bought from the “deep - web,” the clandestine corner of the internet that isn’t reachable by normal - search engines, and is home to some sites that require special software - to access. Labeled as MDMA (the street - term is ecstasy), this sample has been shipped from Canada. Lladanosa and - her colleague Iván Fornís Espinosa have also received drugs, anonymously, - from people in China, Australia, Europe and the United States. - “Here we have speed, MDMA, cocaine, pills,” Lladanosa says, pointing to - vials full of red, green, blue and clear solutions sitting in labeled boxes. - - - - - - - - Cristina Gil Lladanosa, at the Barcelona testing lab | photo by Joan Bardeletti - - - - Since 2011, with the launch of Silk Road, anybody has been able to safely buy illegal - drugs from the deep web and have them delivered to their door. Though the - FBI shut down that black market in October 2013, other outlets have emerged - to fill its role. For the last 10 months the lab at which Lladanosa and - Espinosa work has offered a paid testing service of those drugs. By sending - in samples for analysis, users can know exactly what it is they are buying, - and make a more informed decision about whether to ingest the substance. - The group, called Energy Control, - which has being running “harm reduction” programs since 1999, is the first - to run a testing service explicitly geared towards verifying those purchases - from the deep web. - Before joining Energy Control, Lladanosa briefly worked at a pharmacy, - whereas Espinosa spent 14 years doing drug analysis. Working at Energy - Control is “more gratifying,” and “rewarding” than her previous jobs, Lladanosa - told me. They also receive help from a group of volunteers, made up of - a mixture of “squatters,” as Espinosa put it, and medical students, who - prepare the samples for testing. - After weighing out the crystals, aggressively mixing it with methanol - until dissolved, and delicately pouring the liquid into a tiny brown bottle, - Lladanosa, a petite woman who is nearly engulfed by her lab coat, is now - ready to test the sample. She loads a series of three trays on top of a - large white appliance sitting on a table, called a gas chromatograph (GC). - A jungle of thick pipes hang from the lab’s ceiling behind it. - - - - - - - - Photo by Joan Bardeletti - - - - “Chromatography separates all the substances,” Lladanosa says as she loads - the machine with an array of drugs sent from the deep web and local Spanish - users. It can tell whether a sample is pure or contaminated, and if the - latter, with what. - Rushes of hot air blow across the desk as the gas chromatograph blasts - the sample at 280 degrees Celsius. Thirty minutes later the machine’s robotic - arm automatically moves over to grip another bottle. The machine will continue - cranking through the 150 samples in the trays for most of the work week. - - - - - - - - Photo by Joan Bardeletti - - - - To get the drugs to Barcelona, a user mails at least 10 milligrams of - a substance to the offices of the Asociación Bienestar y Desarrollo, the - non-government organization that oversees Energy Control. The sample then - gets delivered to the testing service’s laboratory, at the Barcelona Biomedical - Research Park, a futuristic, seven story building sitting metres away from - the beach. Energy Control borrows its lab space from a biomedical research - group for free. - The tests cost 50 Euro per sample. Users pay, not surprisingly, with Bitcoin. - In the post announcing Energy Control’s service on the deep web, the group - promised that “All profits of this service are set aside of maintenance - of this project.” - About a week after testing, those results are sent in a PDF to an email - address provided by the anonymous client. - “The process is quite boring, because you are in a routine,” Lladanosa - says. But one part of the process is consistently surprising: that moment - when the results pop up on the screen. “Every time it’s something different.” - For instance, one cocaine sample she had tested also contained phenacetin, - a painkiller added to increase the product’s weight; lidocaine, an anesthetic - that numbs the gums, giving the impression that the user is taking higher - quality cocaine; and common caffeine. - - - - - - - The deep web drug lab is the brainchild of Fernando Caudevilla, a Spanish - physician who is better known as “DoctorX” on the deep web, a nickname - given to him by his Energy Control co-workers because of his earlier writing - about the history, risks and recreational culture of MDMA. In the physical - world, Caudevilla has worked for over a decade with Energy Control on various - harm reduction focused projects, most of which have involved giving Spanish - illegal drug users medical guidance, and often writing leaflets about the - harms of certain substances. - - - - - - - - Fernando Caudevilla, AKA DoctorX. Photo: Joseph Cox - - - - Caudevilla first ventured into Silk Road forums in April 2013. “I would - like to contribute to this forum offering professional advice in topics - related to drug use and health,” he wrote in an introductory post, - using his DoctorX alias. Caudevilla offered to provide answers to questions - that a typical doctor is not prepared, or willing, to respond to, at least - not without a lecture or a judgment. “This advice cannot replace a complete - face-to-face medical evaluation,” he wrote, “but I know how difficult it - can be to talk frankly about these things.” - The requests flooded in. A diabetic asked what effect MDMA has on blood - sugar; another what the risks of frequent psychedelic use were for a young - person. Someone wanted to know whether amphetamine use should be avoided - during lactation. In all, Fernando’s thread received over 50,000 visits - and 300 questions before the FBI shut down Silk Road. - “He’s amazing. A gift to this community,” one user wrote on the Silk Road - 2.0 forum, a site that sprang up after the original. “His knowledge is - invaluable, and never comes with any judgment.” Up until recently, Caudevilla - answered questions on the marketplace “Evolution.” Last week, however, - the administrators of that site pulled a scam, - shutting the market down and escaping with an estimated $12 million worth - of Bitcoin. - Caudevilla’s transition from dispensing advice to starting up a no-questions-asked - drug testing service came as a consequence of his experience on the deep - web. He’d wondered whether he could help bring more harm reduction services - to a marketplace without controls. The Energy Control project, as part - of its mandate of educating drug users and preventing harm, had already - been carrying out drug testing for local Spanish users since 2001, at music - festivals, night clubs, or through a drop-in service at a lab in Madrid. - “I thought, we are doing this in Spain, why don’t we do an international - drug testing service?” Caudevilla told me when I visited the other Energy - Control lab, in Madrid. Caudevilla, a stocky character with ear piercings - and short, shaved hair, has eyes that light up whenever he discusses the - world of the deep web. Later, via email, he elaborated that it was not - a hard sell. “It was not too hard to convince them,” he wrote me. Clearly, - Energy Control believed that the reputation he had earned as an unbiased - medical professional on the deep web might carry over to the drug analysis - service, where one needs to establish “credibility, trustworthiness, [and] - transparency,” Caudevilla said. “We could not make mistakes,” he added. - - - - - - - - Photo: Joseph Cox - - - - - - - - - - While the Energy Control lab in Madrid lab only tests Spanish drugs from - various sources, it is the Barcelona location which vets the substances - bought in the shadowy recesses of of the deep web. Caudevilla no longer - runs it, having handed it over to his colleague Ana Muñoz. She maintains - a presence on the deep web forums, answers questions from potential users, - and sends back reports when they are ready. - The testing program exists in a legal grey area. The people who own the - Barcelona lab are accredited to experiment with and handle drugs, but Energy - Control doesn’t have this permission itself, at least not in writing. - “We have a verbal agreement with the police and other authorities. They - already know what we are doing,” Lladanosa tells me. It is a pact of mutual - benefit. Energy Control provides the police with information on batches - of drugs in Spain, whether they’re from the deep web or not, Espinosa says. - They also contribute to the European Monitoring Centre for Drugs and Drug - Addiction’s early warning system, a collaboration that attempts to spread - information about dangerous drugs as quickly as possible. - By the time of my visit in February, Energy Control had received over - 150 samples from the deep web and have been receiving more at a rate of - between 4 and 8 a week. Traditional drugs, such as cocaine and MDMA, make - up about 70 percent of the samples tested, but the Barcelona lab has also - received samples of the prescription pill codeine, research chemicals and - synthetic cannabinoids, and even pills of Viagra. - - - - - - - - Photo by Joan Bardeletti - - - - So it’s fair to make a tentative judgement on what people are paying for - on the deep web. The verdict thus far? Overall, drugs on the deep web appear - to be of much higher quality than those found on the street. - “In general, the cocaine is amazing,” says Caudevilla, saying that the - samples they’ve seen have purities climbing towards 80 or 90 percent, and - some even higher. To get an idea of how unusual this is, take a look at - the United Nations Office on Drugs and Crime World Drug Report 2014, - which reports that the average quality of street cocaine in Spain is just - over 40 percent, while in the United Kingdom it is closer to 30 percent.“We - have found 100 percent [pure] cocaine,” he adds. “That’s really, really - strange. That means that, technically, this cocaine has been purified, - with clandestine methods.” - Naturally, identifying vendors who sell this top-of-the-range stuff is - one of the reasons that people have sent samples to Energy Control. Caudevilla - was keen to stress that, officially, Energy Control’s service “is not intended - to be a control of drug quality,” meaning a vetting process for identifying - the best sellers, but that is exactly how some people have been using it. - As one buyer on the Evolution market, elmo666, wrote to me over the site’s - messaging system, “My initial motivations were selfish. My primary motivation - was to ensure that I was receiving and continue to receive a high quality - product, essentially to keep the vendor honest as far as my interactions - with them went.” - Vendors on deep web markets advertise their product just like any other - outlet does, using flash sales, gimmicky giveaways and promises of drugs - that are superior to those of their competitors. The claims, however, can - turn out to be empty: despite the test results that show that deep web - cocaine vendors typically sell product that is of a better quality than - that found on the street, in plenty of cases, the drugs are nowhere near - as pure as advertised. - “You won’t be getting anything CLOSE to what you paid for,” one user complained - about the cocaine from ‘Mirkov’, a vendor on Evolution. “He sells 65% not - 95%.” - - - - - - - - Photo by Joan Bardeletti - - - - - - - - - - Despite the prevalence of people using the service to gauge the quality - of what goes up their nose, many users send samples to Energy Control in - the spirit of its original mission: keeping themselves alive and healthy. - The worst case scenario from drugs purchased on the deep web is, well the - worst case. That was the outcome when Patrick McMullen, a - 17-year-old Scottish student, ingested half a gram of MDMA and three tabs - of LSD, reportedly purchased from the Silk Road. While talking to his friends - on Skype, his words became slurred and he passed out. Paramedics could - not revive him. The coroner for that case, Sherrif Payne, who deemed the - cause of death ecstasy toxicity, told The Independent “You - never know the purity of what you are taking and you can easily come unstuck.” - ScreamMyName, a deep web user who has been active since the original Silk - Road, wants to alert users to the dangerous chemicals that are often mixed - with drugs, and is using Energy Control as a means to do so. - “We’re at a time where some vendors are outright sending people poison. - Some do it unknowingly,” ScreamMyName told me in an encrypted message. - “Cocaine production in South America is often tainted with either levamisole - or phenacetine. Both poison to humans and both with severe side effects.” - In the case of Levamisole, those prescribing it are often not doctors - but veterinarians, as Levamisole is commonly used on animals, primarily - for the treatment of worms. If ingested by humans it can lead to cases - of extreme eruptions of the skin, as documented in a study from researchers at the University - of California, San Francisco. But Lladanosa has found Levamisole in cocaine - samples; dealers use it to increase the product weight, allowing them to - stretch their batch further for greater profit — and also, she says, because - Levamisole has a strong stimulant effect. - “It got me sick as fuck,” Dr. Feel, an Evolution user, wrote on the site’s - forums after consuming cocaine that had been cut with 23 percent Levamisole, - and later tested by Energy Control. “I was laid up in bed for several days - because of that shit. The first night I did it, I thought I was going to - die. I nearly drove myself to the ER.” - “More people die because of tainted drugs than the drugs themselves,” - Dr. Feel added. “It’s the cuts and adulterants that are making people sick - and killing them.” - - - - - - - - Photo by Joan Bardeletti - - - - The particular case of cocaine cut with Levamisole is one of the reasons - that ScreamMyName has been pushing for more drug testing on the deep web - markets. “I recognize that drug use isn’t exactly healthy, but why exacerbate - the problem?” he told me when I contacted him after his post. “[Energy - Control] provides a way for users to test the drugs they’ll use and for - these very users to know what it is they’re putting in their bodies. Such - services are in very short supply.” - After sending a number of Energy Control tests himself, ScreamMyName started - a de facto crowd-sourcing campaign to get more drugs sent to the lab, and - then shared the results, after throwing in some cash to get the ball rolling. - He set up a Bitcoin wallet, with the hope that users might chip in - to fund further tests. At the time of writing, the wallet has received - a total of 1.81 bitcoins; around $430 at today’s exchange rates. - In posts to the Evolution community, ScreamMyName pitched this project - as something that will benefit users and keep drug dealer honest. “When - the funds build up to a point where we can purchase an [Energy Control] - test fee, we’ll do a US thread poll for a few days and try to cohesively - decide on what vendor to test,” he continued. - - - - - - - - Photo by Joan Bardeletti - - - - Other members of the community have been helping out, too. PlutoPete, - a vendor from the original Silk Road who sold cannabis seeds and other - legal items, has provided ScreamMyName with packaging to safely send the - samples to Barcelona. “A box of baggies, and a load of different moisture - barrier bags,” PlutoPete told me over the phone. “That’s what all the vendors - use.” - It’s a modest program so far. ScreamMyName told me that so far he had - gotten enough public funding to purchase five different Energy Control - tests, in addition to the ten or so he’s sent himself so far. “The program - created is still in its infancy and it is growing and changing as we go - along but I have a lot of faith in what we’re doing,” he says. - But the spirit is contagious: elmo666, the other deep web user testing - cocaine, originally kept the results of the drug tests to himself, but - he, too, saw a benefit to distributing the data. “It is clear that it is - a useful service to other users, keeping vendors honest and drugs (and - their users) safe,” he told me. He started to report his findings to others - on the forums, and then created a thread with summaries of the test results, - as well as comments from the vendors if they provided it. Other users were - soon basing their decisions on what to buy on elmo666‘s tests. - “I’m defo trying the cola based on the incredibly helpful elmo and his - energy control results and recommendations,” wrote user jayk1984. On top - of this, elmo666 plans to launch an independent site on the deep web that - will collate all of these results, which should act as a resource for users - of all the marketplaces. - As word of elmo666's efforts spread, he began getting requests from drug - dealers who wanted him to use their wares for testing. Clearly, they figured - that a positive result from Energy Control would be a fantastic marketing - tool to draw more customers. They even offered elmo666 free samples. (He - passed.) - Meanwhile, some in the purchasing community are arguing that those running - markets on the deep web should be providing quality control themselves. - PlutoPete told me over the phone that he had been in discussions about - this with Dread Pirate Roberts, the pseudonymous owner of the original - Silk Road site. “We [had been] talking about that on a more organized basis - on Silk Road 1, doing lots of anonymous buys to police each category. But - of course they took the thing [Silk Road] down before we got it properly - off the ground,” he lamented. - But perhaps it is best that the users, those who are actually consuming - the drugs, remain in charge of shaming dealers and warning each other. - “It’s our responsibility to police the market based on reviews and feedback,” - elmo666 wrote in an Evolution forum post. It seems that in the lawless - space of the deep web, where everything from child porn to weapons are - sold openly, users have cooperated in an organic display of self-regulation - to stamp out those particular batches of drugs that are more likely to - harm users. - “That’s always been the case with the deep web,” PlutoPete told me. Indeed, - ever since Silk Road, a stable of the drug markets has been the review - system, where buyers can leave a rating and feedback for vendors, letting - others know about the reliability of the seller. But DoctorX’s lab, rigorously - testing the products with scientific instruments, takes it a step further. - - - - - - - - Photo by Joan Bardeletti - - - - “In the white market, they have quality control. In the dark market, it - should be the same,” Cristina Gil Lladanosa says to me before I leave the - Barcelona lab. - A week after I visit the lab, the results of the MDMA arrive in my inbox: - it is 85 percent pure, with no indications of other active ingredients. - Whoever ordered that sample from the digital shelves of the deep web, and - had it shipped to their doorstep in Canada, got hold of some seriously - good, and relatively safe drugs. And now they know it. - - - - - - - Top photo by Joan Bardeletti - - Follow Backchannel: Twitter - |Facebook - - - - - - - - - - - RecommendRecommended - - - - - - - - BookmarkBookmarked - - Share - - More - - - - - - - - - - - - - Published inBackchannel - Mining the tech world for lively and meaningful tales and analysis. - - - - Follow by email - - - Email me when there are new stories in the publication - - - - Follow - - - - - - - - - - Written on - Mar 27 - byJoseph Cox - Encryption Enthusiast. Words for Motherboard, WIRED, Daily Dot. Documentaries - for VICE. OTR chat: jfcox@jabber.ccc.de - - - - Follow - Following - - - - - - Thanks to Steven Levy. - - - - - - - - - -
- - Una solución no violenta para la cuestión mapuche - Los pueblos indígenas reclaman por derechos que permanecen incumplidos, por eso es más eficiente canalizar la protesta que reprimirla - - - Abdullah Ocalan, el líder independentista kurdo, desembarcó en Italia en noviembre de 1998 y pidió asilo político. Arrastraba un pedido de captura de Turquía, donde era acusado por terrorismo. El ex comunista Massimo D'Alema, recién asumido, dudaba. Acoger a Ocalan implicaba comprarse un problema con un aliado de la OTAN e importar un conflicto ajeno, pero deportarlo lo exponía a la pena de muerte, legal en Turquía pero inadmisible en la Unión Europea. Optó por la estrecha avenida del medio: se ignoró el mandato de captura al tiempo que se negó el asilo, presionando a Ocalan para que se fuera por las suyas. Tras una carambola a tres bandas, fue capturado por agentes turcos en Kenia, donde se encontraba bajo la protección del embajador griego, mientras intentaba abordar un avión hacia Holanda. Desde febrero de 1999 permanece en una cárcel de máxima seguridad en la isla turca de Imrali. - Uno de los autores de esta columna vivía en Italia en esa época y siguió la crisis de cerca; el otro la estudió en profundidad, años más tarde. Pero no hacía falta: cualquiera puede encontrar esta información a un clic de distancia. Eso fue lo que no hizo un periodista de un diario argentino, que no es la nacion. La semana pasada se publicaron extractos de un "informe de carácter secreto" que mencionaba supuestos contactos internacionales de organizaciones mapuches. Entre ellos aparecía Ocalan, a quien el informe ubicó "con domicilios en Palermo y en el centro porteño", y aseguraba incluso que había sido visto "en Neuquén, Río Negro y Chubut durante el juicio a Jones Huala". - - - - - - - Foto: LA NACION - - - Esta falsa noticia fue la más rocambolesca de una larga cadena. Dos hechos quedaron en evidencia: primero, que hay periodistas que no chequean la información; segundo, que los servicios de inteligencia los utilizan para manipular la agenda pública. Y sobre los servicios hay dos posibilidades: o son burros o son perversos. Las opciones no son excluyentes, aunque cualquiera alcanza para tornarlos indignos de confianza. Sin embargo, de ellos proviene la información que alimenta a muchos medios de comunicación y, aún más grave, al Estado argentino. - El reguero de noticias falsas y vínculos brumosos tiene, paradójicamente, un objetivo prístino: asociar la acción de los grupos mapuches con el terrorismo internacional. Comunicadores, analistas y escritores alineados con el discurso oficial llegaron a relacionar las ideas de las organizaciones patagónicas con las de Estado Islámico (ISIS) de Irak y Siria. El terrorismo carece de definiciones consensuales y ha sido utilizado para emparentar cosas bien diferentes. Aunque el líder mapuche más radicalizado (y menos representativo) declare que propician "un proceso de construcción de autonomía sin pedirle permiso al Estado", vincular a un grupo que reclama tierras en la región de sus ancestros con otro que busca gobernar el mundo según sus normas religiosas y ha masacrado a miles de personas requiere de una operación intelectual tan audaz como inadecuada. - La asociación con el movimiento kurdo, en cambio, asoma menos inverosímil. Desde su arresto, Ocalan transformó su pensamiento: de una visión nacionalista con inspiración estalinista evolucionó al confederalismo democrático, una propuesta de organización comunal, ecologista, más apegada a las raíces locales que a las fronteras nacionales. Parece lógico que esas ideas resuenen en agrupamientos indígenas, que reivindican una organización anterior a la consolidación de los Estados sudamericanos. Los paralelos, sin embargo, terminan allí. En Chile, donde el conflicto ha tenido su desarrollo más dramático, la Sociedad de Fomento Agrícola denunció en 2014 que los insurrectos causaron daños por 10 millones de dólares y la muerte de tres agricultores y un carabinero a lo largo de 15 años; en la Argentina, por ahora, se registran actos de vandalismo, ocupaciones de tierras y cortes de rutas aislados. En contraste, el conflicto entre el Partido de los Trabajadores del Kurdistán y la República de Turquía se cobró cerca de 40.000 vidas en los años 90 y lleva más de 2000 desde la reanudación de hostilidades en 2015. - Consultada sobre esta desproporción, una fuente de los servicios nos la resumió así: "La estrategia de la Coordinadora Arauco-Malleco (CAM), de Chile, y ahora de la Resistencia Ancestral Mapuche (RAM), más que matar directamente, es realizar sabotajes, movilizaciones, ataques a iglesias y empresas y mucha prensa". ¡En Medio Oriente pagarían por un terrorismo así! Ningún hecho de violencia debe ser minimizado, pero las analogías no resisten prueba. - La "cuestión mapuche" es social antes que policial. La Constitución manda "reconocer la preexistencia étnica y cultural de los pueblos indígenas argentinos. Garantizar el respeto a su identidad?; reconocer la personería jurídica de sus comunidades, y la posesión y propiedad comunitarias de las tierras que tradicionalmente ocupan; y regular la entrega de otras aptas y suficientes para el desarrollo humano". Estos derechos permanecen incumplidos. Y no son un capricho chavista: los países que reputamos serios también los reconocen. En Estados Unidos, las reservaciones indígenas ocupan 80.000 kilómetros cuadrados, el 1,3% de la superficie del país (y 400 veces la superficie de la ciudad de Buenos Aires). En Canadá, unas 2300 reservas ocupan 28.000 kilómetros cuadrados. Australia otorga a los pueblos indígenas más de la mitad de los territorios del norte del país y son los nativos quienes negocian con las empresas mineras los permisos para que operen en sus tierras. En Nueva Zelanda existen tribunales especiales con jurisdicción sobre las tierras ancestrales de los maoríes; una de sus ventajas es que empoderan a los aborígenes individualmente, liberándolos del yugo de los caciques. - La protesta social es indisociable de la democracia. Cuando desborda, recanalizarla es más eficiente que reprimirla: ahí reside el arte del acuerdo. En la Argentina la tarea es delicada porque pocos confían en la imparcialidad de las instituciones. Entonces, cada actor reivindica sus intereses con los medios de que dispone: los sindicatos hacen huelga, los estudiantes toman colegios, los empresarios cierran las fábricas y todos hacen piquetes. El politólogo Samuel Huntington definía una sociedad así como pretoriana y el jurista Carlos Nino llamó a la Argentina "un país al margen de la ley". Al movilizarse por sus derechos y desconfiar del Estado, la comunidad mapuche se demuestra bien argentina. - Las cinco provincias patagónicas tienen una población similar a la de La Matanza. A diferencia de los Estados Unidos, que se integraron hacia el oeste otorgando parcelas de tierra a los colonizadores, y de Brasil, donde el rol de ocupación y desarrollo territorial fue cumplido por las fuerzas armadas, la Argentina obvió la tarea integradora tras consolidar su soberanía a finales del siglo XX. Hoy sobra tierra y falta gente. Gobernar sigue siendo poblar, pero también integrar. - Seamos claros: ningún individuo u organización tiene derecho a violar la ley. Pero el problema histórico del Estado argentino no fue tanto quiénes lo desafiaron como quiénes lo gobernaron. Cambiemos. - Andrés Malamud es politólogo e investigador en la Universidad de Lisboa. Martín Schapiro es abogado administrativista y analista internacional - - -
- Una solución no violenta para la cuestión - mapuche - Los pueblos indígenas reclaman por derechos que permanecen - incumplidos, por eso es más eficiente canalizar la protesta que reprimirla - - - - - - - - - - - - 0 - - - - Abdullah Ocalan, el líder independentista kurdo, desembarcó en Italia en noviembre de - 1998 y pidió asilo político. Arrastraba un pedido de captura de Turquía, donde era acusado por - terrorismo. El ex comunista Massimo D'Alema, recién asumido, dudaba. Acoger a Ocalan implicaba comprarse - un problema con un aliado de la OTAN e importar un conflicto ajeno, pero deportarlo lo exponía a la pena - de muerte, legal en Turquía pero inadmisible en la Unión Europea. Optó por la estrecha avenida del - medio: se ignoró el mandato de captura al tiempo que se negó el asilo, presionando a Ocalan para que se - fuera por las suyas. Tras una carambola a tres bandas, fue capturado por agentes turcos en Kenia, donde - se encontraba bajo la protección del embajador griego, mientras intentaba abordar un avión hacia - Holanda. Desde febrero de 1999 permanece en una cárcel de máxima seguridad en la isla turca de - Imrali. - Uno de los autores de esta columna vivía en Italia en esa época y siguió la crisis de cerca; el otro la - estudió en profundidad, años más tarde. Pero no hacía falta: cualquiera puede encontrar esta información - a un clic de distancia. Eso fue lo que no hizo un periodista de un diario argentino, que no es la - nacion. La semana pasada se publicaron extractos de un "informe de carácter secreto" que mencionaba - supuestos contactos internacionales de organizaciones mapuches. Entre ellos aparecía Ocalan, a quien el - informe ubicó "con domicilios en Palermo y en el centro porteño", y aseguraba incluso que había sido - visto "en Neuquén, Río Negro y Chubut durante el juicio a Jones Huala". - - - Foto: LA NACION - - - Esta falsa noticia fue la más rocambolesca de una larga cadena. Dos hechos quedaron en evidencia: - primero, que hay periodistas que no chequean la información; segundo, que los servicios de inteligencia - los utilizan para manipular la agenda pública. Y sobre los servicios hay dos posibilidades: o son burros - o son perversos. Las opciones no son excluyentes, aunque cualquiera alcanza para tornarlos indignos de - confianza. Sin embargo, de ellos proviene la información que alimenta a muchos medios de comunicación y, - aún más grave, al Estado argentino. - El reguero de noticias falsas y vínculos brumosos tiene, paradójicamente, un objetivo prístino: asociar - la acción de los grupos mapuches con el terrorismo internacional. Comunicadores, analistas y escritores - alineados con el discurso oficial llegaron a relacionar las ideas de las organizaciones patagónicas con - las de Estado Islámico (ISIS) de Irak y Siria. El terrorismo carece de definiciones consensuales y ha - sido utilizado para emparentar cosas bien diferentes. Aunque el líder mapuche más radicalizado (y menos - representativo) declare que propician "un proceso de construcción de autonomía sin pedirle permiso al - Estado", vincular a un grupo que reclama tierras en la región de sus ancestros con otro que busca - gobernar el mundo según sus normas religiosas y ha masacrado a miles de personas requiere de una - operación intelectual tan audaz como inadecuada. - - La asociación con el movimiento kurdo, en cambio, asoma menos inverosímil. Desde su arresto, Ocalan - transformó su pensamiento: de una visión nacionalista con inspiración estalinista evolucionó al - confederalismo democrático, una propuesta de organización comunal, ecologista, más apegada a las raíces - locales que a las fronteras nacionales. Parece lógico que esas ideas resuenen en agrupamientos - indígenas, que reivindican una organización anterior a la consolidación de los Estados sudamericanos. - Los paralelos, sin embargo, terminan allí. En Chile, donde el conflicto ha tenido su desarrollo más - dramático, la Sociedad de Fomento Agrícola denunció en 2014 que los insurrectos causaron daños por 10 - millones de dólares y la muerte de tres agricultores y un carabinero a lo largo de 15 años; en la - Argentina, por ahora, se registran actos de vandalismo, ocupaciones de tierras y cortes de rutas - aislados. En contraste, el conflicto entre el Partido de los Trabajadores del Kurdistán y la República - de Turquía se cobró cerca de 40.000 vidas en los años 90 y lleva más de 2000 desde la reanudación de - hostilidades en 2015. - Consultada sobre esta desproporción, una fuente de los servicios nos la resumió así: "La estrategia de la - Coordinadora Arauco-Malleco (CAM), de Chile, y ahora de la Resistencia Ancestral Mapuche (RAM), más que - matar directamente, es realizar sabotajes, movilizaciones, ataques a iglesias y empresas y mucha - prensa". ¡En Medio Oriente pagarían por un terrorismo así! Ningún hecho de violencia debe ser - minimizado, pero las analogías no resisten prueba. - - La "cuestión mapuche" es social antes que policial. La Constitución manda "reconocer la preexistencia - étnica y cultural de los pueblos indígenas argentinos. Garantizar el respeto a su identidad?; reconocer - la personería jurídica de sus comunidades, y la posesión y propiedad comunitarias de las tierras que - tradicionalmente ocupan; y regular la entrega de otras aptas y suficientes para el desarrollo humano". - Estos derechos permanecen incumplidos. Y no son un capricho chavista: los países que reputamos serios - también los reconocen. En Estados Unidos, las reservaciones indígenas ocupan 80.000 kilómetros - cuadrados, el 1,3% de la superficie del país (y 400 veces la superficie de la ciudad de Buenos Aires). - En Canadá, unas 2300 reservas ocupan 28.000 kilómetros cuadrados. Australia otorga a los pueblos - indígenas más de la mitad de los territorios del norte del país y son los nativos quienes negocian con - las empresas mineras los permisos para que operen en sus tierras. En Nueva Zelanda existen tribunales - especiales con jurisdicción sobre las tierras ancestrales de los maoríes; una de sus ventajas es que - empoderan a los aborígenes individualmente, liberándolos del yugo de los caciques. - La protesta social es indisociable de la democracia. Cuando desborda, recanalizarla es más eficiente que - reprimirla: ahí reside el arte del acuerdo. En la Argentina la tarea es delicada porque pocos confían en - la imparcialidad de las instituciones. Entonces, cada actor reivindica sus intereses con los medios de - que dispone: los sindicatos hacen huelga, los estudiantes toman colegios, los empresarios cierran las - fábricas y todos hacen piquetes. El politólogo Samuel Huntington definía una sociedad así como - pretoriana y el jurista Carlos Nino llamó a la Argentina "un país al margen de la ley". Al movilizarse - por sus derechos y desconfiar del Estado, la comunidad mapuche se demuestra bien argentina. - Las cinco provincias patagónicas tienen una población similar a la de La Matanza. A diferencia de los - Estados Unidos, que se integraron hacia el oeste otorgando parcelas de tierra a los colonizadores, y de - Brasil, donde el rol de ocupación y desarrollo territorial fue cumplido por las fuerzas armadas, la - Argentina obvió la tarea integradora tras consolidar su soberanía a finales del siglo XX. Hoy sobra - tierra y falta gente. Gobernar sigue siendo poblar, pero también integrar. - Seamos claros: ningún individuo u organización tiene derecho a violar la ley. Pero el problema histórico - del Estado argentino no fue tanto quiénes lo desafiaron como quiénes lo gobernaron. Cambiemos. - Andrés Malamud es politólogo e investigador en la Universidad de Lisboa. Martín Schapiro es abogado - administrativista y analista internacional - - -
1 - - Por qué Jerusalén está - dividida en occidental y oriental y por qué importa que Donald Trump no mencionara esto - - -
2 - - Qué son los "criptogatos": - valen más de US$ 100.000 y pueden ser un problema para las criptomonedas - -
3 - - "Soy el mejor de la - historia", la frase de Cristiano Ronaldo tras su quinto Balón de Oro que encendió el debate: la - comparación con Lionel Messi - -
4 - - El viaje de Zannini de Río - Gallegos a Buenos Aires, un vuelo de tres horas cargado de indiferencia - -
- Le projet de loi sur le renseignement massivement approuvé à l'Assemblée - Le Monde | - 04.05.2015 à 13h36 • Mis à jour le - 05.05.2015 à 20h13 | -Par Martin Untersinger (avec Damien Leloup et Morgane Tual) - - - - - - - - - Les députés ont, sans surprise, adopté à une large majorité (438 contre 86 et 42 abstentions) le projet de loi sur le renseignement défendu par le gouvernement lors d’un vote solennel, mardi 5 mai. Il sera désormais examiné par le Sénat, puis le Conseil constitutionnel, prochainement saisi par 75 députés. Dans un souci d'apaisement, François Hollande avait annoncé par avance qu'il saisirait les Sages. - Revivez le direct du vote à l’Assemblée avec vos questions. - Ont voté contre : 10 députés socialistes (sur 288), 35 UMP (sur 198), 11 écologistes (sur 18), 11 UDI (sur 30), 12 députés Front de gauche (sur 15) et 7 non-inscrits (sur 9). Le détail est disponible sur le site de l'Assemblée nationale. - Parmi les députés ayan voté contre figurent notamment des opposants de la première heure, comme l'UMP Laure de la Raudière ou l'écologiste Sergio Coronado, mais aussi quelques poids lourds de l'opposition comme Patrick Devedjian ou Claude Goasguen. A gauche, on trouve parmi les quelque opposants au texte Aurélie Filipetti. Christian Paul, qui avait été très actif lors d'autres débats sur les libertés numériques, s'est abstenu. - Pouria Amirshahi, député socialiste des Français de l'étranger qui a également voté contre, a annoncé qu'il transmettrait un « mémorandum argumenté » au Conseil constitutionnel et demanderait à se faire auditionner sur le projet de loi. D'autres députés ont prévu de faire la même démarche. - Ce texte, fortement décrié par la société civile pour son manque de contre-pouvoir et le caractère intrusif des techniques qu’il autorise, entend donner un cadre aux pratiques des services de renseignement, rendant légales certaines pratiques qui, jusqu’à présent, ne l’étaient pas. - Retour sur ses principales dispositions, après son passage en commission des lois et après le débat en séance publique. - Définition des objectifs des services - Le projet de loi énonce les domaines que peuvent invoquer les services pour justifier leur surveillance. Il s’agit notamment, de manière attendue, de « l’indépendance nationale, de l’intégrité du territoire et de la défense nationale » et de « la prévention du terrorisme », mais également des « intérêts majeurs de la politique étrangère », ainsi que de la « prévention des atteintes à la forme républicaine des institutions » et de « la criminalité et de la délinquance organisées ». Des formulations parfois larges qui inquiètent les opposants au texte qui craignent qu’elles puissent permettre de surveiller des activistes ou des manifestants. - La Commission de contrôle - Le contrôle de cette surveillance sera confié à une nouvelle autorité administrative indépendante, la Commission nationale de contrôle des techniques de renseignement (CNCTR), composée de six magistrats du Conseil d’Etat et de la Cour de cassation, de trois députés et trois sénateurs de la majorité et de l’opposition, et d’un expert technique. Elle remplacera l’actuelle Commission nationale de contrôle des interceptions de sécurité (CNCIS). - Elle délivrera son avis, sauf cas d’urgence, avant toute opération de surveillance ciblée. Deux types urgences sont prévus par la loi : d’un côté une « urgence absolue », pour laquelle un agent pourra se passer de l’avis de la CNCTR mais pas de l’autorisation du premier ministre. De l’autre, une urgence opérationnelle extrêmement limitée, notamment en termes de techniques, à l’initiative du chef du service de renseignement, qui se passe de l’avis de la CNCTR. Ces cas d’urgence ne justifieront pas l’intrusion d’un domicile ni la surveillance d’un journaliste, un parlementaire ou un avocat. Dans ces cas, la procédure classique devra s’appliquer. - L’avis de la CNCTR ne sera pas contraignant, mais cette commission pourra saisir le Conseil d’Etat si elle estime que la loi n’est pas respectée et elle disposera de pouvoirs d’enquête. Ce recours juridictionnel est une nouveauté dans le monde du renseignement. - Les « boîtes noires » - Une des dispositions les plus contestées de ce projet de loi prévoit de pouvoir contraindre les fournisseurs d’accès à Internet (FAI) à « détecter une menace terroriste sur la base d’un traitement automatisé ». Ce dispositif – autorisé par le premier ministre par tranche de quatre mois – permettrait de détecter, en temps réel ou quasi réel, les personnes ayant une activité en ligne typique de « schémas » utilisés par les terroristes pour transmettre des informations. - En pratique, les services de renseignement pourraient installer chez les FAI une « boîte noire » surveillant le trafic. Le contenu des communications – qui resterait « anonyme » – ne serait pas surveillé, mais uniquement les métadonnées : origine ou destinataire d’un message, adresse IP d’un site visité, durée de la conversation ou de la connexion… Ces données ne seraient pas conservées. - La Commission nationale informatique et libertés (CNIL), qui critique fortement cette disposition. La CNIL soulève notamment que l’anonymat de ces données est très relatif, puisqu’il peut être levé. - Lire aussi : Les critiques de la CNIL contre le projet de loi sur le renseignement - Le dispositif introduit une forme de « pêche au chalut » – un brassage très large des données des Français à la recherche de quelques individus. Le gouvernement se défend de toute similarité avec les dispositifs mis en place par la NSA américaine, arguant notamment que les données ne seront pas conservées et que cette activité sera contrôlée par une toute nouvelle commission aux moyens largement renforcés. Il s’agit cependant d’un dispositif très large, puisqu’il concernera tous les fournisseurs d’accès à Internet, et donc tous les internautes français. - L’élargissement de la surveillance électronique pour détecter les « futurs » terroristes - La surveillance des métadonnées sera aussi utilisée pour tenter de détecter de nouveaux profils de terroristes potentiels, prévoit le projet de loi. Le gouvernement considère qu’il s’agit d’une manière efficace de détecter les profils qui passent aujourd’hui « entre les mailles du filet », par exemple des personnes parties en Syrie ou en Irak sans qu’aucune activité suspecte n’ait été décelée avant leur départ. - Pour repérer ces personnes, la loi permettra d’étendre la surveillance électronique à toutes les personnes en contact avec des personnes déjà suspectées. En analysant leurs contacts, la fréquence de ces derniers et les modes de communication, les services de renseignement espèrent pouvoir détecter ces nouveaux profils en amont. - De nouveaux outils et méthodes de collecte - Les services pourront également procéder, après un avis de la CNCTR, à la pose de micros dans une pièce ou de mouchards sur un objet (voiture par exemple), ou à l’intérieur d’un ordinateur. L’utilisation des IMSI-catchers (fausses antennes qui permettent d’intercepter des conversations téléphoniques) est également légalisée, pour les services de renseignement, dans certains cas. Le nombre maximal de ces appareils sera fixé par arrêté du premier ministre après l’avis de la CNCTR. - Lire : Que sont les IMSI-catchers, ces valises qui espionnent les téléphones portables ? - La loi introduit également des mesures de surveillance internationale : concrètement, les procédures de contrôle seront allégées lorsqu’un des « bouts » de la communication sera situé à l’étranger (concrètement, un Français qui parle avec un individu situé à l’étranger). Cependant, comme l’a souligné l’Arcep (l’Autorité de régulation des communications électroniques et des postes), sollicitée pour le versant technique de cette mesure, il est parfois difficile de s’assurer qu’une communication, même passant par l’étranger, ne concerne pas deux Français. - Un nouveau fichier - La loi crée un fichier judiciaire national automatisé des auteurs d’infractions terroristes (Fijait), dont les données pourront être conservées pendant vingt ans. - Ce fichier concerne les personnes ayant été condamnées, même si une procédure d’appel est en cours. Les mineurs pourront aussi être inscrits dans ce fichier et leurs données conservées jusqu’à dix ans. L’inscription ne sera pas automatique et se fera sur décision judiciaire. Certaines mises en examen pourront aussi apparaître sur ce fichier. En cas de non-lieu, relaxe, acquittement, amnistie ou réhabilitation, ces informations seront effacées. - Renseignement pénitentiaire - Le renseignement pénitentiaire pourra, dans des conditions qui seront fixées par décret, profiter des techniques que légalise le projet de loi pour les services de renseignement. La ministre de la justice, Christiane Taubira, était défavorable à cette disposition, soutenue par le rapporteur du texte, la droite et une partie des députés de gauche. Pour la ministre, cette innovation va dénaturer le renseignement pénitentiaire et le transformer en véritable service de renseignement. - Conservation des données - La CNIL a fait part à plusieurs reprises de sa volonté d’exercer sa mission de contrôle sur les fichiers liés au renseignement, qui seront alimentés par ces collectes. Ces fichiers sont aujourd’hui exclus du périmètre d’action de la CNIL. - La durée de conservation des données collectées – et l’adaptation de cette durée à la technique employée – a par ailleurs été inscrite dans la loi, contrairement au projet initial du gouvernement qui entendait fixer ces limites par décret. Elle pourra aller jusqu’à cinq ans dans le cas des données de connexion. - Un dispositif pour les lanceurs d’alerte - La loi prévoit également une forme de protection pour les agents qui seraient témoins de surveillance illégale. Ces lanceurs d’alerte pourraient solliciter la CNCTR, voire le premier ministre, et leur fournir toutes les pièces utiles. La CNCTR pourra ensuite aviser le procureur de la République et solliciter la Commission consultative du secret de la défense nationale afin que cette dernière « donne au premier ministre son avis sur la possibilité de déclassifier tout ou partie de ces éléments ». Aucune mesure de rétorsion ne pourra viser l’agent qui aurait dénoncé des actes potentiellement illégaux. - - - - - - - - - - - - - Martin Untersinger (avec Damien Leloup et Morgane Tual) - - Journaliste au Monde - Suivre - Aller sur la page de ce journaliste - - Suivre ce journaliste sur twitter - - - - - -
- - - Un troisième Français a été tué dans le tremblement de terre samedi au Népal, emporté par une avalanche, a déclaré jeudi le ministre des Affaires étrangères. Les autorités françaises sont toujours sans nouvelles «d’encore plus de 200» personnes. «Pour certains d’entre eux on est très interrogatif», a ajouté Laurent Fabius. Il accueillait à Roissy un premier avion spécial ramenant des rescapés. L’Airbus A350 affrété par les autorités françaises s’est posé peu avant 5h45 avec à son bord 206 passagers, dont 12 enfants et 26 blessés, selon une source du Quai d’Orsay. Quasiment tous sont français, à l’exception d’une quinzaine de ressortissants allemands, suisses, italiens, portugais ou encore turcs. Des psychologues, une équipe médicale et des personnels du centre de crise du Quai d’Orsay les attendent. - L’appareil, mis à disposition par Airbus, était arrivé à Katmandou mercredi matin avec 55 personnels de santé et humanitaires, ainsi que 25 tonnes de matériel (abris, médicaments, aide alimentaire). Un deuxième avion dépêché par Paris, qui était immobilisé aux Emirats depuis mardi avec 20 tonnes de matériel, est arrivé jeudi à Katmandou, dont le petit aéroport est engorgé par le trafic et l’afflux d’aide humanitaire. Il devait lui aussi ramener des Français, «les plus éprouvés» par la catastrophe et les «plus vulnérables (blessés, familles avec enfants)», selon le ministère des Affaires étrangères. - 2 209 Français ont été localisés sains et saufs tandis que 393 n’ont pas encore pu être joints, selon le Quai d’Orsay. Environ 400 Français ont demandé à être rapatriés dans les vols mis en place par la France. - Le séisme a fait près de 5 500 morts et touche huit des 28 millions d’habitants du Népal. Des dizaines de milliers de personnes sont sans abri. - - - -
- - - Accueil - › - - Monde - - - - - Un troisième Français mort dans le séisme au Népal - AFP - - 30 avril 2015 à 07:19 (Mis à jour : 30 avril 2015 à 07:38) - - - - Un Népalais prie à Katmandou, le 30 avril 2015. (Photo Prakash Mathema. AFP) - - - Laurent Fabius a accueilli jeudi matin à Roissy un premier avion spécial ramenant des rescapés. - - - - - - - - - Un troisième Français a été tué dans le tremblement de terre samedi au Népal, emporté par une avalanche, a déclaré jeudi le ministre des Affaires étrangères. Les autorités françaises sont toujours sans nouvelles «d’encore plus de 200» personnes. «Pour certains d’entre eux on est très interrogatif», a ajouté Laurent Fabius. Il accueillait à Roissy un premier avion spécial ramenant des rescapés. L’Airbus A350 affrété par les autorités françaises s’est posé peu avant 5h45 avec à son bord 206 passagers, dont 12 enfants et 26 blessés, selon une source du Quai d’Orsay. Quasiment tous sont français, à l’exception d’une quinzaine de ressortissants allemands, suisses, italiens, portugais ou encore turcs. Des psychologues, une équipe médicale et des personnels du centre de crise du Quai d’Orsay les attendent. - L’appareil, mis à disposition par Airbus, était arrivé à Katmandou mercredi matin avec 55 personnels de santé et humanitaires, ainsi que 25 tonnes de matériel (abris, médicaments, aide alimentaire). Un deuxième avion dépêché par Paris, qui était immobilisé aux Emirats depuis mardi avec 20 tonnes de matériel, est arrivé jeudi à Katmandou, dont le petit aéroport est engorgé par le trafic et l’afflux d’aide humanitaire. Il devait lui aussi ramener des Français, «les plus éprouvés» par la catastrophe et les «plus vulnérables (blessés, familles avec enfants)», selon le ministère des Affaires étrangères. - 2 209 Français ont été localisés sains et saufs tandis que 393 n’ont pas encore pu être joints, selon le Quai d’Orsay. Environ 400 Français ont demandé à être rapatriés dans les vols mis en place par la France. - Le séisme a fait près de 5 500 morts et touche huit des 28 millions d’habitants du Népal. Des dizaines de milliers de personnes sont sans abri. - - - - - AFP - - - -
How to Program Your Mind to Stop Buying Crap You Don’t Need 321,04636 Patrick AllanProfileFollowUnfollow Patrick AllanFiled to: money shopping saving money personal finances mind hacks habits budget psychology editor's picks 3/09/15 8:00am 3/09/15 8:00amEditDelete InviteInvite manuallyPromoteXDismissXUndismissBlock for LifehackerHideShare to KinjaShare to FacebookShare to PinterestShare to TwitterGo to permalink - - - - - - - - - - -We all buy things from time to time that we don't really need. It's okay to appeal to your wants every once in a while, as long as you're in control. If you struggle with clutter, impulse buys, and buyer's remorse, here's how to put your mind in the right place before you even set foot in a store. - - - - - - - - - - - - - -Understand How Your Own Brain Works Against You - - - - - - - - - - - - - - - - - - - - - -It may come as no surprise to learn that stores employ all kinds of tricks to get you to part ways with your cash, and your brain plays right along. Through psychological tricks, product placement, and even color, stores are designed from the ground up to increase spending. We've talked about the biggest things stores do to manipulate your senses, but here are some of the biggest things to look out for: - - - - - - - - - - -Color: Stores use color to make products attractive and eye-catching, but they also use color on price labels. Red stands out and can encourage taking action, that's why it's commonly associated with sale signage and advertising. When you see red, remember what they're trying to do to your brain with that color. You don't to buy something just because it's on sale.Navigation Roadblocks: Stores force you to walk around stuff you don't need to find the stuff you are really after. Have a list of what you need before you go in, go straight to it, and imagine it's the only item in the store.The Touch Factor: Stores place items they want to sell in easy to reach locations and encourage you to touch them. Don't do it! As soon as you pick something up, you're more likely to buy it because your mind suddenly takes ownership of the object. Don't pick anything up and don't play with display items.Scents and Sounds: You'll probably hear classic, upbeat tunes when you walk into a store. The upbeat music makes you happy and excited, while playing familiar songs makes you feel comfortable. They also use pleasant smells to put your mind at ease. A happy, comfortable mind at ease is a dangerous combination for your brain when shopping. There's not much you can do to avoid this unless you shop online, but it's good to be aware of it. - - - - - - - - - - -And sure, we can blame the stores all we want, but you won't change how they operate—you can only be aware of how your brain is falling for their tricks. Even without the stores, your brain is working against you on its own, thanks to some simple cognitive biases. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -For example, confirmation bias makes you only believe the information that conforms to your prior beliefs, while you discount everything else. Advertisers appeal to this bias directly by convincing you one item is better than another with imagery and other tricks, regardless of what hard facts might say. Keep your mind open, do your own research, and accept when you're wrong about a product. The Decoy effect is also a commonly used tactic. You think one product is a deal because it's next to a similar product that's priced way higher. Even if it's a product you need, it's probably not as good of a deal as it looks right then and there. Again, always research beforehand and be on the lookout for this common trick to avoid impulse buys. - - - - - - - - - - -Make a List of Everything You Own and Do Some Decluttering - - - - - - - - - - - - - - - - - - - - - -Now that you know what you're up against, it's time to start changing the way you think. Before you can stop buying crap you don't need, you need to identify what that crap is. The first step is to make a list of every single thing you own. Every. Single. Thing. This might sound extreme, but you need to gather your data so you can start reprogramming your mind. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -The purpose of this exercise is twofold: you see what you already have and don't need to ever buy again, and you get to see what you shouldn't have bought in the first place. As you list everything out, separate items into categories. It's extremely important that you are as honest with yourself as possible while you do this. It's also important you actually write this all down or type it all out. Here is the first set of categories to separate everything into: - - - - - - - - - - -Need: You absolutely need this item to get by on a day to day basis.Sometimes Need: You don't need this item every day, but you use it on a somewhat regular basis.Want: You bought this item because you wanted it, not because you needed it.Crap: You don't have a good reason why you have it and you already know it needs to go (there's probably a few of these items, at least). - - - - - - - - - - -Leave the things you listed as "needs" alone, put your stuff listed as "crap" in a pile or box to go bye-bye, and move your attention back to your "sometimes need" and "want" lists. You need to go back over both of those lists because you probably fudged some of the listings, either subconsciously or intentionally. Now ask yourself these three questions as you go through both the "sometimes need" and "want" lists: - - - - - - - - - - -When was the last time I used this?When will I use this again?Does this item bring you joy? - - - - - - - - - - -Remember to be honest and adjust your lists accordingly. There's nothing wrong with keeping things you wanted. Material items can bring happiness to many people, but make sure the items on your "want" list actively provide you joy and are being used. If an item doesn't get much use or doesn't make you happy, add it to the "crap" list. - - - - - - - - - - -Once you have everything organized, it's time to do some serious decluttering. This listing exercise should get you started, but there are a lot of other great ideas when it comes to ditching the junk you don't need. Regardless, everything on your "crap" list needs to go. You can donate it, sell it at a yard sale, give it away to people know, whatever you like. Before you get rid of everything, though, take a picture of all your stuff together. Print out or save the picture somewhere. Some of it was probably gifts, but in general, this is all the crap you bought that you don't need. Take a good look and remember it. - - - - - - - - - - -See How Much Money and Time You Spent on the Stuff You Threw Out - - - - - - - - - - - - - - - - - - - - - -Now take a look at your "crap" list again and start calculating how much you spent on all of it. If it was a gift, mark it as $0. Otherwise, figure out the price of the item at the time you bought it. If you got a deal or bought it on sale it's okay to factor that in, but try to be as accurate as possible. Once you have the price for each item, add it all together. Depending on your spending habits this could possibly be in the hundreds to thousands of dollars. Remember the picture you took of all this stuff? Attach the total cost to the picture so you can see both at the same time. - - - - - - - - - - -With the money cost figured out, you should take a look at the other costs too. Time is a resource just like any other, and it's a finite one. What kind of time did you pour into these things? Consider the time you spent acquiring and using these items, then write it all down. These can be rough estimations, but go ahead and add it all up when you think you've got it. Now attach the total time to same picture as before and think of the other ways you could have spent all that time. This isn't to make you feel bad about yourself, just to deliver information to your brain in an easy-to-understand form. When you look at it all like this, it can open your eyes a little more, and help you think about purchases in the future. You'll look at an item and ask yourself, "Will this just end up in the picture?" - - - - - - - - - - -List Every Non-Material Thing In Your Life that Makes You Happy - - - - - - - - - - - - - - - - - - - - - -Now it's time to make a different list. While material items may bring plenty of joy, the things in your life that make you happiest probably can't be bought. Get a separate piece of paper or create a new document and list out everything in your life that makes you happy. If you can't buy it, it's eligible for the list. It doesn't matter if it only makes you crack a smile or makes you jump for joy, list it out. - - - - - - - - - - -These are probably the things that actually make you want to get out of bed in the morning and keep on keepin' on. Once you have it all down, put it in your purse or wallet. The next time you feel the urge to buy something, whip this list out first and remind yourself why you probably don't need it. - - - - - - - - - - -Spend Some Time Away from Material Things to Gain Perspective - - - - - - - - - - - - - - - - - - - - - -If you're having a really hard time with your spending, it can help to get away from material objects completely. When you're constantly surrounded by stuff and have access to buying things at all times, it can be really tough to break the habit. Spend a day in the park enjoying the sights and sounds of the outdoors, go camping with some friends, or hike a trail you haven't been on before. - - - - - - - - - - -Essentially, you want to show yourself that you don't need your "things" to have a good time. When you realize how much fun you can have without all the trinkets and trivets, you'll start to shut down your desire to buy them. If you can't get really get away right now, just go for a walk without your purse or wallet (but carry your ID). If you can't buy anything, you'll be forced to experience things a different way. - - - - - - - - - - -Develop a Personal "Should I Buy This?" Test - - - - - - - - - - - - - - - - - - - - - -If you don't have a personal "should I buy this?" test, now's the perfect time to make one. When you find an item you think you need or want, it has to pass all of the questions you have on your test before you can buy it. Here's where you can use all of the data you've gathered so far and put it to really good use. The test should be personalized to your own buying habits, but here are some example questions: - - - - - - - - - - -Is this a planned purchase?Will it end up in the "crap" list picture one day?Where am I going to put it?Have I included this in my budget?Why do I want/need it? - - - - - - - - - - -Custom build your test to hit all of your weaknesses. If you make a lot of impulse buys, include questions that address that. If you experience a lot of buyer's remorse, include a lot of questions that make you think about the use of item after you buy it. If buying the latest and greatest technology is your weakness, Joshua Becker at Becoming Minimalist suggests you ask yourself what problem the piece of tech solves. If you can't think of anything it solves or if you already have something that solves it, you don't need it. Be thorough and build a test that you can run through your mind every time you consider buying something. - - - - - - - - - - -Learn to Delay Gratification and Destroy the Urge to Impulse Buy - - - - - - - - - - - - - - - - - - - - - -When it comes to the unnecessary crap we buy, impulse purchases probably make up a good deal of them. We love to feel gratification instantly and impulse buys appeal to that with a rush of excitement with each new purchase. We like to believe that we have control over our impulses all the time, but we really don't, and that's a major problem for the ol' wallet. - - - - - - - - - - -The key is teaching your brain that it's okay to wait for gratification. You can do this with a simple time out every time you want something. Look at whatever you're thinking of buying, go through your personal "should I buy this?" test, and then walk away for a little while. Planning your purchases ahead is ideal, so the longer you can hold off, the better. Set yourself a reminder to check on the item a week or month down the line. When you come back to it, you may find that you don't even want it, just the gratification that would come with it. If you're shopping online, you can do the same thing. Walk away from your desk or put your phone in your pocket and do something else for a little while. - - - - - - - - - - -You can also avoid online impulse purchases by making it harder to do. Block shopping web sites during time periods you know you're at your weakest, or remove all of your saved credit card or Paypal information. You can also practice the "HALT" method when you're shopping online or in a store. Try not to buy things when you're Hungry, Angry, Lonely, or Tired because you're at your weakest state mentally. Last, but not least, the "stranger test" can help you weed out bad purchases too. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -The last thing you should consider when it comes to impulse buys is "artificial replacement." As Trent Hamm at The Simple Dollar explains, artificial replacement can happen when you start to reduce the time you get with your main interests: - - - - - - - - - - - -Whenever I consistently cut quality time for my main interests out of my life, I start to long for them. As you saw in that "typical" day, I do make room for spending time with my family, but my other two main interests are absent. If that happens too many days in a row, I start to really miss reading. I start to really miss playing thoughtful board games with friends. What happens after that? I start to substitute. When I don't have the opportunity to sit down for an hour or even for half an hour and really get lost in a book, I start looking for an alternative way to fill in the tiny slices of time that I do have. I'll spend money. - - - - - - - - - - -You probably have things in your life that provide plenty of gratification, so don't get caught substituting it with impulse buys. Always make sure you keep yourself happy with plenty of time doing the things you like to do and you won't be subconsciously trying to fill that void with useless crap. - - - - - - - - - - -Turn the Money You Save Into More Money - - - - - - - - - - - - - - - - - - - - - -Once you've programmed your mind to stop buying crap you don't need, you'll have some extra cash to play with. Take all that money and start putting it toward your future and things you will need further down the road. You might need a home, a vehicle, or a way to retire, but none of that can happen until you start planning for it. - - - - - - - - - - -Start by paying off any debts you already have. Credit cards, student loans, and even car payments can force you to live paycheck to paycheck. Use the snowball method and pay off some small balances to make you feel motivated, then start taking out your debt in full force with the stacking method: stop creating new debt, determine which balances have the highest interest rates, and create a payment schedule to pay them off efficiently. - - - - - - - - - - -With your debts whittled down, you should start an emergency fund. No matter how well you plan things, accidents and health emergencies can still happen. An emergency fund is designed to make those kinds of events more manageable. This type of savings account is strictly for when life throws you a curveball, but you can grow one pretty easily with only modest savings. - - - - - - - - - - -When you've paid off your debt and prepared yourself for troubled times, you can start saving for the big stuff. All that money you're not spending on crap anymore can be saved, invested, and compounded to let you buy comfort and security. If you don't know where to start, talk to a financial planner. Or create a simple, yet effective "set and forget" investment portfolio. You've worked hard to reprogram your mind, so make sure you reap the benefits for many years to come. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -Photos by cmgirl (Shutterstock), Macrovector (Shutterstock), J E Theriot, davidd, George Redgrave, David Amsler, Arup Malakar, J B, jakerome, 401(K) 2012. 36 146Reply <span id="js_reply-count" class="proxima text-small mlm mrn">146<span class="icon icon-bubble-round oversized"></span></span><script>document.getElementById('js_reply-count').style.display = 'inline';</script><a href="#" class="reply-to-post reply-count hover-icon proxima text-small" rel="nofollow">Discuss<span class="icon icon-bubble-round oversized"></span></a>
jnovo22ProfileFollowUnfollow jnovo22Patrick Allan 3/09/15 8:12am 3/09/15 8:12amEditDelete InviteInvite manuallyFollow jnovo22Unfollow jnovo22Follow jnovo22 for LifehackerUnfollow jnovo22 for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkThis is one of my hardest habits to break. I've been working on it for literally years. I'm getting better, mainly because I've gone to cash-only recently. Swiping the debit/credit cards don't seem like "real" money (even though it obviously is). Having cash on hand, and then see it disappear makes the "Should I buy This?" decision that much easier. Usually it's "No".924ReplyFlagged
Patrick AllanProfileFollowUnfollow Patrick Allanjnovo22 3/09/15 8:14am 3/09/15 8:14amEditDelete InviteInvite manuallyFollow patrickallanUnfollow patrickallanFollow patrickallan for LifehackerUnfollow patrickallan for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkI do the cash-only thing too. I usually will give myself a limit, like I can spend this much this weekend. Once it's gone, that's it.15ReplyFlagged
jnovo22ProfileFollowUnfollow jnovo22Patrick Allan 3/09/15 8:47am 3/09/15 8:47amEditDelete InviteInvite manuallyFollow jnovo22Unfollow jnovo22Follow jnovo22 for LifehackerUnfollow jnovo22 for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkYup. Each week, I give myself $25 cash for spending on me. If I go out to eat Friday night, that's it, it's gone. - - - - - - - - - - -I use the envelope system for dividing saved cash for special purchases, home improvements, etc. It's crazy how fast it adds up.12ReplyFlagged
The Gray AdderProfileFollowUnfollow The Gray AdderPatrick Allan 3/09/15 8:26am 3/09/15 8:26amEditDelete InviteInvite manuallyFollow thegrayadderUnfollow thegrayadderFollow thegrayadder for LifehackerUnfollow thegrayadder for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkMake a List of Everything You Own and Do Some DeclutteringWhy would I make a list when I could get right down to the business of decluttering?31ReplyFlagged
Patrick AllanProfileFollowUnfollow Patrick AllanThe Gray Adder 3/09/15 8:32am 3/09/15 8:32amEditDelete InviteInvite manuallyFollow patrickallanUnfollow patrickallanFollow patrickallan for LifehackerUnfollow patrickallan for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkSo you know what you already have. You can avoid buying something that you forget you had, or the next time you're in a store, you might remember that you have an item that can do the same job as the thing you're interested in. It also helps you gain a little perspective when you realize how many things you actually own already. It can help you rethink those desires to buy things.111ReplyFlagged
greenarcher02ProfileFollowUnfollow greenarcher02Patrick Allan 3/09/15 8:33am 3/09/15 8:33amEditDelete InviteInvite manuallyFollow winfredarmandelafuentelatiUnfollow winfredarmandelafuentelatiFollow winfredarmandelafuentelati for LifehackerUnfollow winfredarmandelafuentelati for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkDoes it count that I'm waiting for Final Fantasy Type-0 before buying a PS4?4ReplyFlagged
Patrick AllanProfileFollowUnfollow Patrick Allangreenarcher02 3/09/15 8:35am 3/09/15 8:35amEditDelete InviteInvite manuallyFollow patrickallanUnfollow patrickallanFollow patrickallan for LifehackerUnfollow patrickallan for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkAs long as you're saving for it now ;)2ReplyFlagged
greenarcher02ProfileFollowUnfollow greenarcher02Patrick Allan 3/09/15 8:46am 3/09/15 8:46amEditDelete InviteInvite manuallyFollow winfredarmandelafuentelatiUnfollow winfredarmandelafuentelatiFollow winfredarmandelafuentelati for LifehackerUnfollow winfredarmandelafuentelati for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkI am. Well, I was..... Some of it was spent on impulse buying Ziiiro watches last Valentine's Day lol. :( So I'm saving up, again. Sucks that it'll get delayed because of a freaking watch. - - - - - - - - - - -Ugh I feel like I need to read this article everyday.6ReplyFlagged
timgrayProfileFollowUnfollow timgrayPatrick Allan 3/09/15 9:00am 3/09/15 9:00amEditDelete InviteInvite manuallyFollow timgrayUnfollow timgrayFollow timgray for LifehackerUnfollow timgray for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkI love the suggestion of going camping to get away from stuff... You do realize that camping gear can be more expensive than electronics and gadgets.... Now I need to buy a $4500 tent and $1200 hiking shoes to get away from things.... - - - - - - - - - - -Oh and I have to have all matching camping clothing from North Face... I need to go shopping.427ReplyFlagged
Patrick AllanProfileFollowUnfollow Patrick Allantimgray 3/09/15 9:07am 3/09/15 9:07amEditDelete InviteInvite manuallyFollow patrickallanUnfollow patrickallanFollow patrickallan for LifehackerUnfollow patrickallan for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkHaha, yeah, some camping gear can be pretty pricey, but I just went this past weekend with a rented tent and some friends, and it didn't cost much. Just got to avoid the "I want to look like an outdoorsy camper" style I guess :P18ReplyFlagged
timgrayProfileFollowUnfollow timgrayPatrick Allan 3/09/15 9:25am 3/09/15 9:25amEditDelete InviteInvite manuallyFollow timgrayUnfollow timgrayFollow timgray for LifehackerUnfollow timgray for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinkMy camping gear addiction is one of those that I need to do some decluttering on. I have a really cool 2 person Tent Cot that sound like awesome ideas until you actually see one in person. - - - - - - - - - - -http://www.amazon.com/Kamp-Rite-TB34... - - - - - - - - - - -They weigh nearly 90 pounds and will not fit in the back of anything but a full size SUV with the seats folded down or a pickup truck. - - - - - - - - - - -So it has sat in it's box in my basement for the past 3 years as a testament to my UPS guys hernia when he delivered it.5ReplyFlagged
Patrick AllanProfileFollowUnfollow Patrick Allantimgray 3/09/15 9:37am 3/09/15 9:37amEditDelete InviteInvite manuallyFollow patrickallanUnfollow patrickallanFollow patrickallan for LifehackerUnfollow patrickallan for LifehackerXDismissXUndismissBlock for LifehackerHideFlagUnflagShare to FacebookShare to PinterestShare to TwitterGo to permalinklol! That does sound like a cool idea, but you're right, what's the point if you can't transport it easily? I wonder if someone makes a lighter, less cumbersome model...1ReplyFlagged
How to Program Your Mind to Stop Buying Crap You Don’t Need 36 Patrick AllanProfileFollowUnfollow Patrick AllanFiled to: money shopping saving money personal finances mind hacks habits budget psychology editor's picks 3/09/15 8:00am 3/09/15 8:00amEditDelete InviteInvite manuallyPromoteXDismissXUndismissBlock for LifehackerHideShare to KinjaShare to FacebookShare to PinterestShare to TwitterGo to permalink - - - - - - - - - - -We all buy things from time to time that we don't really need. It's okay to appeal to your wants every once in a while, as long as you're in control. If you struggle with clutter, impulse buys, and buyer's remorse, here's how to put your mind in the right place before you even set foot in a store. - - - - - - - - - - - - - -Understand How Your Own Brain Works Against You - - - - - - - - - - - - - - - - - - - - - -It may come as no surprise to learn that stores employ all kinds of tricks to get you to part ways with your cash, and your brain plays right along. Through psychological tricks, product placement, and even color, stores are designed from the ground up to increase spending. We've talked about the biggest things stores do to manipulate your senses, but here are some of the biggest things to look out for: - - - - - - - - - - -Color: Stores use color to make products attractive and eye-catching, but they also use color on price labels. Red stands out and can encourage taking action, that's why it's commonly associated with sale signage and advertising. When you see red, remember what they're trying to do to your brain with that color. You don't to buy something just because it's on sale.Navigation Roadblocks: Stores force you to walk around stuff you don't need to find the stuff you are really after. Have a list of what you need before you go in, go straight to it, and imagine it's the only item in the store.The Touch Factor: Stores place items they want to sell in easy to reach locations and encourage you to touch them. Don't do it! As soon as you pick something up, you're more likely to buy it because your mind suddenly takes ownership of the object. Don't pick anything up and don't play with display items.Scents and Sounds: You'll probably hear classic, upbeat tunes when you walk into a store. The upbeat music makes you happy and excited, while playing familiar songs makes you feel comfortable. They also use pleasant smells to put your mind at ease. A happy, comfortable mind at ease is a dangerous combination for your brain when shopping. There's not much you can do to avoid this unless you shop online, but it's good to be aware of it. - - - - - - - - - - -And sure, we can blame the stores all we want, but you won't change how they operate—you can only be aware of how your brain is falling for their tricks. Even without the stores, your brain is working against you on its own, thanks to some simple cognitive biases. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -For example, confirmation bias makes you only believe the information that conforms to your prior beliefs, while you discount everything else. Advertisers appeal to this bias directly by convincing you one item is better than another with imagery and other tricks, regardless of what hard facts might say. Keep your mind open, do your own research, and accept when you're wrong about a product. The Decoy effect is also a commonly used tactic. You think one product is a deal because it's next to a similar product that's priced way higher. Even if it's a product you need, it's probably not as good of a deal as it looks right then and there. Again, always research beforehand and be on the lookout for this common trick to avoid impulse buys. - - - - - - - - - - -Make a List of Everything You Own and Do Some Decluttering - - - - - - - - - - - - - - - - - - - - - -Now that you know what you're up against, it's time to start changing the way you think. Before you can stop buying crap you don't need, you need to identify what that crap is. The first step is to make a list of every single thing you own. Every. Single. Thing. This might sound extreme, but you need to gather your data so you can start reprogramming your mind. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -The purpose of this exercise is twofold: you see what you already have and don't need to ever buy again, and you get to see what you shouldn't have bought in the first place. As you list everything out, separate items into categories. It's extremely important that you are as honest with yourself as possible while you do this. It's also important you actually write this all down or type it all out. Here is the first set of categories to separate everything into: - - - - - - - - - - -Need: You absolutely need this item to get by on a day to day basis.Sometimes Need: You don't need this item every day, but you use it on a somewhat regular basis.Want: You bought this item because you wanted it, not because you needed it.Crap: You don't have a good reason why you have it and you already know it needs to go (there's probably a few of these items, at least). - - - - - - - - - - -Leave the things you listed as "needs" alone, put your stuff listed as "crap" in a pile or box to go bye-bye, and move your attention back to your "sometimes need" and "want" lists. You need to go back over both of those lists because you probably fudged some of the listings, either subconsciously or intentionally. Now ask yourself these three questions as you go through both the "sometimes need" and "want" lists: - - - - - - - - - - -When was the last time I used this?When will I use this again?Does this item bring you joy? - - - - - - - - - - -Remember to be honest and adjust your lists accordingly. There's nothing wrong with keeping things you wanted. Material items can bring happiness to many people, but make sure the items on your "want" list actively provide you joy and are being used. If an item doesn't get much use or doesn't make you happy, add it to the "crap" list. - - - - - - - - - - -Once you have everything organized, it's time to do some serious decluttering. This listing exercise should get you started, but there are a lot of other great ideas when it comes to ditching the junk you don't need. Regardless, everything on your "crap" list needs to go. You can donate it, sell it at a yard sale, give it away to people know, whatever you like. Before you get rid of everything, though, take a picture of all your stuff together. Print out or save the picture somewhere. Some of it was probably gifts, but in general, this is all the crap you bought that you don't need. Take a good look and remember it. - - - - - - - - - - -See How Much Money and Time You Spent on the Stuff You Threw Out - - - - - - - - - - - - - - - - - - - - - -Now take a look at your "crap" list again and start calculating how much you spent on all of it. If it was a gift, mark it as $0. Otherwise, figure out the price of the item at the time you bought it. If you got a deal or bought it on sale it's okay to factor that in, but try to be as accurate as possible. Once you have the price for each item, add it all together. Depending on your spending habits this could possibly be in the hundreds to thousands of dollars. Remember the picture you took of all this stuff? Attach the total cost to the picture so you can see both at the same time. - - - - - - - - - - -With the money cost figured out, you should take a look at the other costs too. Time is a resource just like any other, and it's a finite one. What kind of time did you pour into these things? Consider the time you spent acquiring and using these items, then write it all down. These can be rough estimations, but go ahead and add it all up when you think you've got it. Now attach the total time to same picture as before and think of the other ways you could have spent all that time. This isn't to make you feel bad about yourself, just to deliver information to your brain in an easy-to-understand form. When you look at it all like this, it can open your eyes a little more, and help you think about purchases in the future. You'll look at an item and ask yourself, "Will this just end up in the picture?" - - - - - - - - - - -List Every Non-Material Thing In Your Life that Makes You Happy - - - - - - - - - - - - - - - - - - - - - -Now it's time to make a different list. While material items may bring plenty of joy, the things in your life that make you happiest probably can't be bought. Get a separate piece of paper or create a new document and list out everything in your life that makes you happy. If you can't buy it, it's eligible for the list. It doesn't matter if it only makes you crack a smile or makes you jump for joy, list it out. - - - - - - - - - - -These are probably the things that actually make you want to get out of bed in the morning and keep on keepin' on. Once you have it all down, put it in your purse or wallet. The next time you feel the urge to buy something, whip this list out first and remind yourself why you probably don't need it. - - - - - - - - - - -Spend Some Time Away from Material Things to Gain Perspective - - - - - - - - - - - - - - - - - - - - - -If you're having a really hard time with your spending, it can help to get away from material objects completely. When you're constantly surrounded by stuff and have access to buying things at all times, it can be really tough to break the habit. Spend a day in the park enjoying the sights and sounds of the outdoors, go camping with some friends, or hike a trail you haven't been on before. - - - - - - - - - - -Essentially, you want to show yourself that you don't need your "things" to have a good time. When you realize how much fun you can have without all the trinkets and trivets, you'll start to shut down your desire to buy them. If you can't get really get away right now, just go for a walk without your purse or wallet (but carry your ID). If you can't buy anything, you'll be forced to experience things a different way. - - - - - - - - - - -Develop a Personal "Should I Buy This?" Test - - - - - - - - - - - - - - - - - - - - - -If you don't have a personal "should I buy this?" test, now's the perfect time to make one. When you find an item you think you need or want, it has to pass all of the questions you have on your test before you can buy it. Here's where you can use all of the data you've gathered so far and put it to really good use. The test should be personalized to your own buying habits, but here are some example questions: - - - - - - - - - - -Is this a planned purchase?Will it end up in the "crap" list picture one day?Where am I going to put it?Have I included this in my budget?Why do I want/need it? - - - - - - - - - - -Custom build your test to hit all of your weaknesses. If you make a lot of impulse buys, include questions that address that. If you experience a lot of buyer's remorse, include a lot of questions that make you think about the use of item after you buy it. If buying the latest and greatest technology is your weakness, Joshua Becker at Becoming Minimalist suggests you ask yourself what problem the piece of tech solves. If you can't think of anything it solves or if you already have something that solves it, you don't need it. Be thorough and build a test that you can run through your mind every time you consider buying something. - - - - - - - - - - -Learn to Delay Gratification and Destroy the Urge to Impulse Buy - - - - - - - - - - - - - - - - - - - - - -When it comes to the unnecessary crap we buy, impulse purchases probably make up a good deal of them. We love to feel gratification instantly and impulse buys appeal to that with a rush of excitement with each new purchase. We like to believe that we have control over our impulses all the time, but we really don't, and that's a major problem for the ol' wallet. - - - - - - - - - - -The key is teaching your brain that it's okay to wait for gratification. You can do this with a simple time out every time you want something. Look at whatever you're thinking of buying, go through your personal "should I buy this?" test, and then walk away for a little while. Planning your purchases ahead is ideal, so the longer you can hold off, the better. Set yourself a reminder to check on the item a week or month down the line. When you come back to it, you may find that you don't even want it, just the gratification that would come with it. If you're shopping online, you can do the same thing. Walk away from your desk or put your phone in your pocket and do something else for a little while. - - - - - - - - - - -You can also avoid online impulse purchases by making it harder to do. Block shopping web sites during time periods you know you're at your weakest, or remove all of your saved credit card or Paypal information. You can also practice the "HALT" method when you're shopping online or in a store. Try not to buy things when you're Hungry, Angry, Lonely, or Tired because you're at your weakest state mentally. Last, but not least, the "stranger test" can help you weed out bad purchases too. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -The last thing you should consider when it comes to impulse buys is "artificial replacement." As Trent Hamm at The Simple Dollar explains, artificial replacement can happen when you start to reduce the time you get with your main interests: - - - - - - - - - - - -Whenever I consistently cut quality time for my main interests out of my life, I start to long for them. As you saw in that "typical" day, I do make room for spending time with my family, but my other two main interests are absent. If that happens too many days in a row, I start to really miss reading. I start to really miss playing thoughtful board games with friends. What happens after that? I start to substitute. When I don't have the opportunity to sit down for an hour or even for half an hour and really get lost in a book, I start looking for an alternative way to fill in the tiny slices of time that I do have. I'll spend money. - - - - - - - - - - -You probably have things in your life that provide plenty of gratification, so don't get caught substituting it with impulse buys. Always make sure you keep yourself happy with plenty of time doing the things you like to do and you won't be subconsciously trying to fill that void with useless crap. - - - - - - - - - - -Turn the Money You Save Into More Money - - - - - - - - - - - - - - - - - - - - - -Once you've programmed your mind to stop buying crap you don't need, you'll have some extra cash to play with. Take all that money and start putting it toward your future and things you will need further down the road. You might need a home, a vehicle, or a way to retire, but none of that can happen until you start planning for it. - - - - - - - - - - -Start by paying off any debts you already have. Credit cards, student loans, and even car payments can force you to live paycheck to paycheck. Use the snowball method and pay off some small balances to make you feel motivated, then start taking out your debt in full force with the stacking method: stop creating new debt, determine which balances have the highest interest rates, and create a payment schedule to pay them off efficiently. - - - - - - - - - - -With your debts whittled down, you should start an emergency fund. No matter how well you plan things, accidents and health emergencies can still happen. An emergency fund is designed to make those kinds of events more manageable. This type of savings account is strictly for when life throws you a curveball, but you can grow one pretty easily with only modest savings. - - - - - - - - - - -When you've paid off your debt and prepared yourself for troubled times, you can start saving for the big stuff. All that money you're not spending on crap anymore can be saved, invested, and compounded to let you buy comfort and security. If you don't know where to start, talk to a financial planner. Or create a simple, yet effective "set and forget" investment portfolio. You've worked hard to reprogram your mind, so make sure you reap the benefits for many years to come. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -Photos by cmgirl (Shutterstock), Macrovector (Shutterstock), J E Theriot, davidd, George Redgrave, David Amsler, Arup Malakar, J B, jakerome, 401(K) 2012. 36 146Reply <span id="js_reply-count" class="proxima text-small mlm mrn">146<span class="icon icon-bubble-round oversized"></span></span><script>document.getElementById('js_reply-count').style.display = 'inline';</script><a href="#" class="reply-to-post reply-count hover-icon proxima text-small" rel="nofollow">Discuss<span class="icon icon-bubble-round oversized"></span></a>
- - - - - - - - - - - - - - - - - - - - - Open Journalism Project: - - - - Better Student Journalism - - - - - - - - We pushed out the first version of the Open Journalism site in January. Our goal is for the - site to be a place to teach students what they should know about journalism - on the web. It should be fun too. - Topics like mapping, security, command - line tools, and open source are - all concepts that should be made more accessible, and should be easily - understood at a basic level by all journalists. We’re focusing on students - because we know student journalism well, and we believe that teaching maturing - journalists about the web will provide them with an important lens to view - the world with. This is how we got to where we are now. - Circa 2011 - In late 2011 I sat in the design room of our university’s student newsroom - with some of the other editors: Kate Hudson, Brent Rose, and Nicholas Maronese. - I was working as the photo editor then—something I loved doing. I was very - happy travelling and photographing people while listening to their stories. - Photography was my lucky way of experiencing the many types of people - my generation seemed to avoid, as well as many the public spends too much - time discussing. One of my habits as a photographer was scouring sites - like Flickr to see how others could frame the world in ways I hadn’t previously - considered. - - - - - - topleftpixel.com - - I started discovering beautiful things the web could do with images: - things not possible with print. Just as every generation revolts against - walking in the previous generations shoes, I found myself questioning the - expectations that I came up against as a photo editor. In our newsroom - the expectations were built from an outdated information world. We were - expected to fill old shoes. - So we sat in our student newsroom—not very happy with what we were doing. - Our weekly newspaper had remained essentially unchanged for 40+ years. - Each editorial position had the same requirement every year. The big change - happened in the 80s when the paper started using colour. We’d also stumbled - into having a website, but it was updated just once a week with the release - of the newspaper. - Information had changed form, but the student newsroom hadn’t, and it - was becoming harder to romanticize the dusty newsprint smell coming from - the shoes we were handed down from previous generations of editors. It - was, we were told, all part of “becoming a journalist.” - - - - - - - We don’t know what we don’t know - We spent much of the rest of the school year asking “what should we be - doing in the newsroom?”, which mainly led us to ask “how do we use the - web to tell stories?” It was a straightforward question that led to many - more questions about the web: something we knew little about. Out in the - real world, traditional journalists were struggling to keep their jobs - in a dying print world. They wore the same design of shoes that we were - supposed to fill. Being pushed to repeat old, failing strategies and blocked - from trying something new scared us. - We had questions, so we started doing some research. We talked with student - newsrooms in Canada and the United States, and filled too many Google Doc - files with notes. Looking at the notes now, they scream of fear. We annotated - our notes with naive solutions, often involving scrambled and immature - odysseys into the future of online journalism. - There was a lot we didn’t know. We didn’t know how to build a mobile app. - We didn’t know if we should build a mobile app. - We didn’t know how to run a server. - We didn’t know where to go to find a server. - We didn’t know how the web worked. - We didn’t know how people used the web to read news. - We didn’t know what news should be on the web. - If news is just information, what does that even look like? - We asked these questions to many students at other papers to get a consensus - of what had worked and what hadn’t. They reported similar questions and - fears about the web but followed with “print advertising is keeping us - afloat so we can’t abandon it”. - In other words, we knew that we should be building a newer pair of shoes, - but we didn’t know what the function of the shoes should be. - Common problems in student newsrooms (2011) - Our questioning of other student journalists in 15 student newsrooms brought - up a few repeating issues. - - Lack of mentorship - A news process that lacked consideration of the web - No editor/position specific to the web - Little exposure to many of the cool projects being put together by professional - newsrooms - Lack of diverse skills within the newsroom. Writers made up 95% of the - personnel. Students with other skills were not sought because journalism - was seen as “a career with words.” The other 5% were designers, designing - words on computers, for print. - Not enough discussion between the business side and web efforts - - - - - - - From our 2011 research - - Common problems in student newsrooms (2013) - Two years later, we went back and looked at what had changed. We talked - to a dozen more newsrooms and weren’t surprised by our findings. - - Still no mentorship or link to professional newsrooms building stories - for the web - Very little control of website and technology - The lack of exposure that student journalists have to interactive storytelling. - While some newsrooms are in touch with what’s happening with the web and - journalism, there still exists a huge gap between the student newsroom - and its professional counterpart - No time in the current news development cycle for student newsrooms to - experiment with the web - Lack of skill diversity (specifically coding, interaction design, and - statistics) - Overly restricted access to student website technology. Changes are primarily - visual rather than functional. - Significantly reduced print production of many papers - Computers aren’t set up for experimenting with software and code, and - often locked down - - Newsrooms have traditionally been covered in copies of The New York Times - or Globe and Mail. Instead newsrooms should try spend at 20 minutes each - week going over the coolest/weirdest online storytelling in an effort to - expose each other to what is possible. “Hey, what has the New York Times R&D lab been up to this week?” - Instead of having computers that are locked down, try setting aside a - few office computers that allow students to play and “break”, or encourage - editors to buy their own Macbooks so they’re always able to practice with - code and new tools on their own. - From all this we realized that changing a student newsroom is difficult. - It takes patience. It requires that the business and editorial departments - of the student newsroom be on the same (web)page. The shoes of the future - must be different from the shoes we were given. - We need to rethink how long the new shoe design will be valid. It’s more - important that we focus on the process behind making footwear than on actually - creating a specific shoe. We shouldn’t be building a shoe to last 40 years. - Our footwear design process will allow us to change and adapt as technology - evolves. The media landscape will change, so having a newsroom that can - change with it will be critical. - We are building a shoe machine, not a shoe. - - - - - A train or light at the end of the tunnel: are student newsrooms changing for the better? - - - - In our 2013 research we found that almost 50% of student newsrooms had - created roles specifically for the web. This sounds great, but is still problematic in its current state. - - - - - - - We designed many of these slides to help explain to ourselves what we were doing - - - When a newsroom decides to create a position for the web, it’s often with - the intent of having content flow steadily from writers onto the web. This - is a big improvement from just uploading stories to the web whenever there - is a print issue. However… - - - The handoff - Problems arise because web editors are given roles that absolve the rest - of the editors from thinking about the web. All editors should be involved - in the process of story development for the web. While it’s a good idea - to have one specific editor manage the website, contributors and editors - should all play with and learn about the web. Instead of “can you make - a computer do XYZ for me?”, we should be saying “can you show me how to - make a computer do XYZ?” - Not just social mediaA - web editor could do much more than simply being in charge of the social - media accounts for the student paper. Their responsibility could include - teaching all other editors to be listening to what’s happening online. - The web editor can take advantage of live information to change how the - student newsroom reports news in real time. - Web (interactive) editorThe - goal of having a web editor should be for someone to build and tell stories - that take full advantage of the web as their medium. Too often the web’s - interactivity is not considered when developing the story. The web then - ends up as a resting place for print words. - - Editors at newsrooms are still figuring out how to convince writers of - the benefit to having their content online. There’s still a stronger draw - to writers seeing their name in print than on the web. Showing writers - that their stories can be told in new ways to larger audiences is a convincing - argument that the web is a starting point for telling a story, not its - graveyard. - When everyone in the newsroom approaches their website with the intention - of using it to explore the web as a medium, they all start to ask “what - is possible?” and “what can be done?” You can’t expect students to think - in terms of the web if it’s treated as a place for print words to hang - out on a web page. - We’re OK with this problem, if we see newsrooms continue to take small - steps towards having all their editors involved in the stories for the - web. - - - - - - The current Open Journalism site was a few years in the making. This was - an original launch page we use in 2012 - - What we know - - New process - Our rough research has told us newsrooms need to be reorganized. This - includes every part of the newsroom’s workflow: from where a story and - its information comes from, to thinking of every word, pixel, and interaction - the reader will have with your stories. If I was a photo editor that wanted - to re-think my process with digital tools in mind, I’d start by asking - “how are photo assignments processed and sent out?”, “how do we receive - images?”, “what formats do images need to be exported in?”, “what type - of screens will the images be viewed on?”, and “how are the designers getting - these images?” Making a student newsroom digital isn’t about producing - “digital manifestos”, it’s about being curious enough that you’ll want - to to continue experimenting with your process until you’ve found one that - fits your newsroom’s needs. - More (remote) mentorship - Lack of mentorship is still a big problem. Google’s fellowship program is great. The fact that it - only caters to United States students isn’t. There are only a handful of - internships in Canada where students interested in journalism can get experience - writing code and building interactive stories. We’re OK with this for now, - as we expect internships and mentorship over the next 5 years between professional - newsrooms and student newsrooms will only increase. It’s worth noting that - some of that mentorship will likely be done remotely. - Changing a newsroom culture - Skill diversity needs to change. We encourage every student newsroom we - talk to, to start building a partnership with their school’s Computer Science - department. It will take some work, but you’ll find there are many CS undergrads - that love playing with web technologies, and using data to tell stories. - Changing who is in the newsroom should be one of the first steps newsrooms - take to changing how they tell stories. The same goes with getting designers - who understand the wonderful interactive elements of the web and students - who love statistics and exploring data. Getting students who are amazing - at design, data, code, words, and images into one room is one of the coolest - experience I’ve had. Everyone benefits from a more diverse newsroom. - - What we don’t know - - Sharing curiosity for the web - We don’t know how to best teach students about the web. It’s not efficient - for us to teach coding classes. We do go into newsrooms and get them running - their first code exercises, but if someone wants to learn to program, we - can only provide the initial push and curiosity. We will be trying out - “labs” with a few schools next school year to hopefully get a better idea - of how to teach students about the web. - Business - We don’t know how to convince the business side of student papers that - they should invest in the web. At the very least we’re able to explain - that having students graduate with their current skill set is painful in - the current job market. - The future - We don’t know what journalism or the web will be like in 10 years, but - we can start encouraging students to keep an open mind about the skills - they’ll need. We’re less interested in preparing students for the current - newsroom climate, than we are in teaching students to have the ability - to learn new tools quickly as they come and go. - - - - - - - - - Another slide from 2012 website - - - - What we’re trying to share with others - - A concise guide to building stories for the web - There are too many options to get started. We hope to provide an opinionated - guide that follows both our experiences, research, and observations from - trying to teach our peers. - - Student newsrooms don’t have investors to please. Student newsrooms can - change their website every week if they want to try a new design or interaction. - As long as students start treating the web as a different medium, and start - building stories around that idea, then we’ll know we’re moving forward. - A note to professional news orgs - We’re also asking professional newsrooms to be more open about their process - of developing stories for the web. You play a big part in this. This means - writing about it, and sharing code. We need to start building a bridge - between student journalism and professional newsrooms. - - - - - - 2012 - - This is a start - We going to continue slowly growing the content on Open Journalism. We still consider this the beta version, - but expect to polish it, and beef up the content for a real launch at the - beginning of the summer. - We expect to have more original tutorials as well as the beginnings of - what a curriculum may look like that a student newsroom can adopt to start - guiding their transition to become a web first newsroom. We’re also going - to be working with the Queen’s Journal and - The Ubysseynext school year to better understand how to make the student - newsroom a place for experimenting with telling stories on the web. If - this sound like a good idea in your newsroom, we’re still looking to add - 1 more school. - We’re trying out some new shoes. And while they’re not self-lacing, and - smell a bit different, we feel lacing up a new pair of kicks can change - a lot. - - - - - - - - - - Let’s talk. Let’s listen. - - We’re still in the early stages of what this project will look like, so if you want to help or have thoughts, let’s talk. - - pippin@pippinlee.com - - - - - - - - This isn’t supposed to be a - manifesto™© - we just think it’s pretty cool to share what we’ve learned so far, and hope you’ll do the same. We’re all in this together. - - - - - - - - - - - RecommendRecommended - - - - - - - - BookmarkBookmarked - - Share - - More - - - - - - - - - - - - - Written on - Mar 17 - byPippin Lee - I don’t know much, so I better start here. - - - - FollowFollowing - - - - - Thanks to Asad Chishti. - - - - - - - - - -
Words need defenders.On Behalf of “Literally”You either are a “literally” abuser or know of one. If you’re anything like me, hearing the word “literally” used incorrectly causes a little piece of your soul to whither and die. Of course I do not mean that literally, I mean that figuratively. An abuser would have said: “Every time a person uses that word, a piece of my soul literally withers and dies.” Which is terribly, horribly wrong.For whatever bizarre reason, people feel the need to use literally as a sort of verbal crutch. They use it to emphasize a point, which is silly because they’re already using an analogy or a metaphor to illustrate said point. For example: “Ugh, I literally tore the house apart looking for my remote control!” No, you literally did not tear apart your house, because it’s still standing. If you’d just told me you “tore your house apart” searching for your remote, I would’ve understood what you meant. No need to add “literally” to the sentence.Maybe I should define literally.Literally means actually. When you say something literally happened, you’re describing the scene or situation as it actually happened.So you should only use literally when you mean it. It should not be used in hyperbole. Example: “That was so funny I literally cried.” Which is possible. Some things are funny enough to elicit tears. Note the example stops with “literally cried.” You cannot literally cry your eyes out. The joke wasn’t so funny your eyes popped out of their sockets.When in Doubt, Leave it Out“I’m so hungry I could eat a horse,” means you’re hungry. You don’t need to say “I’m so hungry I could literally eat a horse.” Because you can’t do that in one sitting, I don’t care how big your stomach is.“That play was so funny I laughed my head off,” illustrates the play was amusing. You don’t need to say you literally laughed your head off, because then your head would be on the ground and you wouldn’t be able to speak, much less laugh.“I drove so fast my car was flying,” we get your point: you were speeding. But your car is never going fast enough to fly, so don’t say your car was literally flying.Insecurities?Maybe no one believed a story you told as a child, and you felt the need to prove that it actually happened. No really, mom, I literally climbed the tree. In efforts to prove truth, you used literally to describe something real, however outlandish it seemed. Whatever the reason, now your overuse of literally has become a habit.Hard Habit to Break?Abusing literally isn’t as bad a smoking, but it’s still an unhealthy habit (I mean that figuratively). Help is required in order to break it.This is my version of an intervention for literally abusers. I’m not sure how else to do it other than in writing. I know this makes me sound like a know-it-all, and I accept that. But there’s no excuse other than blatant ignorance to misuse the word “literally.” So just stop it.Don’t say “Courtney, this post is so snobbish it literally burned up my computer.” Because nothing is that snobbish that it causes computers to combust. Or: “Courtney, your head is so big it literally cannot get through the door.” Because it can, unless it’s one of those tiny doors from Alice in Wonderland and I need to eat a mushroom to make my whole body smaller.No One’s PerfectAnd I’m not saying I am. I’m trying to restore meaning to a word that’s lost meaning. I’m standing up for literally. It’s a good word when used correctly. People are butchering it and destroying it every day (figuratively speaking) and the massacre needs to stop. Just as there’s a coalition of people against the use of certain fonts (like Comic Sans and Papyrus), so should there be a coalition of people against the abuse of literally.Saying it to Irritate?Do you misuse the word “literally” just to annoy your know-it-all or grammar police friends/acquaintances/total strangers? If so, why? Doing so would be like me going outside when it’s freezing, wearing nothing but a pair of shorts and t-shirt in hopes of making you cold by just looking at me. Who suffers more?Graphical RepresentationMatthew Inman of “The Oatmeal” wrote a comic about literally. Abusers and defenders alike should check it out. It’s clear this whole craze about literally is driving a lot of us nuts. You literally abusers are killing off pieces of our souls. You must be stopped, or the world will be lost to meaninglessness forever. Figuratively speaking.Originally published at www.courtneykirchoff.com on November 18, 2011. Sadly this solo post did not stop the abuse of literally. Help the word out. Recommend this article to your literally abusers in your life.RecommendRecommendedBookmarkBookmarkedShareMoreWritten on Feb 24 byCourtney KirchoffFreelance writer and graphic designer. Will work for bacon. Wrote a novel: Jaden Baker. See my work: www.courtneykirchoff.com & www.truenorthe.comFollowFollowing
- - - - - - - - John C. WelchBlockedUnblockFollowFollowing - Oct 15, 2015 - - - - - - - - - - - - - Samantha and The Great Big Lie - How to get shanked doing what people say they want - don’t preach to meMr. integrity - (EDIT: removed the link to Samantha’s post, because the arments and the grubers and the rest of The Deck Clique got what they wanted: a non-proper person driven off the internet lightly capped with a dusting of transphobia along the way, all totally okay because the ends justify the means, and it’s okay when “good” people do it.) - First, I need to say something about this article: the reason I’m writing it infuriates me. Worse than installing CS 3 or Acrobat 7 ever did, and the former inspired comparisons to fecophile porn. I’m actually too mad to cuss. Well, not completely, but in this case, I don’t think the people I’m mad at are worth the creativity I try to put into profanity. This is about a brownfield of hypocrisy and viciously deliberate mischaracterization that “shame” cannot even come close to the shame those behind it should feel. - Now, read this post by Samantha Bielefeld: The Elephant in the Room. First, it is a well-written critical piece that raises a few points in a calm, rational, nonconfrontational fashion, exactly the kind of things the pushers of The Great Big Lie say we need more of, as opposed to the screaming that is the norm in such cases. - …sorry, I should explain “The Great Big Lie”. There are several, but in this case, our specific instance of “The Great Big Lie” is about criticism. Over and over, you hear from the very people I am not going to be nice to in this that we need “better” criticsm. Instead of rage and anger, volume and vitriol, we need in-depth rational criticism, that isn’t personal or ad hominem. That it should focus on points, not people. - That, readers, is “The Big Lie”. It is a lie so big that if one ponders the reality of it, as I am going to, one wonders why anyone would believe it. It is a lie and it is one we should stop telling. - - - - - - - - - - Samantha’s points (I assume you read it, for you are smart people who know the importance of such things) are fairly clear: - - With the release of Overcast 2.0, a product Samantha actually likes, Marco Arment moved to a patronage model that will probably be successful for him. - Arment’s insistence that “anyone can do this” while technically true, (anyone can in fact, implement this pricing model), also implies that “anyone” can have the kind of success that a developer with Marco’s history, financial status, and deep ties to the Apple News Web is expected to have. This is silly. - Marco Arment occupies a fairly unique position in the Apple universe, (gained by hard work and no small talent), and because of that, benefits from a set of privileges that a new developer or even one that has been around for a long time, but isn’t, well, Marco, not only don’t have, but have little chance of attaining anytime soon. - Marco has earned his success and is entitled to the benefits and privileges it brings, but he seems rather blind to all of that, and seems to still imagine himself as “two guys in a garage”. This is just not correct. - In addition, the benefits and privileges of the above ensure that by releasing Overcast 2 as a free app, with patronage pricing, he has, if not gutted, severely hurt the ability of folks actually selling their apps for an up-front price of not free to continue doing so. This has the effect of accelerating the “race to the bottom” in the podcast listening app segment, which hurts devs who cannot afford to work on a “I don’t really need this money, so whatever you feel like sending is okay” model. - - None of this is incorrect. None of this is an ad hominem attack in any way. It is just pointing out that a developer of Arment’s stature and status lives in a very different world than someone in East Frog Balls, Arkansas trying to make a living off of App sales. Our dev in EFB doesn’t have the main sites on the Apple web falling all over themselves to review their app the way that Arment does. They’re not friends with the people being The Loop, Daring Fireball, SixColors, iMore, The Mac Observer, etc., yadda. - So, our hero, in a fit of well-meaning ignorance writes this piece (posted this morning, 14 Oct. 15) and of course, the response and any criticisms are just as reasonable and thoughtful. - If you really believe that, you are the most preciously ignorant person in the world, and can I have your seriously charmed life. - - - - - - - - - - The response, from all quarters, including Marco, someone who is so sensitive to criticism that the word “useless” is enough to shut him down, who blocked a friend of mine for the high crime of pointing out that his review of podcasting mics centered around higher priced gear and ignored folks without the scratch, who might not be ready for such things, is, in a single word, disgusting. Vomitous even. - It’s an hours-long dogpile that beggars even my imagination, and I can imagine almost anything. Seriously, it’s all there in Samantha’s Twitter Feed. From what I can tell, she’s understandably shocked over it. I however was not. This one comment in her feed made me smile (warning, this wanders a bit…er…LOT. Twitter timelines are not easy to put together): - I can see why you have some reservations about publishing it, but my gut feeling is that he would take it better than Nilay. - Oh honey, bless your sweet, ignorant heart. Marco is one of the biggest pushers of The Big Lie, and one of the reasons it is such a lie. - But it gets better. First, you have the “hey, Marco earned his status!” lot. A valid point, and one Bielefeld explicitly acknowledges, here: - From his ground floor involvement in Tumblr (for which he is now a millionaire), to the creation and sale of a wildly successful app called Instapaper, he has become a household name in technology minded circles. It is this extensive time spent in the spotlight, the huge following on Twitter, and dedicated listeners of his weekly aired Accidental Tech Podcast, that has granted him the freedom to break from seeking revenue in more traditional manners. - and here: - I’m not knocking his success, he has put effort into his line of work, and has built his own life. - and here: - He has earned his time in the spotlight, and it’s only natural for him to take advantage of it. - But still, you get the people telling her something she already acknowledge: - I don’t think he’s blind. he’s worked to where he has gotten and has had failures like everyone else. - Thank you for restating something in the article. To the person who wrote it. - In the original article, Samantha talked about the money Marco makes from his podcast. She based that on the numbers provided by ATP in terms of sponsorship rates and the number of current sponsors the podcast has. Is this going to yield perfect numbers? No. But the numbers you get from it will at least be reasonable, or should be unless the published sponsorship rates are just fantasy, and you’re stupid for taking them seriously. - At first, she went with a simple formula: - $4K x 3 per episode = $12K x 52 weeks / 3 hosts splitting it. - That’s not someone making shit up, right? Rather quickly, someone pointed out that she’d made an error in how she calculated it: - That’s $4k per ad, no? So more like $12–16k per episode. - She’d already realized her mistake and fixed it. - which is actually wrong, and I’m correcting now. $4,000 per sponsor, per episode! So, $210,000 per year. - Again, this is based on publicly available data the only kind someone not part of ATP or a close friend of Arment has access to. So while her numbers may be wrong, if they are, there’s no way for her to know that. She’s basing her opinion on actual available data. Which is sadly rare. - This becomes a huge flashpoint. You name a reason to attack her over this, people do. No really. For example, she’s not calculating his income taxes correctly: - especially since it isn’t his only source of income thus, not an indicator of his marginal inc. tax bracket. - thus, guessing net income is more haphazard than stating approx. gross income. - Ye Gods. She’s not doing his taxes for him, her point is invalid? - Then there’s the people who seem to have not read anything past what other people are telling them: - Not sure what to make of your Marco piece, to be honest. You mention his fame, whatever, but what’s the main idea here? - Just how spoon-fed do you have to be? Have you no teeth? - Of course, Marco jumps in, and predictably, he’s snippy: - If you’re going to speak in precise absolutes, it’s best to first ensure that you’re correct. - If you’re going to be like that, it’s best to provide better data. Don’t get snippy when someone is going off the only data available, and is clearly open to revising based on better data. - Then Marco’s friends/fans get into it: - I really don’t understand why it’s anyone’s business - Samantha is trying to qualify for sainthood at this point: - It isn’t really, it was a way of putting his income in context in regards to his ability to gamble with Overcast. - Again, she’s trying to drag people back to her actual point, but no one is going to play. The storm has begun. Then we get people who are just spouting nonsense: - Why is that only relevant for him? It’s a pretty weird metric,especially since his apps aren’t free. - Wha?? Overcast 2 is absolutely free. Samantha points this out: - His app is free, that’s what sparked the article to begin with. - The response is literally a parallel to “How can there be global warming if it snowed today in my town?” - If it’s free, how have I paid for it? Twice? - She is still trying: - You paid $4.99 to unlock functionality in Overcast 1.0 and you chose to support him with no additional functionality in 2.0 - He is having none of it. IT SNOWED! SNOWWWWWWW! - Yes. That’s not free. Free is when you choose not to make money. And that can be weaponized. But that’s not what Overcast does. - She however, is relentless: - No, it’s still free. You can choose to support it, you are required to pay $4.99 for Pocket Casts. Totally different model. - Dude seems to give up. (Note: allllll the people bagging on her are men. All of them. Mansplaining like hell. And I’d bet every one of them considers themselves a feminist.) - We get another guy trying to push the narrative she’s punishing him for his success, which is just…it’s stupid, okay? Stupid. - It also wasn’t my point in writing my piece today, but it seems to be everyone’s focus. - (UNDERSTATEMENT OF THE YEAR) - I think the focus should be more on that fact that while it’s difficult, Marco spent years building his audience. - It doesn’t matter what he makes it how he charges. If the audience be earned is willing to pay for it, awesome. - She tries, oh lord, she tries: - To assert that he isn’t doing anything any other dev couldn’t, is wrong. It’s successful because it’s Marco. - But no, HE KNOWS HER POINT BETTER THAN SHE DOES: - No, it’s successful because he busted his ass to make it so. It’s like any other business. He grew it. - Christ. This is like a field of strawmen. Stupid ones. Very stupid ones. - One guy tries to blame it all on Apple, another in a string of Wha??? moments: - the appropriate context is Apple’s App Store policies. Other devs aren’t Marco’s responsibility - Seriously? Dude, are you even trying to talk about what Samantha actually wrote? At this point, Samantha is clearly mystified at the entire thing: - Why has the conversation suddenly turned to focus on nothing more than ATP sponsorship income? - Because it’s a nit they can pick and allows them to ignore everything you wrote. That’s the only reason. - One guy is “confused”: - I see. He does have clout, so are you saying he’s too modest in how he sees himself as a dev? - Yes. He can’t be equated to the vast majority of other developers. Like calling Gruber, “just another blogger”. - Alright, that’s fair. I was just confused by the $ and fame angle at first. - Samantha’s point centers on the benefits Marco gains via his fame and background. HOW DO YOU NOT MENTION THAT? HOW IS THAT CONFUSING? - People of course are telling her it’s her fault for mentioning a salient fact at all: - Why has the conversation suddenly turned to focus on nothing more than ATP sponsorship income? - Maybe because you went there with your article? - As a way of rationalizing his ability to gamble with the potential for Overcast to generate income…not the norm at all. - Of course, had she not brought up those important points, she’d have been bagged on for “not providing proof”. Lose some, lose more. By now, she’s had enough and she just deletes all mention of it. Understandable, but sad she was bullied into doing that. - Yes, bullied. That’s all this is. Bullying. She didn’t lie, cheat, or exaagerate. If her numbers were wrong, they weren’t wrong in a way she had any ability to do anything about. But there’s blood in the water, and the comments and attacks get worse: - Because you decided to start a conversation about someone else’s personal shit. You started this war. - War. THIS. IS. WAR. - This is a bunch of nerds attacking someone for reasoned, calm, polite criticism of their friend/idol. Samantha is politely pushing back a bit: - That doesn’t explain why every other part of my article is being pushed aside. - She’s right. This is all nonsense. This is people ignoring her article completely, just looking for things to attack so it can be dismissed. It’s tribalism at its purest. - Then some of the other annointed get into it, including Jason Snell in one of the most spectactular displays of “I have special knowledge you can’t be expected to have, therefore you are totally off base and wrong, even though there’s no way for you to know this” I’ve seen in a while. Jason: - You should never use an ad rate card to estimate ad revenue from any media product ever. - I learned this when I started working for a magazine — rate cards are mostly fiction, like prices on new cars - How…exactly…in the name of whatever deity Jason may believe in…is Samantha or anyone not “in the biz” supposed to know this. Also, what exactly does a magazine on paper like Macworld have to do with sponsorships for a podcast? I have done podcasts that were sponsored, and I can retaliate with “we charged what the rate card said we did. Checkmate Elitests!” - Samantha basically abases herself at his feet: - I understand my mistake, and it’s unfortunate that it has completely diluted the point of my article. - I think she should have told him where and how to stuff that nonsense, but she’s a nicer person than I am. Also, it’s appropriate that Jason’s twitter avatar has its nose in the air. This is some rank snobbery. It’s disgusting and if anyone pulled that on him, Jason would be very upset. But hey, one cannot criticize The Marco without getting pushback. By “pushback”, I mean “an unrelenting fecal flood”. - Her only mistake was criticizing one of the Kool Kids. Folks, if you criticize anyone in The Deck Clique, or their friends, expect the same thing, regardless of tone or point. - Another App Dev, seemingly unable to parse Samantha’s words, needs more explanation: - so just looking over your mentions, I’m curious what exactly was your main point? Ignoring the podcast income bits. - Oh wait, he didn’t even read the article. Good on you, Dev Guy, good. on. you. Still, she plays nice with someone who didn’t even read her article: - That a typical unknown developer can’t depend on patronage to generate revenue, and charging for apps will become a negative. - Marco comes back of course, and now basically accuses her of lying about other devs talking to her and supporting her point: - How many actual developers did you hear from, really? Funny how almost nobody wants to give a (real) name on these accusations. - Really? You’re going to do that? “There’s no name, so I don’t think it’s a real person.” Just…what’s the Joe Welch quote from the McCarthy hearings? - Let us not assassinate this lad further, Senator. You’ve done enough. Have you no sense of decency, sir? At long last, have you left no sense of decency? - That is what this is at this point: character assasination because she said something critical of A Popular Person. It’s disgusting. Depressing and disgusting. No one, none of these people have seriously discussed her point, heck, it looks like they barely bothered to read it, if they did at all. - Marco starts getting really petty with her (no big shock) and Samantha finally starts pushing back: - Glad to see you be the bigger person and ignore the mindset of so many developers not relating to you, good for you! - That of course, is what caused Marco to question the validity, if not the existence of her sources. (Funny how anonymous sources are totes okay when they convenience Marco et al, and work for oh, Apple, but when they are inconvenient? Ha! PROVIDE ME PROOF YOU INTEMPERATE WOMAN!) - Make no mistake, there’s some sexist shit going on here. Every tweet I’ve quoted was authored by a guy. - Of course, Marco has to play the “I’ve been around longer than you” card with this bon mot: - Yup, before you existed! - Really dude? I mean, I’m sorry about the penis, but really? - Mind you, when the criticism isn’t just bizarrely stupid, Samantha reacts the way Marco and his ilk claim they would to (if they ever got any valid criticism. Which clearly is impossible): - Not to get into the middle of this, but “income” is not the term you’re looking for. “Revenue” is. - lol. Noted. - And I wasn’t intending to be a dick, just a lot of people hear/say “income” when they intend “revenue”, and then discussion … - … gets derailed by a jedi handwave of “Expenses”. But outside of charitable donation, it is all directly related. - haha. Thank you for the clarification. - Note to Marco and the other…whatever they are…that is how one reacts to that kind of criticism. With a bit of humor and self-deprecation. You should try it sometime. For real, not just in your heads or conversations in Irish Pubs in S.F. - But now, the door has been cracked, and the cheap shots come out: - @testflight_app: Don’t worry guys, we process @marcoarment’s apps in direct proportion to his megabucks earnings. #fairelephant - (Note: testflight_app is a parody account. Please do not mess with the actual testflight folks. They are still cool.) - Or this…conversation: - - - - - - - Good job guys. Good job. Defend the tribe. Attack the other. Frederico attempts to recover from his stunning display of demeaning douchery: @viticci: @s_bielefeld I don’t know if it’s an Italian thing, but counting other people’s money is especially weird for me. IMO, bad move in the post. - Samantha is clearly sick of his crap: @s_bielefeld: @viticci That’s what I’m referring to, the mistake of ever having mentioned it. So, now, Marco can ignore the bigger issue and go on living. - Good for her. There’s being patient and being roadkill. - Samantha does put the call out for her sources to maybe let her use their names: - From all of you I heard from earlier, anyone care to go on record? - My good friend, The Angry Drunk points out the obvious problem: - Nobody’s going to go on record when they count on Marco’s friends for their PR. - This is true. Again, the sites that are Friends of Marco: - Daring Fireball - The Loop - SixColors - iMore - MacStories - A few others, but I want this post to end one day. - You piss that crew off, and given how petty rather a few of them have demonstrated they are, good luck on getting any kind of notice from them. - Of course, the idea this could happen is just craycray: - @KevinColeman .@Angry_Drunk @s_bielefeld @marcoarment Wow, you guys are veering right into crazy conspiracy theory territory. #JetFuelCantMeltSteelBeams - Yeah. Because a mature person like Marco would never do anything like that. - Of course, the real point on this is starting to happen: - you’re getting a lot of heat now but happy you are writing things that stir up the community. Hope you continue to be a voice! - I doubt I will. - See, they’ve done their job. Mess with the bull, you get the horns. Maybe you should find another thing to write about, this isn’t a good place for you. Great job y’all. - Some people aren’t even pretending. They’re just in full strawman mode: - @timkeller: Unfair to begrudge a person for leveraging past success, especially when that success is earned. No ‘luck’ involved. - @s_bielefeld: @timkeller I plainly stated that I don’t hold his doing this against him. Way to twist words. - I think she’s earned her anger at this point. - Don’t worry, Marco knows what the real problem is: most devs just suck — - - - - - - - I have a saying that applies in this case: don’t place your head so far up your nethers that you go full Klein Bottle. Marco has gone full Klein Bottle. (To be correct, he went FKB some years ago.) - There are some bright spots. My favorite is when Building Twenty points out the real elephant in the room: - @BuildingTwenty: Both @s_bielefeld & I wrote similar critiques of @marcoarment’s pricing model yet the Internet pilloried only the woman. Who’d have guessed? - Yup. - Another bright spot are these comments from Ian Betteridge, who has been doing this even longer than Marco: - You know, any writer who has never made a single factual error in a piece hasn’t ever written anything worth reading. - I learned my job with the support of people who helped me. Had I suffered an Internet pile on for every error I wouldn’t have bothered. - To which Samantha understandably replies: - and it’s honestly something I’m contemplating right now, whether to continue… - Gee, I can’t imagine why. Why with comments like this from Chris Breen that completely misrepresent Samantha’s point, (who until today, I would have absolutely defended as being better than this, something I am genuinely saddened to be wrong about), why wouldn’t she want to continue doing this? - If I have this right, some people are outraged that a creator has decided to give away his work. - No Chris, you don’t have this right. But hey, who has time to find out the real issue and read an article. I’m sure your friends told you everything you need to know. - Noted Feminist Glenn Fleishman gets a piece of the action too: - - - - - - - I’m not actually surprised here. I watched Fleishman berate a friend of mine who has been an engineer for…heck, waaaaay too long on major software products in the most condescending way because she tried to point out that as a very technical woman, “The Magazine” literally had nothing to say to her and maybe he should fix that. “Impertinent” was I believe what he called her, but I may have the specific word wrong. Not the attitude mind you. Great Feminists like Glenn do not like uppity women criticizing Great Feminists who are their Great Allies. - Great Feminists are often tools. - - - - - - - - - - Luckily, I hope, the people who get Samantha’s point also started chiming in (and you get 100% of the women commenting here that I’ve seen): - I don’t think he’s wrong for doing it, he just discusses it as if the market’s a level playing field — it isn’t - This is a great article with lots of great points about the sustainability of iOS development. Thank you for publishing it. - Regardless of the numbers and your view of MA, fair points here about confirmation bias in app marketing feasibility http://samanthabielefeld.com/the-elephant-in-the-room … - thank you for posting this, it covers a lot of things people don’t like to talk about. - I’m sure you have caught untold amounts of flak over posting this because Marco is blind to his privilege as a developer. - Catching up on the debate, and agreeing with Harry’s remark. (Enjoyed your article, Samantha, and ‘got’ your point.) - - - - - - - - - - I would like to say I’m surprised at the reaction to Samantha’s article, but I’m not. In spite of his loud declarations of support for The Big Lie, Marco Arment is as bad at any form of criticism that he hasn’t already approved as a very insecure tween. An example from 2011: http://www.businessinsider.com/marco-arment-2011-9 - Marco is great with criticism as long as it never actually criticizes him. If it does, be prepared a flood of petty, petulant whining that a room full of bored preschoolers on a hot day would be hard-pressed to match. - Today has been…well, it sucks. It sucks because someone doing what all the Arments of the world claim to want was naive enough to believe what they were told, and found out the hard way just how big a lie The Big Lie is, and how vicious people are when you’re silly enough to believe anything they say about criticism. - And note again, every single condescending crack, misrepresentation, and strawman had an exclusively male source. Most of them have, at one point or another, loudly trumpted themselves as Feminist Allies, as a friend to women struggling with the sexism and misogyny in tech. Congratulations y’all on being just as bad as the people you claim to oppose. - Samantha has handled this better than anyone else could have. My respect for her as a person and a writer is off the charts. If she choses to walk away from blogging in the Apple space, believe me I understand. As bad as today was for her, I’ve seen worse. Much worse. - But I hope she doesn’t. I hope she stays, because she is Doing This Right, and in a corner of the internet that has become naught but an endless circle jerk, a cliquish collection, a churlish, childish cohort interested not in writing or the truth, but in making sure The Right People are elevated, and The Others put down, she is someone worth reading and listening to. The number people who owe her apologies goes around the block, and I don’t think she’ll ever see a one. I’m sure as heck not apologizing for them, I’ll not make their lives easier in the least. - All of you, all. of. you…Marco, Breen, Snell, Vittici, had a chance to live by your words. You were faced with reasoned, polite, respectful criticism and instead of what you should have done, you all dropped trou and sprayed an epic diarrheal discharge all over someone who had done nothing to deserve it. Me, I earned most of my aggro, Samantha did not earn any of the idiocy I’ve seen today. I hope you’re all proud of yourselves. Someone should be, it won’t be me. Ever. - So I hope she stays, but if she goes, I understand. For what it’s worth, I don’t think she’s wrong either way. - - - - - -
- - - - - - - - John C. WelchBlockedUnblockFollowFollowing - Oct 15, 2015 - - - - - - - - - - - - - Samantha and The Great Big Lie - How to get shanked doing what people say they want - don’t preach to meMr. integrity - (EDIT: removed the link to Samantha’s post, because the arments and the grubers and the rest of The Deck Clique got what they wanted: a non-proper person driven off the internet lightly capped with a dusting of transphobia along the way, all totally okay because the ends justify the means, and it’s okay when “good” people do it.) - First, I need to say something about this article: the reason I’m writing it infuriates me. Worse than installing CS 3 or Acrobat 7 ever did, and the former inspired comparisons to fecophile porn. I’m actually too mad to cuss. Well, not completely, but in this case, I don’t think the people I’m mad at are worth the creativity I try to put into profanity. This is about a brownfield of hypocrisy and viciously deliberate mischaracterization that “shame” cannot even come close to the shame those behind it should feel. - Now, read this post by Samantha Bielefeld: The Elephant in the Room. First, it is a well-written critical piece that raises a few points in a calm, rational, nonconfrontational fashion, exactly the kind of things the pushers of The Great Big Lie say we need more of, as opposed to the screaming that is the norm in such cases. - …sorry, I should explain “The Great Big Lie”. There are several, but in this case, our specific instance of “The Great Big Lie” is about criticism. Over and over, you hear from the very people I am not going to be nice to in this that we need “better” criticsm. Instead of rage and anger, volume and vitriol, we need in-depth rational criticism, that isn’t personal or ad hominem. That it should focus on points, not people. - That, readers, is “The Big Lie”. It is a lie so big that if one ponders the reality of it, as I am going to, one wonders why anyone would believe it. It is a lie and it is one we should stop telling. - - - - - - - - - - Samantha’s points (I assume you read it, for you are smart people who know the importance of such things) are fairly clear: - - With the release of Overcast 2.0, a product Samantha actually likes, Marco Arment moved to a patronage model that will probably be successful for him. - Arment’s insistence that “anyone can do this” while technically true, (anyone can in fact, implement this pricing model), also implies that “anyone” can have the kind of success that a developer with Marco’s history, financial status, and deep ties to the Apple News Web is expected to have. This is silly. - Marco Arment occupies a fairly unique position in the Apple universe, (gained by hard work and no small talent), and because of that, benefits from a set of privileges that a new developer or even one that has been around for a long time, but isn’t, well, Marco, not only don’t have, but have little chance of attaining anytime soon. - Marco has earned his success and is entitled to the benefits and privileges it brings, but he seems rather blind to all of that, and seems to still imagine himself as “two guys in a garage”. This is just not correct. - In addition, the benefits and privileges of the above ensure that by releasing Overcast 2 as a free app, with patronage pricing, he has, if not gutted, severely hurt the ability of folks actually selling their apps for an up-front price of not free to continue doing so. This has the effect of accelerating the “race to the bottom” in the podcast listening app segment, which hurts devs who cannot afford to work on a “I don’t really need this money, so whatever you feel like sending is okay” model. - - None of this is incorrect. None of this is an ad hominem attack in any way. It is just pointing out that a developer of Arment’s stature and status lives in a very different world than someone in East Frog Balls, Arkansas trying to make a living off of App sales. Our dev in EFB doesn’t have the main sites on the Apple web falling all over themselves to review their app the way that Arment does. They’re not friends with the people being The Loop, Daring Fireball, SixColors, iMore, The Mac Observer, etc., yadda. - So, our hero, in a fit of well-meaning ignorance writes this piece (posted this morning, 14 Oct. 15) and of course, the response and any criticisms are just as reasonable and thoughtful. - If you really believe that, you are the most preciously ignorant person in the world, and can I have your seriously charmed life. - - - - - - - - - - The response, from all quarters, including Marco, someone who is so sensitive to criticism that the word “useless” is enough to shut him down, who blocked a friend of mine for the high crime of pointing out that his review of podcasting mics centered around higher priced gear and ignored folks without the scratch, who might not be ready for such things, is, in a single word, disgusting. Vomitous even. - It’s an hours-long dogpile that beggars even my imagination, and I can imagine almost anything. Seriously, it’s all there in Samantha’s Twitter Feed. From what I can tell, she’s understandably shocked over it. I however was not. This one comment in her feed made me smile (warning, this wanders a bit…er…LOT. Twitter timelines are not easy to put together): - I can see why you have some reservations about publishing it, but my gut feeling is that he would take it better than Nilay. - Oh honey, bless your sweet, ignorant heart. Marco is one of the biggest pushers of The Big Lie, and one of the reasons it is such a lie. - But it gets better. First, you have the “hey, Marco earned his status!” lot. A valid point, and one Bielefeld explicitly acknowledges, here: - From his ground floor involvement in Tumblr (for which he is now a millionaire), to the creation and sale of a wildly successful app called Instapaper, he has become a household name in technology minded circles. It is this extensive time spent in the spotlight, the huge following on Twitter, and dedicated listeners of his weekly aired Accidental Tech Podcast, that has granted him the freedom to break from seeking revenue in more traditional manners. - and here: - I’m not knocking his success, he has put effort into his line of work, and has built his own life. - and here: - He has earned his time in the spotlight, and it’s only natural for him to take advantage of it. - But still, you get the people telling her something she already acknowledge: - I don’t think he’s blind. he’s worked to where he has gotten and has had failures like everyone else. - Thank you for restating something in the article. To the person who wrote it. - In the original article, Samantha talked about the money Marco makes from his podcast. She based that on the numbers provided by ATP in terms of sponsorship rates and the number of current sponsors the podcast has. Is this going to yield perfect numbers? No. But the numbers you get from it will at least be reasonable, or should be unless the published sponsorship rates are just fantasy, and you’re stupid for taking them seriously. - At first, she went with a simple formula: - $4K x 3 per episode = $12K x 52 weeks / 3 hosts splitting it. - That’s not someone making shit up, right? Rather quickly, someone pointed out that she’d made an error in how she calculated it: - That’s $4k per ad, no? So more like $12–16k per episode. - She’d already realized her mistake and fixed it. - which is actually wrong, and I’m correcting now. $4,000 per sponsor, per episode! So, $210,000 per year. - Again, this is based on publicly available data the only kind someone not part of ATP or a close friend of Arment has access to. So while her numbers may be wrong, if they are, there’s no way for her to know that. She’s basing her opinion on actual available data. Which is sadly rare. - This becomes a huge flashpoint. You name a reason to attack her over this, people do. No really. For example, she’s not calculating his income taxes correctly: - especially since it isn’t his only source of income thus, not an indicator of his marginal inc. tax bracket. - thus, guessing net income is more haphazard than stating approx. gross income. - Ye Gods. She’s not doing his taxes for him, her point is invalid? - Then there’s the people who seem to have not read anything past what other people are telling them: - Not sure what to make of your Marco piece, to be honest. You mention his fame, whatever, but what’s the main idea here? - Just how spoon-fed do you have to be? Have you no teeth? - Of course, Marco jumps in, and predictably, he’s snippy: - If you’re going to speak in precise absolutes, it’s best to first ensure that you’re correct. - If you’re going to be like that, it’s best to provide better data. Don’t get snippy when someone is going off the only data available, and is clearly open to revising based on better data. - Then Marco’s friends/fans get into it: - I really don’t understand why it’s anyone’s business - Samantha is trying to qualify for sainthood at this point: - It isn’t really, it was a way of putting his income in context in regards to his ability to gamble with Overcast. - Again, she’s trying to drag people back to her actual point, but no one is going to play. The storm has begun. Then we get people who are just spouting nonsense: - Why is that only relevant for him? It’s a pretty weird metric,especially since his apps aren’t free. - Wha?? Overcast 2 is absolutely free. Samantha points this out: - His app is free, that’s what sparked the article to begin with. - The response is literally a parallel to “How can there be global warming if it snowed today in my town?” - If it’s free, how have I paid for it? Twice? - She is still trying: - You paid $4.99 to unlock functionality in Overcast 1.0 and you chose to support him with no additional functionality in 2.0 - He is having none of it. IT SNOWED! SNOWWWWWWW! - Yes. That’s not free. Free is when you choose not to make money. And that can be weaponized. But that’s not what Overcast does. - She however, is relentless: - No, it’s still free. You can choose to support it, you are required to pay $4.99 for Pocket Casts. Totally different model. - Dude seems to give up. (Note: allllll the people bagging on her are men. All of them. Mansplaining like hell. And I’d bet every one of them considers themselves a feminist.) - We get another guy trying to push the narrative she’s punishing him for his success, which is just…it’s stupid, okay? Stupid. - It also wasn’t my point in writing my piece today, but it seems to be everyone’s focus. - (UNDERSTATEMENT OF THE YEAR) - I think the focus should be more on that fact that while it’s difficult, Marco spent years building his audience. - It doesn’t matter what he makes it how he charges. If the audience be earned is willing to pay for it, awesome. - She tries, oh lord, she tries: - To assert that he isn’t doing anything any other dev couldn’t, is wrong. It’s successful because it’s Marco. - But no, HE KNOWS HER POINT BETTER THAN SHE DOES: - No, it’s successful because he busted his ass to make it so. It’s like any other business. He grew it. - Christ. This is like a field of strawmen. Stupid ones. Very stupid ones. - One guy tries to blame it all on Apple, another in a string of Wha??? moments: - the appropriate context is Apple’s App Store policies. Other devs aren’t Marco’s responsibility - Seriously? Dude, are you even trying to talk about what Samantha actually wrote? At this point, Samantha is clearly mystified at the entire thing: - Why has the conversation suddenly turned to focus on nothing more than ATP sponsorship income? - Because it’s a nit they can pick and allows them to ignore everything you wrote. That’s the only reason. - One guy is “confused”: - I see. He does have clout, so are you saying he’s too modest in how he sees himself as a dev? - Yes. He can’t be equated to the vast majority of other developers. Like calling Gruber, “just another blogger”. - Alright, that’s fair. I was just confused by the $ and fame angle at first. - Samantha’s point centers on the benefits Marco gains via his fame and background. HOW DO YOU NOT MENTION THAT? HOW IS THAT CONFUSING? - People of course are telling her it’s her fault for mentioning a salient fact at all: - Why has the conversation suddenly turned to focus on nothing more than ATP sponsorship income? - Maybe because you went there with your article? - As a way of rationalizing his ability to gamble with the potential for Overcast to generate income…not the norm at all. - Of course, had she not brought up those important points, she’d have been bagged on for “not providing proof”. Lose some, lose more. By now, she’s had enough and she just deletes all mention of it. Understandable, but sad she was bullied into doing that. - Yes, bullied. That’s all this is. Bullying. She didn’t lie, cheat, or exaagerate. If her numbers were wrong, they weren’t wrong in a way she had any ability to do anything about. But there’s blood in the water, and the comments and attacks get worse: - Because you decided to start a conversation about someone else’s personal shit. You started this war. - War. THIS. IS. WAR. - This is a bunch of nerds attacking someone for reasoned, calm, polite criticism of their friend/idol. Samantha is politely pushing back a bit: - That doesn’t explain why every other part of my article is being pushed aside. - She’s right. This is all nonsense. This is people ignoring her article completely, just looking for things to attack so it can be dismissed. It’s tribalism at its purest. - Then some of the other annointed get into it, including Jason Snell in one of the most spectactular displays of “I have special knowledge you can’t be expected to have, therefore you are totally off base and wrong, even though there’s no way for you to know this” I’ve seen in a while. Jason: - You should never use an ad rate card to estimate ad revenue from any media product ever. - I learned this when I started working for a magazine — rate cards are mostly fiction, like prices on new cars - How…exactly…in the name of whatever deity Jason may believe in…is Samantha or anyone not “in the biz” supposed to know this. Also, what exactly does a magazine on paper like Macworld have to do with sponsorships for a podcast? I have done podcasts that were sponsored, and I can retaliate with “we charged what the rate card said we did. Checkmate Elitests!” - Samantha basically abases herself at his feet: - I understand my mistake, and it’s unfortunate that it has completely diluted the point of my article. - I think she should have told him where and how to stuff that nonsense, but she’s a nicer person than I am. Also, it’s appropriate that Jason’s twitter avatar has its nose in the air. This is some rank snobbery. It’s disgusting and if anyone pulled that on him, Jason would be very upset. But hey, one cannot criticize The Marco without getting pushback. By “pushback”, I mean “an unrelenting fecal flood”. - Her only mistake was criticizing one of the Kool Kids. Folks, if you criticize anyone in The Deck Clique, or their friends, expect the same thing, regardless of tone or point. - Another App Dev, seemingly unable to parse Samantha’s words, needs more explanation: - so just looking over your mentions, I’m curious what exactly was your main point? Ignoring the podcast income bits. - Oh wait, he didn’t even read the article. Good on you, Dev Guy, good. on. you. Still, she plays nice with someone who didn’t even read her article: - That a typical unknown developer can’t depend on patronage to generate revenue, and charging for apps will become a negative. - Marco comes back of course, and now basically accuses her of lying about other devs talking to her and supporting her point: - How many actual developers did you hear from, really? Funny how almost nobody wants to give a (real) name on these accusations. - Really? You’re going to do that? “There’s no name, so I don’t think it’s a real person.” Just…what’s the Joe Welch quote from the McCarthy hearings? - Let us not assassinate this lad further, Senator. You’ve done enough. Have you no sense of decency, sir? At long last, have you left no sense of decency? - That is what this is at this point: character assasination because she said something critical of A Popular Person. It’s disgusting. Depressing and disgusting. No one, none of these people have seriously discussed her point, heck, it looks like they barely bothered to read it, if they did at all. - Marco starts getting really petty with her (no big shock) and Samantha finally starts pushing back: - Glad to see you be the bigger person and ignore the mindset of so many developers not relating to you, good for you! - That of course, is what caused Marco to question the validity, if not the existence of her sources. (Funny how anonymous sources are totes okay when they convenience Marco et al, and work for oh, Apple, but when they are inconvenient? Ha! PROVIDE ME PROOF YOU INTEMPERATE WOMAN!) - Make no mistake, there’s some sexist shit going on here. Every tweet I’ve quoted was authored by a guy. - Of course, Marco has to play the “I’ve been around longer than you” card with this bon mot: - Yup, before you existed! - Really dude? I mean, I’m sorry about the penis, but really? - Mind you, when the criticism isn’t just bizarrely stupid, Samantha reacts the way Marco and his ilk claim they would to (if they ever got any valid criticism. Which clearly is impossible): - Not to get into the middle of this, but “income” is not the term you’re looking for. “Revenue” is. - lol. Noted. - And I wasn’t intending to be a dick, just a lot of people hear/say “income” when they intend “revenue”, and then discussion … - … gets derailed by a jedi handwave of “Expenses”. But outside of charitable donation, it is all directly related. - haha. Thank you for the clarification. - Note to Marco and the other…whatever they are…that is how one reacts to that kind of criticism. With a bit of humor and self-deprecation. You should try it sometime. For real, not just in your heads or conversations in Irish Pubs in S.F. - But now, the door has been cracked, and the cheap shots come out: - @testflight_app: Don’t worry guys, we process @marcoarment’s apps in direct proportion to his megabucks earnings. #fairelephant - (Note: testflight_app is a parody account. Please do not mess with the actual testflight folks. They are still cool.) - Or this…conversation: - - - - <img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1600/1*kbPh7V97eyRodSOw2-ALDw.png"> - - - Good job guys. Good job. Defend the tribe. Attack the other. Frederico attempts to recover from his stunning display of demeaning douchery: @viticci: @s_bielefeld I don’t know if it’s an Italian thing, but counting other people’s money is especially weird for me. IMO, bad move in the post. - Samantha is clearly sick of his crap: @s_bielefeld: @viticci That’s what I’m referring to, the mistake of ever having mentioned it. So, now, Marco can ignore the bigger issue and go on living. - Good for her. There’s being patient and being roadkill. - Samantha does put the call out for her sources to maybe let her use their names: - From all of you I heard from earlier, anyone care to go on record? - My good friend, The Angry Drunk points out the obvious problem: - Nobody’s going to go on record when they count on Marco’s friends for their PR. - This is true. Again, the sites that are Friends of Marco: - Daring Fireball - The Loop - SixColors - iMore - MacStories - A few others, but I want this post to end one day. - You piss that crew off, and given how petty rather a few of them have demonstrated they are, good luck on getting any kind of notice from them. - Of course, the idea this could happen is just craycray: - @KevinColeman .@Angry_Drunk @s_bielefeld @marcoarment Wow, you guys are veering right into crazy conspiracy theory territory. #JetFuelCantMeltSteelBeams - Yeah. Because a mature person like Marco would never do anything like that. - Of course, the real point on this is starting to happen: - you’re getting a lot of heat now but happy you are writing things that stir up the community. Hope you continue to be a voice! - I doubt I will. - See, they’ve done their job. Mess with the bull, you get the horns. Maybe you should find another thing to write about, this isn’t a good place for you. Great job y’all. - Some people aren’t even pretending. They’re just in full strawman mode: - @timkeller: Unfair to begrudge a person for leveraging past success, especially when that success is earned. No ‘luck’ involved. - @s_bielefeld: @timkeller I plainly stated that I don’t hold his doing this against him. Way to twist words. - I think she’s earned her anger at this point. - Don’t worry, Marco knows what the real problem is: most devs just suck — - - - - <img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1600/1*Fpb2Bvdx7Q-688vdm-NdkQ.png"> - - - I have a saying that applies in this case: don’t place your head so far up your nethers that you go full Klein Bottle. Marco has gone full Klein Bottle. (To be correct, he went FKB some years ago.) - There are some bright spots. My favorite is when Building Twenty points out the real elephant in the room: - @BuildingTwenty: Both @s_bielefeld & I wrote similar critiques of @marcoarment’s pricing model yet the Internet pilloried only the woman. Who’d have guessed? - Yup. - Another bright spot are these comments from Ian Betteridge, who has been doing this even longer than Marco: - You know, any writer who has never made a single factual error in a piece hasn’t ever written anything worth reading. - I learned my job with the support of people who helped me. Had I suffered an Internet pile on for every error I wouldn’t have bothered. - To which Samantha understandably replies: - and it’s honestly something I’m contemplating right now, whether to continue… - Gee, I can’t imagine why. Why with comments like this from Chris Breen that completely misrepresent Samantha’s point, (who until today, I would have absolutely defended as being better than this, something I am genuinely saddened to be wrong about), why wouldn’t she want to continue doing this? - If I have this right, some people are outraged that a creator has decided to give away his work. - No Chris, you don’t have this right. But hey, who has time to find out the real issue and read an article. I’m sure your friends told you everything you need to know. - Noted Feminist Glenn Fleishman gets a piece of the action too: - - - - <img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1600/1*lvOySry5gHHJfGU_bQXrzA.png"> - - - I’m not actually surprised here. I watched Fleishman berate a friend of mine who has been an engineer for…heck, waaaaay too long on major software products in the most condescending way because she tried to point out that as a very technical woman, “The Magazine” literally had nothing to say to her and maybe he should fix that. “Impertinent” was I believe what he called her, but I may have the specific word wrong. Not the attitude mind you. Great Feminists like Glenn do not like uppity women criticizing Great Feminists who are their Great Allies. - Great Feminists are often tools. - - - - - - - - - - Luckily, I hope, the people who get Samantha’s point also started chiming in (and you get 100% of the women commenting here that I’ve seen): - I don’t think he’s wrong for doing it, he just discusses it as if the market’s a level playing field — it isn’t - This is a great article with lots of great points about the sustainability of iOS development. Thank you for publishing it. - Regardless of the numbers and your view of MA, fair points here about confirmation bias in app marketing feasibility http://samanthabielefeld.com/the-elephant-in-the-room … - thank you for posting this, it covers a lot of things people don’t like to talk about. - I’m sure you have caught untold amounts of flak over posting this because Marco is blind to his privilege as a developer. - Catching up on the debate, and agreeing with Harry’s remark. (Enjoyed your article, Samantha, and ‘got’ your point.) - - - - - - - - - - I would like to say I’m surprised at the reaction to Samantha’s article, but I’m not. In spite of his loud declarations of support for The Big Lie, Marco Arment is as bad at any form of criticism that he hasn’t already approved as a very insecure tween. An example from 2011: http://www.businessinsider.com/marco-arment-2011-9 - Marco is great with criticism as long as it never actually criticizes him. If it does, be prepared a flood of petty, petulant whining that a room full of bored preschoolers on a hot day would be hard-pressed to match. - Today has been…well, it sucks. It sucks because someone doing what all the Arments of the world claim to want was naive enough to believe what they were told, and found out the hard way just how big a lie The Big Lie is, and how vicious people are when you’re silly enough to believe anything they say about criticism. - And note again, every single condescending crack, misrepresentation, and strawman had an exclusively male source. Most of them have, at one point or another, loudly trumpted themselves as Feminist Allies, as a friend to women struggling with the sexism and misogyny in tech. Congratulations y’all on being just as bad as the people you claim to oppose. - Samantha has handled this better than anyone else could have. My respect for her as a person and a writer is off the charts. If she choses to walk away from blogging in the Apple space, believe me I understand. As bad as today was for her, I’ve seen worse. Much worse. - But I hope she doesn’t. I hope she stays, because she is Doing This Right, and in a corner of the internet that has become naught but an endless circle jerk, a cliquish collection, a churlish, childish cohort interested not in writing or the truth, but in making sure The Right People are elevated, and The Others put down, she is someone worth reading and listening to. The number people who owe her apologies goes around the block, and I don’t think she’ll ever see a one. I’m sure as heck not apologizing for them, I’ll not make their lives easier in the least. - All of you, all. of. you…Marco, Breen, Snell, Vittici, had a chance to live by your words. You were faced with reasoned, polite, respectful criticism and instead of what you should have done, you all dropped trou and sprayed an epic diarrheal discharge all over someone who had done nothing to deserve it. Me, I earned most of my aggro, Samantha did not earn any of the idiocy I’ve seen today. I hope you’re all proud of yourselves. Someone should be, it won’t be me. Ever. - So I hope she stays, but if she goes, I understand. For what it’s worth, I don’t think she’s wrong either way. - - - - - -
- - © Provided by Business Insider Inc Nintendo/Apple Nintendo and Apple shocked the world earlier this year by announcing "Super Mario Run," the legendary gaming company's first foray into mobile gaming. It's a Mario game you can play on your phone with just one hand, so what's not to love? - Thankfully, now we know when you can get it and for how much: "Super Mario Run" will launch on iPhone and iPad on December 15, for a flat fee of $9.99. You can play a sample of the game modes for free, but unlike most other mobile games that let you download for free but require money to keep playing, or access parts of the game, you can pay $10 to get everything right away. - In case you haven't heard, "Super Mario Run" is essentially a regular, side-scrolling "Super Mario" game with one key difference: You don't control Mario's movement. He runs automatically and all you do is tap the screen to jump. - The name and basic idea might sound like one of those endless score attack games like "Temple Run," but that's not the case. "Super Mario Run" is divided into hand-crafted levels with a clear end-point like any other Mario game, meaning you're essentially getting the Mario experience for $10 without needing to control his movement. - $10 might seem like a bit much compared to the $0 people pay for most mobile games, but it's possible the game has $10 worth of levels to play in it. It's also not iPhone exclusive, but the Android version will launch at a later, currently unknown date. - To see "Super Mario Run" in action, check out the footage below: - - -
- - © Provided by Business Insider Inc Nintendo/Apple Nintendo and Apple shocked the world earlier this year by announcing "Super Mario Run," the legendary gaming company's first foray into mobile gaming. It's a Mario game you can play on your phone with just one hand, so what's not to love? - Thankfully, now we know when you can get it and for how much: "Super Mario Run" will launch on iPhone and iPad on December 15, for a flat fee of $9.99. You can play a sample of the game modes for free, but unlike most other mobile games that let you download for free but require money to keep playing, or access parts of the game, you can pay $10 to get everything right away. - In case you haven't heard, "Super Mario Run" is essentially a regular, side-scrolling "Super Mario" game with one key difference: You don't control Mario's movement. He runs automatically and all you do is tap the screen to jump. - The name and basic idea might sound like one of those endless score attack games like "Temple Run," but that's not the case. "Super Mario Run" is divided into hand-crafted levels with a clear end-point like any other Mario game, meaning you're essentially getting the Mario experience for $10 without needing to control his movement. - $10 might seem like a bit much compared to the $0 people pay for most mobile games, but it's possible the game has $10 worth of levels to play in it. It's also not iPhone exclusive, but the Android version will launch at a later, currently unknown date. - To see "Super Mario Run" in action, check out the footage below: - - -
- - - - - - - - © Provided by Business Insider Inc - Nintendo/Apple - - - Nintendo and Apple shocked the world earlier this year by announcing "Super Mario Run," the legendary gaming company's first foray into mobile gaming. It's a Mario game you can play on your phone with just one hand, so what's not to love? - Thankfully, now we know when you can get it and for how much: "Super Mario Run" will launch on iPhone and iPad on December 15, for a flat fee of $9.99. You can play a sample of the game modes for free, but unlike most other mobile games that let you download for free but require money to keep playing, or access parts of the game, you can pay $10 to get everything right away. - In case you haven't heard, "Super Mario Run" is essentially a regular, side-scrolling "Super Mario" game with one key difference: You don't control Mario's movement. He runs automatically and all you do is tap the screen to jump. - The name and basic idea might sound like one of those endless score attack games like "Temple Run," but that's not the case. "Super Mario Run" is divided into hand-crafted levels with a clear end-point like any other Mario game, meaning you're essentially getting the Mario experience for $10 without needing to control his movement. - $10 might seem like a bit much compared to the $0 people pay for most mobile games, but it's possible the game has $10 worth of levels to play in it. It's also not iPhone exclusive, but the Android version will launch at a later, currently unknown date. - To see "Super Mario Run" in action, check out the footage below: - - - -
- Lorem - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tab here incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Foo - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem - ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tab here - incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation - - - - - ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- - - - - - - - - - - - South Korea’s Blacklist of Artists Adds to Outrage Over Presidential Scandal -
- - - - - - - - Supported by - - - - - - Africa - United States to Lift Sudan Sanctions - - - - - - - - - - - - - Photo - - - - - - - - - - United Nations peacekeepers at a refugee camp in Sudan on Monday. In exchange for the lifting of United States trade sanctions, Sudan has said it will improve access for aid groups, stop supporting rebels in neighboring South Sudan and cooperate with American intelligence agents. - - Credit Ashraf Shazly/Agence France-Presse — Getty Images - - - LONDON — After nearly 20 years of hostile relations, the American government plans to reverse its position on Sudan and lift trade sanctions, Obama administration officials said late Thursday. - Sudan is one of the poorest, most isolated and most violent countries in Africa, and for years the United States has imposed punitive measures against it in a largely unsuccessful attempt to get the Sudanese government to stop killing its own people. - On Friday, the Obama administration will announce a new Sudan strategy. For the first time since the 1990s, the nation will be able to trade extensively with the United States, allowing it to buy goods like tractors and spare parts and attract much-needed investment in its collapsing economy. - In return, Sudan will improve access for aid groups, stop supporting rebels in neighboring South Sudan, cease the bombing of insurgent territory and cooperate with American intelligence agents. - American officials said Sudan had already shown important progress on a number of these fronts. But to make sure the progress continues, the executive order that President Obama plans to sign on Friday, days before leaving office, will have a six-month review period. If Sudan fails to live up to its commitments, the embargo can be reinstated. - - - Advertisement - - Continue reading the main story - - Analysts said good relations with Sudan could strengthen moderate voices within the country and give the Sudanese government incentives to refrain from the brutal tactics that have defined it for decades. - In 1997, President Bill Clinton imposed a comprehensive trade embargo against Sudan and blocked the assets of the Sudanese government, which was suspected of sponsoring international terrorism. In the mid-1990s, Osama bin Laden lived in Khartoum, the capital, as a guest of Sudan’s government. - In 1998, Bin Laden’s agents blew up the United States Embassies in Kenya and Tanzania, killing more than 200 people. In retaliation, Mr. Clinton ordered a cruise missile strike against a pharmaceutical factory in Khartoum. - Since then, American-Sudanese relations have steadily soured. The conflict in Darfur, a vast desert region of western Sudan, was a low point. After rebels in Darfur staged an uprising in 2003, Sudanese security services and their militia allies slaughtered tens of thousands of civilians, leading to condemnation around the world, genocide charges at the International Criminal Court against Sudan’s president, Omar Hassan al-Bashir, and a new round of American sanctions. - American officials said Thursday that the American demand that Mr. Bashir be held accountable had not changed. Neither has Sudan’s status as one of the few countries, along with Iran and Syria, that remain on the American government’s list of state sponsors of terrorism. - Sales of military equipment will still be prohibited, and some Sudanese militia and rebel leaders will still face sanctions. - But the Obama administration is clearly trying to open a door to Sudan. There is intense discontent across the country, and its economy is imploding. American officials have argued for years that it was time to help Sudan dig itself out of the hole it had created. - Officials divulged Thursday that the Sudanese government had allowed two visits by American operatives to a restricted border area near Libya, which they cited as evidence of a new spirit of cooperation on counterterrorism efforts. - - - Advertisement - - Continue reading the main story - - In addition to continuing violence in Darfur, several other serious conflicts are raging in southern and central Sudan, along with a civil war in newly independent South Sudan, which Sudan has been suspected of inflaming with covert arms shipments. - Eric Reeves, one of the leading American academic voices on Sudan, said he was “appalled” that the American government was lifting sanctions. - He said that Sudan’s military-dominated government continued to commit grave human rights abuses and atrocities, and he noted that just last week Sudanese security services killed more than 10 civilians in Darfur. - “There is no reason to believe the guys in charge have changed their stripes,” said Mr. Reeves, a senior fellow at the François-Xavier Bagnoud Center for Health and Human Rights at Harvard University. “These guys are the worst of the worst.” - Obama administration officials said that they had briefed President-elect Donald J. Trump’s transition team, but that they did not know if Mr. Trump would stick with a policy of warmer relations with Sudan. - They said that Sudan had a long way to go in terms of respecting human rights, but that better relations could help increase American leverage. - Mr. Reeves said he thought that the American government was being manipulated and that the Obama administration had made a “deal with the devil.” - - Continue reading the main story - - - - - - - - - - - - - - - - - - - - - - - We’re interested in your feedback on this page. Tell us what you think. - - - - - - - - - - - - -
- - - - - - - - - - - - Justice Department Toughened Approach on Corporate Crime, but Will That Last? -
- - - - - - - - - - - - - Economic View - Making America Great Again Isn’t Just About Money and Power -
- - - - - - - - - - - - - Common Sense - Goldman Sachs Completes Return From Wilderness to the White House -
- - - - - - - - - - - - Morning Agenda: The Transition, Cabinet Nominees and ‘Star Wars’ vs. ‘Star Trek’ -
- - - - - - - - - - - - - DealBook - Critics Say Trump Appointees Can Dodge a Huge Tax Bill. That’s Not... -
- - - - - - - - - - - - - White Collar Watch - Under New Chairman, S.E.C. Enforcer Role Might Shrink -
- - - - - - - - - - - - - Bottom Line Nation | Part 5 - In American Towns, Private Profits From Public Works -
- - - - - - - - - - - - - - - - - - Supported by - - - - - - - Yahoo’s Sale to Verizon Leaves Shareholders With Little Say - - - - - - - - - - - - - Photo - - - - - - - - - - - Credit Harry Campbell - - - Yahoo’s $4.8 billion sale to Verizon is a complicated beast, showing how different acquisition structures can affect how shareholders are treated. - First, let’s say what the Yahoo sale is not. It is not a sale of the publicly traded company. Instead, it is a sale of the Yahoo subsidiary and some related assets to Verizon. - The sale is being done in two steps. The first step will be the transfer of any assets related to Yahoo business to a singular subsidiary. This includes the stock in the business subsidiaries that make up Yahoo that are not already in the single subsidiary, as well as the odd assets like benefit plan rights. This is what is being sold to Verizon. A license of Yahoo’s oldest patents is being held back in the so-called Excalibur portfolio. This will stay with Yahoo, as will Yahoo’s stakes in Alibaba Group and Yahoo Japan. - It is hard to overestimate how complex an asset sale like this is. Some of the assets are self-contained, but they must be gathered up and transferred. Employees need to be shuffled around and compensation arrangements redone. Many contracts, like the now-infamous one struck with the search engine Mozilla, which may result in a payment of up to a $1 billion, will contain change-of-control provisions that will be set off and have to be addressed. Tax issues always loom large. Continue reading the main story - - - - - - - - - - - - - - Advertisement - - Continue reading the main story - - - - - - In the second step, at the closing, Yahoo will sell the stock in the single subsidiary to Verizon. At that point, Yahoo will change its name to something without “Yahoo” in it. My favorite is simply Remain Co., the name Yahoo executives are using. Remain Co. will become a holding company for the Alibaba and Yahoo Japan stock. Included will also be $10 billion in cash, plus the Excalibur patent portfolio and a number of minority investments including Snapchat. Ahh, if only Yahoo had bought Snapchat instead of Tumblr (indeed, if only Yahoo had bought Google or Facebook when it had the chance). - - - Advertisement - - Continue reading the main story - - Because it is a sale of a subsidiary, the $4.8 billion will be paid to Yahoo. Its shareholders will not receive any money unless Yahoo pays it out in a dividend (after paying taxes). Instead, Yahoo shareholders will be left holding shares in the renamed company. - Verizon’s Yahoo will then be run under the same umbrella as AOL. It is unclear whether there will be a further merger of the two businesses after the acquisition. Plans for Yahoo are still a bit in flux in part because of the abnormal sale process. - As for Remain Co., it will become a so-called investment company. This is a special designation for a company that holds securities for investment but does not operate a working business. Investment companies are subject to special regulation under the Investment Company Act of 1940. Remain Co. will probably just sit there, returning cash to shareholders and waiting for Alibaba to buy it in a tax-free transaction. (Alibaba says it has no plans to do this, but most people do not believe this). - The rights of Yahoo shareholders in this sale will be different from those in an ordinary sale, when an entire company is bought. - Ordinary sales are done in one of two ways: in a merger where the target is merged into a subsidiary of the buyer and the target shareholders receive the cash (or other consideration), or in a tender offer that gives the target shareholders a choice to tender into the offer or not. Then there will be a merger where the target is merged into the buyer’s subsidiary and the target shareholders are forcibly squeezed out, receiving the merger consideration. (if you want to know why you would choose one structure over another, I wrote a good primer in 2009.) - In either case, shareholders get a say. They either vote on the merger or decide whether to tender into the offer. - In both cases, there would be appraisal rights if the buyer pays cash. This means that shareholders can object to the deal by not voting for it or not tendering into the offer and instead asking a court to value their shares – this is what happened in Dell’s buyout in 2013. - The Yahoo deal, however, is not a sale of the public company. It is an asset sale, in which there is only a shareholder vote if there is a sale of “all” or “substantially all” of the assets of the company. Yahoo is not all of the assets or even “substantially all” – the Alibaba shares being left behind in Remain Co. are worth about $28 billion, or six times the value of the cash Verizon is paying for the Yahoo assets it is buying. - - - Advertisement - - Continue reading the main story - - The courts have held that the definition of “substantially all” includes a change of business in a company because of an asset sale where the assets are “qualitatively vital.” And that certainly applies here. So there will be a vote – indeed, Yahoo has no problem with a vote – and shareholders are desperate to sell at this point. - There will be no appraisal rights, however. Again, in an asset sale, there are no appraisal rights. So anyone who votes against the deal and thinks this is a bum price is out of luck. - The different standards for voting and appraisal rights apply because the structure of the deal is a quirk of the law in Delaware, where Yahoo is incorporated, that allows lawyers to sometimes work around these issues simply by changing the way a deal is done. - In Yahoo’s case, this is not deliberate, though. It is simply the most expedient way to get rid of the assets. - Whether this is the most tax-efficient way is unclear to me as a nontax lawyer (email me if you know). Yahoo is likely to have a tax bill on the sale, possibly a substantial one. And I presume there were legal reasons for not using a Morris Trust structure, in which Yahoo would have been spun off and immediately sold to Verizon so that only Yahoo’s shareholders paid tax on the deal. In truth, the Yahoo assets being sold are only about 10 percent of the value of the company, so the time and logistics for such a sale when Yahoo is a melting ice cube may not have been worth it. - Finally, if another bidder still wants to acquire Yahoo, it has time. The agreement with Verizon allows Yahoo to terminate the deal and accept a superior offer by paying a $144 million breakup fee to Verizon. And if Yahoo shareholders change their minds and want to stick with Yahoo’s chief executive, Marissa Mayer, and vote down the deal, there is a so-called naked no-vote termination fee of $15 million payable to Verizon to reimburse expenses. - All in all, this was as hairy a deal as they come. There was the procedural and logistical complications of selling a company when the chief executive wanted to stay. Then there was the fact that this was an asset sale, including all of the challenges that go with it. Throw in all of the tax issues and the fact that this is a public company, and it is likely that the lawyers involved will have nightmares for years to come. Continue reading the main story - - - - - - - - - - - - - - - - - - - - We’re interested in your feedback on this page. Tell us what you think. - - - - - - - - - - - - - - - -
- - - - Marissa Mayer’s Media Problem at Yahoo Is Now Verizon’s to Solve - JULY 26, 2016 - - - - - - - - -
- - - - Verizon Announces $4.8 Billion Deal for Yahoo’s Internet Business - JULY 25, 2016 - - - - - - - - -
- Lorem - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. - Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. - - Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - - - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - - - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - - - -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. - Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. - - Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. - - Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - - Lorem ipsumdolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Foo - - Temporincididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Foo - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - Lorem ipsum dolor sit amet. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet. - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - Lorem ipsum dolor sit amet. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet. - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - Lorem ipsum dolor sit amet. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet. - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem - Lorem ipsum dolor sit amet. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - Lorem ipsum dolor sit amet. - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- Lorem ipsum dolor - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem ipsum dolor - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - Like this: - - - Like - - Loading... - - - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Foo - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- Lorem - - - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Foo - - Tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- - - - Zimbabwe President Robert Mugabe, his wife Grace and two key figures from her G40 political faction are under house arrest at Mugabe's "Blue House" compound in Harare and are insisting the 93 year-old finishes his presidential term, a source said. - The G40 figures are cabinet ministers Jonathan Moyo and Saviour Kasukuwere, who fled to the compound after their homes were attacked by troops in Tuesday night's coup, the source, who said he had spoken to people inside the compound, told Reuters. - Mr Mugabe is resisting mediation by a Catholic priest to allow the former guerrilla a graceful exit after the military takeover. - The priest, Fidelis Mukonori, is acting as a middle-man between Mr Mugabe and the generals, who seized power in a targeted operation against "criminals" in his entourage, a senior political source told Reuters. - The source could not provide details of the talks, which appear to be aimed at a smooth and bloodless transition after the departure of Mr Mugabe, who has led Zimbabwe since independence in 1980. - Mr Mugabe, still seen by many Africans as a liberation hero, is reviled in the West as a despot whose disastrous handling of the economy and willingness to resort to violence to maintain power destroyed one of Africa's most promising states. - - - - - - - - - - - - - - Zimbabwean opposition leader Morgan Tsvangirai, right, meets church leaders Bishop Trevor Manhanga, centre, and Father Fidelis Mukonori in 2006. Father Mukonori is said to be mediating in the current crisis -Credit: DESMOND KWANDE/ AFP - - - - - - - - - Zimbabwean intelligence reports seen by Reuters suggest that former security chief Emmerson Mnangagwa, who was ousted as vice-president this month, has been mapping out a post-Mugabe vision with the military and opposition for more than a year. - - - - - - - - - - Fuelling speculation that Mnangagwa's plan might be rolling into action, opposition leader Morgan Tsvangirai, who has been receiving cancer treatment in Britain and South Africa, returned to Harare late on Wednesday, his spokesman said. - South Africa said Mr Mugabe had told President Jacob Zuma by telephone on Wednesday that he was confined to his home but was otherwise fine and the military said it was keeping him and his family, including wife Grace, safe. - - - - - - - - - - - - - - - Despite the lingering admiration for Mr Mugabe, there is little public affection for 52-year-old Grace, a former government typist who started having an affair with Mr Mugabe in the early 1990s as his first wife, Sally, was dying of kidney disease. - Dubbed "DisGrace" or "Gucci Grace" on account of her reputed love of shopping, she enjoyed a meteoric rise through the ranks of Mugabe's ruling Zanu-PF in the last two years, culminating in Mnangagwa's removal a week ago - a move seen as clearing the way for her to succeed her husband. - - - - - - - - - - - - - - A man walks past an armoured personnel carrier parked on a Harare street on Thursday -Credit: STR/AFP - - - - - - - - - In contrast to the high political drama unfolding behind closed doors, the streets of the capital remained calm, with people going about their daily business, albeit under the watch of soldiers on armoured vehicles at strategic locations. - - - - - - - - - - Whatever the final outcome, the events could signal a once-in-a-generation change for the former British colony, a regional breadbasket reduced to destitution by economic policies Mr Mugabe's critics have long blamed on him. - - - -
- This is a long title with a colon: But the final text here is different - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. -
- This is a long title with a colon: But the final text here is different - - Lorem - ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - - - Lorem - ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod - incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, - quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo - consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse - cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non - proident, sunt in culpa qui officia deserunt mollit anim id est laborum. - -
- - - Lupita Nyong'o - - $150K Pearl Oscar Dress ... STOLEN!!!! - - - - 2/26/2015 7:11 AM PST BY TMZ STAFF - - - - EXCLUSIVE - - - Lupita Nyong'o's now-famous Oscar dress - -- adorned in pearls -- was stolen right out of her hotel room ... TMZ - has learned. - Law enforcement sources tell TMZ ... the dress was taken out of Lupita's - room at The London West Hollywood. The dress is made of pearls ... 6,000 - white Akoya pearls. It's valued at $150,000. - Our sources say Lupita told cops it was taken from her room sometime between - 8 AM and 9 PM Wednesday ... while she was gone. - We're told there is security footage that cops are looking at that could - catch the culprit right in the act. - - 12:00 PM PT -- Sheriff's deputies were at The London Thursday - morning. We know they were in the manager's office and we're told - they have looked at security footage to determine if they can ID the culprit. - - - - - - -See also - - - French Laundry -- $300,000 Worth of Wine Stolen From Restaurant You WIll Never Get Into - - Miley Cyrus -- Burglary Victim ... AGAIN - - Stolen Beverly Hills Dog -- Hilary Duff & Celeb Posse Scour City - - - - - - - - - - - - - - Get TMZ Breaking News alerts to your inbox - - - - - - - - Yes! Also send me - "In Case You Missed It..." - - By clicking "Submit," you agree to the Privacy Policy and Terms of Use. > - - - - - - - - - - -
- CAIRO — Gunmen opened fire on visitors at Tunisia’s most renowned museum on Wednesday, killing at least 19 people, including 17 foreigners, in an assault that threatened to upset the fragile stability of a country seen as the lone success of the Arab Spring. - It was the most deadly terrorist attack in the North African nation in more than a decade. Although no group claimed responsibility, the bloodshed raised fears that militants linked to the Islamic State were expanding their operations. - The attackers, clad in military uniforms, stormed the Bardo National Museum on Wednesday afternoon, seizing and gunning down foreign tourists before security forces raided the building to end the siege. The museum is a major tourist draw and is near the heavily guarded national parliament in downtown Tunis. - Tunisian Prime Minister Habib Essid said that in addition to the slain foreigners — from Italy, Poland, Germany and Spain — a local museum worker and a security official were killed. Two gunmen died, and three others may have escaped, officials said. About 50 other people were wounded, according to local news reports. - “Our nation is in danger,” Essid declared in a televised address Wednesday evening. He vowed that the country would be “merciless” in defending itself. - [Read: Why Tunisia, Arab Spring’s sole success story, suffers from Islamist violence] - Tunisia, a mostly Muslim nation of about 11 million people, was governed for decades by autocrats who imposed secularism. Its sun-drenched Mediterranean beaches drew thousands of bikini-clad tourists, and its governments promoted education and other rights for women. But the country has grappled with rising Islamist militancy since a popular uprising overthrew its dictator four years ago, setting the stage for the Arab Spring revolts across the region. - Thousands of Tunisians have flocked to join jihadist groups in Syria, including the Islamic State, making the country one of the major sources of foreign fighters in the conflict. Tunisian security forces have also fought increasing gunbattles with jihadists at home. - Despite this, the country has been hailed as a model of democratic transition as other governments that came to power after the Arab Spring collapsed, often in bloody confrontations. But the attack Wednesday — on a national landmark that showcases Tunisia’s rich heritage — could heighten tensions in a nation that has become deeply divided between pro- and anti-Islamist political factions. - Many Tunisians accuse the country’s political Islamists, who held power from 2011 to 2013, of having been slow to respond to the growing danger of terrorism. Islamist politicians have acknowledged that they did not realize the threat that would develop when radical Muslims, who had been repressed under authoritarian regimes, won the freedom to preach freely in mosques. - In Washington, White House press secretary Josh Earnest condemned the attack and said the U.S. government was willing to assist Tunisian authorities in the investigation. - - Gunmen in military uniforms stormed Tunisia's national museum, killing at least 19 people, most of them foreign tourists. (Reuters) - - “This attack today is meant to threaten authorities, to frighten tourists and to negatively affect the economy,” said Lotfi Azzouz, Tunisia country director for Amnesty International, a London-based rights group. - Tourism is critical to Tunisia’s economy, accounting for 15 percent of its gross domestic product in 2013, according to the World Travel and Tourism Council, an industry body. The Bardo museum hosts one of the world’s most outstanding collections of Roman mosaics and is popular with tourists and Tunisians alike. - [Bardo museum houses amazing Roman treasures] - The attack is “also aimed at the country’s security and stability during the transition period,” Azzouz said. “And it could have political repercussions — like the curtailing of human rights, or even less government transparency if there’s fear of further attacks.” - The attack raised concerns that the government, led by secularists, would be pressured to stage a wider crackdown on Islamists of all stripes. Lawmakers are drafting an anti-terrorism bill to give security forces additional tools to fight militants. - [Read: Tunisia sends most foreign fighters to Islamic State in Syria] - “We must pay attention to what is written” in that law, Azzouz said. “There is worry the government will use the attack to justify some draconian measures.” - Tunisian Islamists and secular forces have worked together — often reluctantly — to defuse the country’s political crises in the years since the revolt. - Last fall, Tunisians elected a secular-minded president and parliament dominated by liberal forces after souring on Islamist-led rule. In 2011, voters had elected a government led by the Ennahda party — a movement similar to Egypt’s Islamist Muslim Brotherhood. But a political stalemate developed as the party and others tried to draft the country’s new constitution. The Islamists failed to improve a slumping economy. And Ennahda came under fire for what many Tunisians saw as a failure to crack down on Islamist extremists. - - Map: Flow of foreign fighters to Syria - - After the collapse of the authoritarian system in 2011, hard-line Muslims known as Salafists attacked bars and art galleries. Then, in 2012, hundreds of Islamists assaulted the U.S. Embassy in Tunis, shattering windows and hurling gasoline bombs, after the release of a crude online video about the prophet Muhammad. The government outlawed the group behind the attack — Ansar al-Sharia, an al-Qaeda-linked organization — and began a crackdown. But the killing of two leftist politicians in 2013 prompted a fresh political crisis, and Ennahda stepped down, replaced by a technocratic government. - Tunisia’s current coalition government includes an Ennahda minister in the cabinet. Still, many leftist figures openly oppose collaboration with the movement’s leaders. - “Ennahda is responsible for the current deterioration of the situation, because they were careless with the extremists” while they were in power, Azzouz said. - The leader of Ennahda, Rachid Ghannouchi, condemned Wednesday’s attack, saying in a statement that it “will not break our people’s will and will not undermine our revolution and our democracy.” - Security officials are particularly concerned by the collapse of Libya, where various armed groups are vying for influence and jihadist militants have entrenched themselves in major cities. Tunisians worry that extremists can easily get arms and training in the neighboring country. - In January, Libyan militants loyal to the Islamic State beheaded 21 Christians — 20 of them Egyptian Copts — along the country’s coast. They later seized the Libyan city of Sirte. - - - - - Officials are worried about the number of Tunisian militants who may have joined the jihadists in Libya — with the goal of returning home to fight the Tunis government. - Ajmi Lourimi, a member of Ennahda’s general secretariat, said he believed the attack would unite Tunisians in the face of terrorism. - “There is a consensus here that this [attack] is alien to our culture, to our way of life. We want to unify against this danger,” Lourimi said. He said he did not expect a wider government campaign against Islamists. - “We have nothing to fear,” he said of himself and fellow Ennahda members. “We believe the Interior Ministry should be trained and equipped to fight and counter this militancy.” - The last major attack on a civilian target in Tunisia was in 2002, when al-Qaeda militants killed more than 20 people in a car bombing outside a synagogue in the city of Djerba. - Heba Habib contributed to this report. - Read more: - Tunisia’s Islamists get a sobering lesson in governing - Tunisia sends most foreign fighters to Islamic State in Syria - Tunisia’s Bardo museum is home to amazing Roman treasures -
- - - - - - - - - - 1 of 24 - - - - - - - Full Screen - Autoplay - - Close - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Skip Ad - - - × - - - - - - - - - - - - - - - - - At least 17 dead in Tunisia after attack in capital city - - - - - - - - View Photos - - - Security forces in Tunisia stormed the country’s most prominent museum, freeing hostages and ending a siege by gunmen. - - - - - - Caption - - - Security forces in Tunisia stormed the country’s most prominent museum, - freeing hostages and ending a siege by gunmen. - March 18, 2015 Tunisian security forces secure the area after gunmen attacked the famed Bardo National Museum in Tunis, the capital. - Fethi Belaid/AFP/Getty Images - Buy Photo - - - - - - - - - - Wait 1 second to continue. - - - - - - - CAIRO — Gunmen opened fire on visitors at - Tunisia’s most renowned museum on Wednesday, killing at least 19 people, - including 17 foreigners, in an assault that threatened to upset the fragile - stability of a country seen as the lone success of the Arab Spring. - It was the most deadly terrorist attack in the North African nation in - more than a decade. Although no group claimed responsibility, the bloodshed - raised fears that militants linked to the Islamic State were expanding - their operations. - The attackers, clad in military uniforms, stormed the Bardo National Museum on - Wednesday afternoon, seizing and gunning down foreign tourists before security - forces raided the building to end the siege. The museum is a major tourist - draw and is near the heavily guarded national parliament in downtown Tunis. - Tunisian Prime Minister Habib Essid said that in addition to the slain - foreigners — from Italy, Poland, Germany and Spain — a local museum worker - and a security official were killed. Two gunmen died, and three others - may have escaped, officials said. About 50 other people were wounded, according - to local news reports. - “Our nation is in danger,” Essid declared in a televised address Wednesday - evening. He vowed that the country would be “merciless” in defending itself. - [Read: Why Tunisia, Arab Spring’s sole success story, suffers from Islamist violence] - - Tunisia, a mostly Muslim nation of about 11 million people, was governed - for decades by autocrats who imposed secularism. Its sun-drenched Mediterranean - beaches drew thousands of bikini-clad tourists, and its governments promoted - education and other rights for women. But the country has grappled with - rising Islamist militancy since a popular uprising overthrew its dictator - four years ago, setting the stage for the Arab Spring revolts across the - region. - Thousands of Tunisians have flocked to join jihadist groups in Syria, - including the Islamic State, making the country one of the major sources - of foreign fighters in the conflict. Tunisian security forces have also - fought increasing gunbattles with jihadists at home. - Despite this, the country has been hailed as a model of democratic transition - as other governments that came to power after the Arab Spring collapsed, - often in bloody confrontations. But the attack Wednesday — on a national - landmark that showcases Tunisia’s rich heritage — could heighten tensions - in a nation that has become deeply divided between pro- and anti-Islamist - political factions. - Many Tunisians accuse the country’s political Islamists, who held power - from 2011 to 2013, of having been slow to respond to the growing danger - of terrorism. Islamist politicians have acknowledged that they did not - realize the threat that would develop when radical Muslims, who had been - repressed under authoritarian regimes, won the freedom to preach freely - in mosques. - In Washington, White House press secretary Josh Earnest condemned the attack and - said the U.S. government was willing to assist Tunisian authorities in - the investigation. - - - - - Gunmen in military uniforms stormed Tunisia's national museum, killing at least 19 people, most of them foreign tourists. (Reuters) - - - “This attack today is meant to threaten authorities, to frighten tourists - and to negatively affect the economy,” said Lotfi Azzouz, Tunisia country - director for Amnesty International, a London-based rights group. - Tourism is critical to Tunisia’s economy, accounting for 15 percent of - its gross domestic product in 2013, according to the World Travel and Tourism - Council, an industry body. The Bardo museum hosts one of the world’s most - outstanding collections of Roman mosaics and is popular with tourists and - Tunisians alike. - [Bardo museum houses amazing Roman treasures] - - The attack is “also aimed at the country’s security and stability during - the transition period,” Azzouz said. “And it could have political repercussions - — like the curtailing of human rights, or even less government transparency - if there’s fear of further attacks.” - The attack raised concerns that the government, led by secularists, would - be pressured to stage a wider crackdown on Islamists of all stripes. Lawmakers - are drafting an anti-terrorism bill to give security forces additional - tools to fight militants. - - - - - - - - - - 1 of 12 - - - - - - - Full Screen - Autoplay - - Close - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Skip Ad - - - × - - - - - - - - - - - - - - - - - Inside Tunisia’s Bardo National Museum - - - - - - - - View Photos - - - Housed in a 19th-century palace, the museum where gunmen killed foreign tourists is famous for its Roman mosaics and other antiquities. - - - - - - Caption - - - Housed in a 19th-century palace, the museum where gunmen killed foreign - tourists is famous for its Roman mosaics and other antiquities. - May 17, 2012 One of the many mosaics for which the Bardo National Museum in Tunis is famous. On March 18, 2015, gunmen attacked the museum and killed at least 19 people. - Fethi Belaid/AFP/Getty Images - Buy Photo - - - - - - - - - - Wait 1 second to continue. - - - - - - - [Read: Tunisia sends most foreign fighters to Islamic State in Syria] - - “We must pay attention to what is written” in that law, Azzouz said. “There - is worry the government will use the attack to justify some draconian measures.” - Tunisian Islamists and secular forces have worked together — often reluctantly - — to defuse the country’s political crises in the years since the revolt. - Last fall, Tunisians elected a secular-minded president and parliament - dominated by liberal forces after souring on Islamist-led rule. - In 2011, voters had elected a government led by the Ennahda party — a movement - similar to Egypt’s Islamist Muslim Brotherhood. But a political stalemate - developed as the party and others tried to draft the country’s new constitution. - The Islamists failed to improve a slumping economy. And Ennahda came under - fire for what many Tunisians saw as a failure to crack down on Islamist - extremists. - - - Map: Flow of foreign fighters to Syria - - View Graphic - - - Map: Flow of foreign fighters to Syria - - After the collapse of the authoritarian system in 2011, hard-line Muslims - known as Salafists attacked bars and art galleries. Then, in 2012, hundreds - of Islamists assaulted the U.S. Embassy in - Tunis, shattering windows and hurling gasoline bombs, after the release - of a crude online video about the prophet Muhammad. The - government outlawed the group behind the attack — Ansar al-Sharia, an al-Qaeda-linked - organization — and began a crackdown. But the killing of two leftist politicians in - 2013 prompted a fresh political crisis, and Ennahda stepped down, replaced - by a technocratic government. - Tunisia’s current coalition government includes - an Ennahda minister in the cabinet. Still, many leftist figures openly - oppose collaboration with the movement’s leaders. - “Ennahda is responsible for the current deterioration of the situation, - because they were careless with the extremists” while they were in power, - Azzouz said. - The leader of Ennahda, Rachid Ghannouchi, condemned Wednesday’s attack, - saying in a statement that it “will not break our people’s will and will - not undermine our revolution and our democracy.” - Security officials are particularly concerned by the collapse of Libya, - where various armed groups are vying for influence and jihadist militants - have entrenched themselves in major cities. Tunisians worry that extremists - can easily get arms and training in the neighboring country. - In January, Libyan militants loyal to the Islamic State beheaded 21 Christians — - 20 of them Egyptian Copts — along the country’s coast. They later seized - the Libyan city of Sirte. - - - - - Officials are worried about the number of Tunisian militants who may have - joined the jihadists in Libya — with the goal of returning home to fight - the Tunis government. - Ajmi Lourimi, a member of Ennahda’s general secretariat, said he believed - the attack would unite Tunisians in the face of terrorism. - “There is a consensus here that this [attack] is alien to our culture, - to our way of life. We want to unify against this danger,” Lourimi said. - He said he did not expect a wider government campaign against Islamists. - “We have nothing to fear,” he said of himself and fellow Ennahda members. - “We believe the Interior Ministry should be trained and equipped to fight - and counter this militancy.” - The last major attack on a civilian target in Tunisia was in 2002, when - al-Qaeda militants killed more than 20 people in a car bombing outside - a synagogue in the city of Djerba. - - Heba Habib contributed to this report. - - - - - Read more: - - Tunisia’s Islamists get a sobering lesson in governing - - Tunisia sends most foreign fighters to Islamic State in Syria - - Tunisia’s Bardo museum is home to amazing Roman treasures - - -
- President Obama told the U.N. General Assembly 18 months ago that he would seek “real breakthroughs on these two issues — Iran’s nuclear program and Israeli-Palestinian peace.” - But Benjamin Netanyahu’s triumph in Tuesday’s parliamentary elections keeps in place an Israeli prime minister who has declared his intention to resist Obama on both of these fronts, guaranteeing two more years of difficult diplomacy between leaders who barely conceal their personal distaste for each other. - The Israeli election results also suggest that most voters there support Netanyahu’s tough stance on U.S.-led negotiations to limit Iran’s nuclear program and his vow on Monday that there would be no independent Palestinian state as long as he is prime minister. - “On the way to his election victory, Netanyahu broke a lot of crockery in the relationship,” said Martin Indyk, executive vice president of the Brookings Institution and a former U.S. ambassador to Israel. “It can’t be repaired unless both sides have an interest and desire to do so.” - Aside from Russian President Vladimir Putin, few foreign leaders so brazenly stand up to Obama and even fewer among longtime allies. - - Israeli Prime Minister Benjamin Netanyahu pledged to form a new governing coalition quickly after an upset election victory that was built on a shift to the right. (Reuters) - - In the past, Israeli leaders who risked damaging the country’s most important relationship, that with Washington, tended to pay a price. In 1991, when Prime Minister Yitzhak Shamir opposed the Madrid peace talks, President George H.W. Bush held back loan guarantees to help absorb immigrants from the former Soviet Union. Shamir gave in, but his government soon collapsed. - But this time, Netanyahu was not hurt by his personal and substantive conflicts with the U.S. president. - “While the United States is loved and beloved in Israel, President Obama is not,” said Robert M. Danin, a senior fellow at the Council on Foreign Relations. “So the perceived enmity didn’t hurt the way it did with Shamir when he ran afoul of Bush in ’91.” - Where do U.S.-Israeli relations go from here? - In the immediate aftermath of Tuesday’s elections, tensions between the two sides continued to run hot. The Obama administration’s first comments on the Israeli election came with a tough warning about some of the pre-election rhetoric from Netanyahu’s Likud party, which tried to rally right-wing support by saying that Arab Israeli voters were “coming out in droves.” - “The United States and this administration is deeply concerned about rhetoric that seeks to marginalize Arab Israeli citizens,” White House press secretary Josh Earnest told reporters aboard Air Force One. “It undermines the values and democratic ideals that have been important to our democracy and an important part of what binds the United States and Israel together.” - Earnest added that Netanyahu’s election-eve disavowal of a two-state solution for Israelis and Palestinians would force the administration to reconsider its approach to peace in the region. - Over the longer term, a number of analysts say that Obama and Netanyahu will seek to play down the friction between them and point to areas of continuing cooperation on military and economic issues. - “Both sides are going to want to turn down the rhetoric,” Danin said. “But it is also a structural problem. They have six years of accumulated history. That’s going to put limits on how far they can go together.” - The first substantive test could come as early as this month, when the United States hopes that it can finish hammering out the framework of an agreement with Iran. - Netanyahu strongly warned against making a “bad deal” during his March 3 address to a joint meeting of Congress, an appearance arranged by Republican congressional leaders and criticized by the Obama administration for making U.S.-Israeli relations partisan on both sides so close to the Israeli election. - If a deal is reached and does not pass muster with Netanyahu, he is likely to work with congressional Republicans to try to scuttle the accord. - “The Republicans have said they will do what they can to block a deal, and the prime minister has already made clear that he will work with the Republicans against the president,” Indyk said. “That’s where a clash could come, and it’s coming very quickly.” - The second test — talks with Palestinians — could be even more difficult. In his September 2013 address to the United Nations, Obama hailed signs of hope. - “Already, Israeli and Palestinian leaders have demonstrated a willingness to take significant political risks,” Obama said in his speech. Palestinian Authority President Mahmoud Abbas “has put aside efforts to shortcut the pursuit of peace and come to the negotiating table. Prime Minister Netanyahu has released Palestinian prisoners and reaffirmed his commitment to a Palestinian state.” - Today, the signals could not differ more. The Palestinian Authority has said that after it joins the International Criminal Court at The Hague on April 1, it will press war crimes charges against Israel for the bloody Gaza conflict during the summer. Israel, which controls tax receipts, has pledged to punish the Palestinian Authority by freezing its tax revenue. - The United States, which gives hundreds of millions of dollars of economic aid to the Palestinian Authority, would be caught in the middle. It has been trying to persuade both sides to stand down, but Netanyahu’s declaration that there would be no Palestinian state on his watch makes that more difficult. - “Now it’s hard to see what could persuade the Palestinians” to hold up on their ICC plans, Indyk said. “That has nothing to do with negotiations, but if both sides can’t be persuaded to back down, then they will be on a trajectory that could lead to the collapse of the Palestinian Authority because it can’t pay wages anymore. - “That could be an issue forced onto the agenda about the same time as a potential nuclear deal.” -
- President Obama told the U.N. General Assembly 18 months ago that he would seek “real breakthroughs on these two issues — Iran’s nuclear program and Israeli-Palestinian peace.” - But Benjamin Netanyahu’s triumph in Tuesday’s parliamentary elections keeps in place an Israeli prime minister who has declared his intention to resist Obama on both of these fronts, guaranteeing two more years of difficult diplomacy between leaders who barely conceal their personal distaste for each other. - The Israeli election results also suggest that most voters there support Netanyahu’s tough stance on U.S.-led negotiations to limit Iran’s nuclear program and his vow on Monday that there would be no independent Palestinian state as long as he is prime minister. - “On the way to his election victory, Netanyahu broke a lot of crockery in the relationship,” said Martin Indyk, executive vice president of the Brookings Institution and a former U.S. ambassador to Israel. “It can’t be repaired unless both sides have an interest and desire to do so.” - Aside from Russian President Vladimir Putin, few foreign leaders so brazenly stand up to Obama and even fewer among longtime allies. - - Israeli Prime Minister Benjamin Netanyahu pledged to form a new governing coalition quickly after an upset election victory that was built on a shift to the right. (Reuters) - - In the past, Israeli leaders who risked damaging the country’s most important relationship, that with Washington, tended to pay a price. In 1991, when Prime Minister Yitzhak Shamir opposed the Madrid peace talks, President George H.W. Bush held back loan guarantees to help absorb immigrants from the former Soviet Union. Shamir gave in, but his government soon collapsed. - But this time, Netanyahu was not hurt by his personal and substantive conflicts with the U.S. president. - “While the United States is loved and beloved in Israel, President Obama is not,” said Robert M. Danin, a senior fellow at the Council on Foreign Relations. “So the perceived enmity didn’t hurt the way it did with Shamir when he ran afoul of Bush in ’91.” - Where do U.S.-Israeli relations go from here? - In the immediate aftermath of Tuesday’s elections, tensions between the two sides continued to run hot. The Obama administration’s first comments on the Israeli election came with a tough warning about some of the pre-election rhetoric from Netanyahu’s Likud party, which tried to rally right-wing support by saying that Arab Israeli voters were “coming out in droves.” - “The United States and this administration is deeply concerned about rhetoric that seeks to marginalize Arab Israeli citizens,” White House press secretary Josh Earnest told reporters aboard Air Force One. “It undermines the values and democratic ideals that have been important to our democracy and an important part of what binds the United States and Israel together.” - Earnest added that Netanyahu’s election-eve disavowal of a two-state solution for Israelis and Palestinians would force the administration to reconsider its approach to peace in the region. - Over the longer term, a number of analysts say that Obama and Netanyahu will seek to play down the friction between them and point to areas of continuing cooperation on military and economic issues. - “Both sides are going to want to turn down the rhetoric,” Danin said. “But it is also a structural problem. They have six years of accumulated history. That’s going to put limits on how far they can go together.” - The first substantive test could come as early as this month, when the United States hopes that it can finish hammering out the framework of an agreement with Iran. - Netanyahu strongly warned against making a “bad deal” during his March 3 address to a joint meeting of Congress, an appearance arranged by Republican congressional leaders and criticized by the Obama administration for making U.S.-Israeli relations partisan on both sides so close to the Israeli election. - If a deal is reached and does not pass muster with Netanyahu, he is likely to work with congressional Republicans to try to scuttle the accord. - “The Republicans have said they will do what they can to block a deal, and the prime minister has already made clear that he will work with the Republicans against the president,” Indyk said. “That’s where a clash could come, and it’s coming very quickly.” - The second test — talks with Palestinians — could be even more difficult. In his September 2013 address to the United Nations, Obama hailed signs of hope. - “Already, Israeli and Palestinian leaders have demonstrated a willingness to take significant political risks,” Obama said in his speech. Palestinian Authority President Mahmoud Abbas “has put aside efforts to shortcut the pursuit of peace and come to the negotiating table. Prime Minister Netanyahu has released Palestinian prisoners and reaffirmed his commitment to a Palestinian state.” - Today, the signals could not differ more. The Palestinian Authority has said that after it joins the International Criminal Court at The Hague on April 1, it will press war crimes charges against Israel for the bloody Gaza conflict during the summer. Israel, which controls tax receipts, has pledged to punish the Palestinian Authority by freezing its tax revenue. - The United States, which gives hundreds of millions of dollars of economic aid to the Palestinian Authority, would be caught in the middle. It has been trying to persuade both sides to stand down, but Netanyahu’s declaration that there would be no Palestinian state on his watch makes that more difficult. - “Now it’s hard to see what could persuade the Palestinians” to hold up on their ICC plans, Indyk said. “That has nothing to do with negotiations, but if both sides can’t be persuaded to back down, then they will be on a trajectory that could lead to the collapse of the Palestinian Authority because it can’t pay wages anymore. - “That could be an issue forced onto the agenda about the same time as a potential nuclear deal.” -
- President Obama told the U.N. General Assembly 18 months ago that he would - seek “real breakthroughs on these two issues — Iran’s nuclear program and - Israeli-Palestinian peace.” - But Benjamin Netanyahu’s triumph in Tuesday’s - parliamentary elections keeps in place an Israeli prime minister who has - declared his intention to resist Obama on both of these fronts, guaranteeing - two more years of difficult diplomacy between leaders who barely conceal - their personal distaste for each other. - The Israeli election results also suggest that most voters there support - Netanyahu’s tough stance on U.S.-led negotiations to limit Iran’s nuclear - program and his vow on Monday that there would be no independent Palestinian state as long - as he is prime minister. - “On the way to his election victory, Netanyahu broke a lot of crockery - in the relationship,” said Martin Indyk, executive vice president of the - Brookings Institution and a former U.S. ambassador to Israel. “It can’t - be repaired unless both sides have an interest and desire to do so.” - Aside from Russian President Vladimir Putin, few foreign leaders so brazenly - stand up to Obama and even fewer among longtime allies. - - - - - Israeli Prime Minister Benjamin Netanyahu pledged to form a new governing coalition quickly after an upset election victory that was built on a shift to the right. (Reuters) - - - In the past, Israeli leaders who risked damaging the country’s most important - relationship, that with Washington, tended to pay a price. In 1991, when - Prime Minister Yitzhak Shamir opposed the Madrid peace talks, President - George H.W. Bush held back loan guarantees to help absorb immigrants from - the former Soviet Union. Shamir gave in, but his government soon collapsed. - But this time, Netanyahu was not hurt by his personal and substantive - conflicts with the U.S. president. - “While the United States is loved and beloved in Israel, President Obama - is not,” said Robert M. Danin, a senior fellow at the Council on Foreign - Relations. “So the perceived enmity didn’t hurt the way it did with Shamir - when he ran afoul of Bush in ’91.” - Where do U.S.-Israeli relations go from here? - In the immediate aftermath of Tuesday’s elections, tensions between the - two sides continued to run hot. The Obama administration’s first comments - on the Israeli election came with a tough warning about some of the pre-election - rhetoric from Netanyahu’s Likud party, which tried to rally right-wing - support by saying that Arab Israeli voters were “coming out in droves.” - “The United States and this administration is deeply concerned about rhetoric - that seeks to marginalize Arab Israeli citizens,” White House press secretary - Josh Earnest told reporters aboard Air Force One. “It undermines the values - and democratic ideals that have been important to our democracy and an - important part of what binds the United States and Israel together.” - Earnest added that Netanyahu’s election-eve disavowal of a two-state - solution for Israelis and Palestinians would force the administration to - reconsider its approach to peace in the region. - - Over the longer term, a number of analysts say that Obama and Netanyahu - will seek to play down the friction between them and point to areas of - continuing cooperation on military and economic issues. - “Both sides are going to want to turn down the rhetoric,” Danin said. - “But it is also a structural problem. They have six years of accumulated - history. That’s going to put limits on how far they can go together.” - The first substantive test could come as early as this month, when the - United States hopes that it can finish hammering out the framework of an - agreement with Iran. - Netanyahu strongly warned against making a “bad deal” during his March - 3 address to a joint meeting of Congress, an appearance arranged by Republican - congressional leaders and criticized by the Obama administration for making - U.S.-Israeli relations partisan on both sides so close to the Israeli election. - If a deal is reached and does not pass muster with Netanyahu, he is likely - to work with congressional Republicans to try to scuttle the accord. - “The Republicans have said they will do what they can to block a deal, - and the prime minister has already made clear that he will work with the - Republicans against the president,” Indyk said. “That’s where a clash could - come, and it’s coming very quickly.” - The second test — talks with Palestinians — could be even more difficult. - In his September 2013 address to the United Nations, Obama hailed signs - of hope. - “Already, Israeli and Palestinian leaders have demonstrated a willingness - to take significant political risks,” Obama said in his speech. Palestinian - Authority President Mahmoud Abbas “has put aside efforts to shortcut the - pursuit of peace and come to the negotiating table. Prime Minister Netanyahu - has released Palestinian prisoners and reaffirmed his commitment to a Palestinian - state.” - Today, the signals could not differ more. The - Palestinian Authority has said that after it joins the International Criminal - Court at The Hague on April 1, it will press war crimes charges against - Israel for the bloody Gaza conflict during the summer. Israel, which controls - tax receipts, has pledged to punish the Palestinian Authority by freezing - its tax revenue. - The United States, which gives hundreds of millions of dollars of economic - aid to the Palestinian Authority, would be caught in the middle. It has - been trying to persuade both sides to stand down, but Netanyahu’s declaration - that there would be no Palestinian state on his watch makes that more difficult. - “Now it’s hard to see what could persuade the Palestinians” to hold up - on their ICC plans, Indyk said. “That has nothing to do with negotiations, - but if both sides can’t be persuaded to back down, then they will be on - a trajectory that could lead to the collapse of the Palestinian Authority - because it can’t pay wages anymore. - “That could be an issue forced onto the agenda about the same time as - a potential nuclear deal.” - - - -
- - - Movies - - - - - - ‘Star Wars’ Original Cuts Might Get Released for 40th Anniversary - - - - - - - James Akinaka - - - - • - - 8h - - - - - - - - Share - - - - Tweet - - - - Share - - - - - - - - - Although Lucasfilm is already planning a birthday bash for the Star Wars Saga at Celebration Orlando this April, fans might get another present for the saga’s 40th anniversary. According to fan site MakingStarWars.net, rumors abound that Lucasfilm might re-release the unaltered cuts of the saga’s original trilogy. - If the rumors are true, this is big news for Star Wars fans. Aside from limited VHS releases, the unaltered cuts of the original trilogy films haven’t been available since they premiered in theaters in the 1970s and ’80s. If Lucasfilm indeed re-releases the films’ original cuts, then this will be the first time in decades that fans can see the films in their original forms. Here’s what makes the unaltered cuts of the original trilogy so special. - The Star Wars Special Editions Caused Controversy - - - Thanks to the commercial success of Star Wars, George Lucas has revisited and further edited his films for re-releases. The most notable — and controversial — release were the Special Editions of the original trilogy. In 1997, to celebrate the saga’s 20th anniversary, Lucasfilm spent a total of $15 million to remaster A New Hope, The Empire Strikes Back, and Return of the Jedi. The Special Editions had stints in theaters before moving to home media. - Although most of the Special Editions’ changes were cosmetic, others significantly affected the plot of the films. The most notable example is the “Han shot first” scene in A New Hope. As a result, the Special Editions generated significant controversy among Star Wars fans. Many fans remain skeptical about George Lucas’s decision to finish each original trilogy film “the way it was meant to be.” - - - - While the Special Editions represent the most significant edits to the original trilogy, the saga has undergone other changes. Following up on the saga’s first Blu-ray release in 2011, Industrial Light & Magic (ILM) began remastering the entire saga in 3D, starting with the prequel trilogy. The Phantom Menace saw a theatrical 3D re-release in 2012, but Disney’s 2012 acquisition of Lucasfilm indefinitely postponed further 3D releases. - In 2015, Attack of the Clones and Revenge of the Sith received limited 3D showings at Celebration Anaheim. Other than that, it seems as though Disney has decided to refocus Lucasfilm’s efforts to new films. Of course, that’s why the saga has produced new content beginning with The Force Awakens. However, it looks like Lucasfilm isn’t likely to generate 3D versions of the original trilogy anytime soon. - Why the Original Film Cuts Matter - - - - Admittedly, the differences between the original trilogy’s unaltered cuts and the Special Editions appeal to more hardcore fans. Casual fans are less likely to care about whether Greedo or Han Solo shot first. Still, given Star Wars’ indelible impact on pop culture, there’s certainly a market for the original trilogy’s unaltered cuts. They might not be for every Star Wars fan, but many of us care about them. - ILM supervisor John Knoll, who first pitched the story idea for Rogue One, said last year that ILM finished a brand new 4K restoration print of A New Hope. For that reason, it seems likely that Lucasfilm will finally give diehard fans the original film cuts that they’ve clamored for. There’s no word yet whether the unaltered cuts will be released in theaters or on home media. At the very least, however, fans will likely get them after all this time. After all, the Special Editions marked the saga’s 20th anniversary. Star Wars turns 40 years old this year, so there’s no telling what’s in store. - - - - Would you like to be part of the Fandom team? Join our Fan Contributor Program and share your voice on Fandom.com! - - - - - - - James Akinaka - James Akinaka arrives at Fandom by way of Wookieepedia. He covers Star Wars, superheroes, and animation and values bold, inclusive stories. He suffers from a lifelong case of nitpicking and high standards. - - - - - - - - - - View Profile - - - - -
- - - Stack Overflow published its analysis of 2017 hiring trends based on the targeting options employers selected when posting to Stack Overflow Jobs. The report, which compares data from 200 companies since 2015, ranks ReactJS, Docker, and Ansible at the top of the fastest growing skills in demand. When comparing the percentage change from 2015 to 2016, technologies like AJAX, Backbone.js, jQuery, and WordPress are less in demand. - - Stack Overflow also measured the demand relative to the available developers in different tech skills. The demand for backend, mobile, and database engineers is higher than the number of qualified candidates available. WordPress is last among the oversaturated fields with a surplus of developers relative to available positions. - - In looking at these results, it’s important to consider the inherent biases within the Stack Overflow ecosystem. In 2016, the site surveyed more than 56,000 developers but noted that the survey was “biased against devs who don’t speak English.” The average age of respondents was 29.6 years old and 92.8% of them were male. - For two years running, Stack Overflow survey respondents have ranked WordPress among the most dreaded technologies that they would prefer not to use. This may be one reason why employers wouldn’t be looking to advertise positions on the site’s job board, which is the primary source of the data for this report. - Many IT career forecasts focus more generally on job descriptions and highest paying positions. Stack Overflow is somewhat unique in that it identifies trends in specific tech skills, pulling this data out of how employers are tagging their listings for positions. It presents demand in terms of number of skilled developers relative to available positions, a slightly more complicated approach than measuring demand based on advertised salary. However, Stack Overflow’s data presentation could use some refining. - One commenter, Bruce Van Horn, noted that jobs tagged as “Full Stack Developer” already assume many of the skills that are listed separately: - - I wonder how many of these skills are no longer listed because they are “table stakes”. You used to have to put CSS, jQuery, and JSON on the job description. I wouldn’t expect to have to put that on a Full Stack Developer description today – if you don’t know those then you aren’t a Full Stack Web Developer, and I’m more interested in whether you know the shiny things like React, Redux, and Angular2. - - It would be interesting to know what is meant by tagging “WordPress” as a skill – whether it is the general ability to work within the WordPress ecosystem of tools or if it refers to specific skills like PHP. Browsing a few jobs on Stack Overflow, WordPress positions vary in the skills they require, such as React.js, Angular, PHP, HTML, CSS, and other technologies. This is a reflection of the diversity of technology that can be leveraged in creating WordPress-powered sites and applications, and several of these skills are listed independently of WordPress in the data. - Regardless of how much credibility you give Stack Overflow’s analysis of hiring trends, the report’s recommendation for those working in technologies oversaturated with developers is a good one: “Consider brushing up on some technologies that offer higher employer demand and less competition.” WordPress’ code base is currently 59% PHP and 27% JavaScript. The percentage of PHP has grown over time, but newer features and improvements to core are also being built in JavaScript. These are both highly portable skills that are in demand on the web. - -
- - - - - Stack Overflow Jobs Data Shows ReactJS Skills in High Demand, WordPress Market Oversaturated with Developers - - - Sarah Gooding - - March 9, 2017 - 13 - - - - - - - - - - Stack Overflow published its analysis of 2017 hiring trends based on the targeting options employers selected when posting to Stack Overflow Jobs. The report, which compares data from 200 companies since 2015, ranks ReactJS, Docker, and Ansible at the top of the fastest growing skills in demand. When comparing the percentage change from 2015 to 2016, technologies like AJAX, Backbone.js, jQuery, and WordPress are less in demand. - - - - Stack Overflow also measured the demand relative to the available developers in different tech skills. The demand for backend, mobile, and database engineers is higher than the number of qualified candidates available. WordPress is last among the oversaturated fields with a surplus of developers relative to available positions. - - - - In looking at these results, it’s important to consider the inherent biases within the Stack Overflow ecosystem. In 2016, the site surveyed more than 56,000 developers but noted that the survey was “biased against devs who don’t speak English.” The average age of respondents was 29.6 years old and 92.8% of them were male. - For two years running, Stack Overflow survey respondents have ranked WordPress among the most dreaded technologies that they would prefer not to use. This may be one reason why employers wouldn’t be looking to advertise positions on the site’s job board, which is the primary source of the data for this report. - Many IT career forecasts focus more generally on job descriptions and highest paying positions. Stack Overflow is somewhat unique in that it identifies trends in specific tech skills, pulling this data out of how employers are tagging their listings for positions. It presents demand in terms of number of skilled developers relative to available positions, a slightly more complicated approach than measuring demand based on advertised salary. However, Stack Overflow’s data presentation could use some refining. - One commenter, Bruce Van Horn, noted that jobs tagged as “Full Stack Developer” already assume many of the skills that are listed separately: - - I wonder how many of these skills are no longer listed because they are “table stakes”. You used to have to put CSS, jQuery, and JSON on the job description. I wouldn’t expect to have to put that on a Full Stack Developer description today – if you don’t know those then you aren’t a Full Stack Web Developer, and I’m more interested in whether you know the shiny things like React, Redux, and Angular2. - - It would be interesting to know what is meant by tagging “WordPress” as a skill – whether it is the general ability to work within the WordPress ecosystem of tools or if it refers to specific skills like PHP. Browsing a few jobs on Stack Overflow, WordPress positions vary in the skills they require, such as React.js, Angular, PHP, HTML, CSS, and other technologies. This is a reflection of the diversity of technology that can be leveraged in creating WordPress-powered sites and applications, and several of these skills are listed independently of WordPress in the data. - Regardless of how much credibility you give Stack Overflow’s analysis of hiring trends, the report’s recommendation for those working in technologies oversaturated with developers is a good one: “Consider brushing up on some technologies that offer higher employer demand and less competition.” WordPress’ code base is currently 59% PHP and 27% JavaScript. The percentage of PHP has grown over time, but newer features and improvements to core are also being built in JavaScript. These are both highly portable skills that are in demand on the web. - - - Share this: - - - Click to email this to a friend (Opens in new window) - 61Click to share on Facebook (Opens in new window)61 - Click to share on Twitter (Opens in new window) - Click to share on Telegram (Opens in new window) - Click to share on WhatsApp (Opens in new window) - Click to share on Google+ (Opens in new window) - Click to share on Pocket (Opens in new window) - Click to share on Reddit (Opens in new window) - - - - - - - Like this: - Like Loading... - - - - Related - - - - Stack Overflow Survey Results Show WordPress is Trending Up, Despite Being Ranked Among Most Dreaded Technologies - Stack Overflow published the results of its 2016 Developer Survey, summarizing responses from 56,033 developers in 173 countries. The 45-question survey collected answers from more than twice as many developers as the previous year. The results were published along with a disclaimer recognizing that the survey is "biased against devs… - March 17, 2016 - In "News" - - - - Stack Overflow Developer Survey Ranks WordPress as the 3rd Most Dreaded Technology - Stack Overflow has released the results of its 2015 developer survey, which covers a wide range of topics including preferred programming languages, education, compensation, and even caffeine consumption. The 45-question survey ran for just two weeks in February and the site was able to collect results from more than 26,000… - April 8, 2015 - In "News" - - - - Stack Overflow Documentation is Now in Beta - Building on the success of its Q&A communities, Stack Overflow announced that its new Documentation product is now in beta. For the past eight years, the site has rewarded expert advice by floating high quality answers to the top and allowing users to earn reputation points. This formula has turned… - July 22, 2016 - In "News" - - - - - - - - - - - -
- - - - - If there were really no demand for WordPress developers, I would not be so busy. But there may not be that much demand for the kind of developers who hang out on Stack Overflow’s job board.Report - - - - - - - Reply - - - -
- - - - - One nuance of over saturation number might be that many people who self–identify themselves as WordPress “developers” might be in “site builder” segment. Off–the–shelf assembly and lightweight customization rather than involved custom development. - I had certainly never had an impression that there is an oversupply of of WP devs with advanced level of PHP and experience in custom projects.Report - - - - - - - Reply - - - -
- - - - - I feel like you’re 100% right on this one. WordPress has many self called ‘developers’ who actually don’t know how to code. I think there’s indeed a lot competition in that space (the “Off–the–shelf assembly and lightweight customization”) but there’s still more than enough work for developers that can actually code complex custom solutions in WP.Report - - - - - - - Reply - - - -
- - - - - Would you put yourself in that category of page builders?Report - - - - - - - Reply - - - -
- - - - - If I consider myself a ‘page builder’? If you’re asking if I do “Off–the–shelf assembly and lightweight customization” WordPress work, no I don’t. I make and sell WordPress plugins that allow others to do so though :)Report - - - - - - - - - - -
- - - - - You’re 100% correct Rarst. In my opinion, if a person does not have the skills of a computer scientist (OOP specifically) then they cannot really hold the title of a “developer,” albeit outside of project management skills; UML, scrum, etc. Developers can develop because when their calculator breaks, they can still do the math, so to speak. It will just be a little slower. - Installation, light-weight customization, tweaks, etc., relative to the WP theme design or not, is NOT true development. You must know code/syntax, algorithms (e.g. optimization techniques), etc. to truly “develop” big [project] picture, small picture, and the realtionships between them to tweak code. THAT is development.Report - - - - - - - Reply - - - -
- - - - - Agree with you. WordPress is heading towards the right direction and It is necessary to implement REST API quickly to make it more accessible for people who hate to deal with PHP or WordPress tags. Report - - - - - - - Reply - - - -
- - - - - tons of wordpress devs – and yet hardly any buddypress devs. I’ve posted several bp jobs and still have 4 plugin projects where no one will take my money.Report - - - - - - - Reply - - - -
- - - - - I’m a “BuddyPress developer”, as well as quite a bunch of other people. The problem is that BP is not that big market, it’s not that easy to be 100% focused on BP-related projects only. So such people are either working with WP (mainly) and BP (when something – seldom – appear), or have own business around WP (and sometimes) BP. And such people are marketing WP skills more, I guess.Report - - - - - - - Reply - - - -
- - - - - Why doesn’t WordPress have some kind of certification system when it comes to working with WordPress? Make it something similar to CompTIA A+ certification. There could be different levels of verification to cover all aspects of WordPress. It would be a benefit to anyone trying to make a living working with WordPress. It would also be a major benefit for anyone seeking to hire a WordPress professional. There could be a centralized location on dot org that would list certified WordPress professionals tagged with their various certifications. - Currently, it’s so hit or miss when it comes to hiring someone to provide help with WordPress. You might need someone with just a basic skill set to set up a new site with a standard theme and some basic plugins, but the person you hire is more suited for advanced, complex integrations involving multiple APIs. The problem is, the customer ends up paying far more than they really need to for someone with skill sets far more advanced than what they actually need. Report - - - - - - - Reply - - - -
- - - - - In theory, this might be a good idea, though just who would do the certifying? In practice, however, I’ve heard from people who’ve been developing compiled software since before PHP existed that a lot of those certifications really test your ability to take standardized tests, not your ability as a programmer. The best way to hire anybody to do anything is to get a personal recommendation.Report - - - - - - - Reply - - - -
- - - - - WordPress.org should do the certifications. Individual testing could happen at WordCamps and/or at local testing facilities like how CompTIA A+ certification is handled. Most clients do not need a programmer or a developer. They need someone who can set up a website. That means finding a host, installing WordPress, installing a theme, and installing plugins. - If someone hires a programmer to do all that, they are most likely overpaying for the work. - Report - - - - - - - Reply - - - -
- - - - - Were you volunteering to help design the tests and conduct the certifications? Or at least set up the means to organize it on make.wordpress.org? It’s an idea that has potential merit and you aren’t the first person to wish there were some kind of standards by which to judge a person’s basic WordPress literacy. - To the best of my knowledge, however, everything done by WordPress.org is handled by volunteers. In the spirit of open source, if there’s something you want to see happen, you need to get it started. - An idea like certification would actually need much broader support throughout the WordPress community than a choice of what to focus development on for the next release. And it would require either a means to administer and grade the test online automatically (requiring programming to make it work) or a fairly large army of volunteers to undertake in-person testing. I imagine you could tie up years of surveys and committee meetings just figuring out what you wanted to test for, never mind designing the test itself. - And you have to decide how often people need to re-certify, because recommendations and best practices change rapidly in the web world. - Even if you get that far, it will only make a difference if enough people accept the validity of the test and care whether someone has passed it before hiring them. - And, finally, a test like that could determine whether the person had enough skill to install WordPress, set up a theme, and choose some plugins, or (at a more advanced level) whether they understand WordPress’ action and filter hooks, plus PHP, HTML, CSS, and JavaScript, but it will never tell you whether a person is honest, timely, able to understand (or even ask) what a client’s real needs and goals are, or someone you can work with without both of you going crazy.Report - - - - - - - - - - -
- - - - - - - Sony’s PlayStation VR. - - - - - Virtual reality has officially reached the consoles. And it’s pretty good! Sony’s PlayStation VR is extremely comfortable and reasonably priced, and while it’s lacking killer apps, it’s loaded with lots of interesting ones. - But which ones should you buy? I’ve played just about every launch game, and while some are worth your time, others you might want to skip. To help you decide what’s what, I’ve put together this list of the eight PSVR games worth considering. - “Rez Infinite” ($30) - - Beloved cult hit “Rez” gets the VR treatment to help launch the PSVR, and the results are terrific. It includes a fully remastered take on the original “Rez” – you zoom through a Matrix-like computer system, shooting down enemies to the steady beat of thumping electronica – but the VR setting makes it incredibly immersive. It gets better the more you play it, too; unlock the amazing Area X mode and you’ll find yourself flying, shooting and bobbing your head to some of the trippiest visuals yet seen in VR. - “Thumper” ($20) - - What would happen if Tron, the board game Simon, a Clown beetle, Cthulhu and a noise band met in VR? Chaos, for sure, and also “Thumper.” Called a “violent rhythm game” by its creators, “Thumper” is, well, a violent rhythm game that’s also a gorgeous, unsettling and totally captivating assault on the senses. With simple controls and a straightforward premise – click the X button and the analog stick in time with the music as you barrel down a neon highway — it’s one of the rare games that works equally well both in and out of VR. But since you have PSVR, play it there. It’s marvelous. - “Until Dawn: Rush of Blood” ($20) - - Cheeky horror game “Until Dawn” was a breakout hit for the PS4 last year, channeling the classic “dumb teens in the woods” horror trope into an effective interactive drama. Well, forget all that if you fire up “Rush of Blood,” because this one sticks you front and center on a rollercoaster ride from Hell. Literally. You ride through a dimly-lit carnival of terror, dual-wielding pistols as you take down targets, hideous pig monsters and, naturally, maniac clowns. Be warned: If the bad guys don’t get you, the jump scares will. - “Headmaster” ($20) - - Soccer meets “Portal” in the weird (and weirdly fun) “Headmaster,” a game about heading soccer balls into nets, targets and a variety of other things while stuck in some diabolical training facility. While at first it seems a little basic, increasingly challenging shots and a consistently entertaining narrative keep it from running off the pitch. Funny, ridiculous and as easy as literally moving your head back and forth, it’s a pleasant PSVR surprise. - “RIGS: Mechanized Combat League” ($50) - - Giant mechs + sports? That’s the gist of this robotic blast-a-thon, which pits two teams of three against one another in gorgeous, explosive and downright fun VR combat. At its best, “RIGS” marries the thrill of fast-paced competitive shooters with the insanity of piloting a giant mech in VR. It can, however, be one of the barfier PSVR games. So pack your Dramamine, you’re going to have to ease yourself into this one. - “Batman Arkham VR” ($20) - - “I’m Batman,” you will say. And you’ll actually be right this time, because you are Batman in this detective yarn, and you know this because you actually grab the famous cowl and mask, stick it on your head, and stare into the mirrored reflection of Rocksteady Games’ impressive Dark Knight character model. It lacks the action of its fellow “Arkham” games and runs disappointingly short, but it’s a high-quality experience that really shows off how powerfully immersive VR can be. - “Job Simulator” ($30) - - There are a number of good VR ports in the PSVR launch lineup, but the HTC Vive launch game “Job Simulator” might be the best. Your task? Lots of tasks, actually, from cooking food to fixing cars to working in an office, all for robots, because did I mention you were in the future? Infinitely charming and surprisingly challenging, it’s a great showpiece for VR. - “Eve Valkyrie” ($60) - - Already a hit on the Oculus Rift, this space dogfighting game was one of the first to really show off how VR can turn a traditional game experience into something special. It’s pricey and not quite as hi-res as the Rift version, but “Eve Valkyrie” does an admirable job filling the void left since “Battlestar Galactica” ended. Too bad there aren’t any Cylons in it (or are there?) - More games news: - - ‘Skylanders Imaginators’ will let you create and 3D print your own action figures - Review: High-flying ‘NBA 2K17’ has a career year - Review: Race at your own speed in big, beautiful ‘Forza Horizon 3’ - Sony’s PlayStation 4 Pro shows promise, potential and plenty of pretty lighting - Review: ‘Madden NFL 17’ runs hard, plays it safe - - Ben Silverman is on Twitter at ben_silverman. - -
- - - - - Sony’s PlayStation VR. - More - - - Virtual reality has officially reached the consoles. And it’s pretty good! Sony’s PlayStation VR is extremely comfortable and reasonably priced, and while it’s lacking killer apps, it’s loaded with lots of interesting ones. - But which ones should you buy? I’ve played just about every launch game, and while some are worth your time, others you might want to skip. To help you decide what’s what, I’ve put together this list of the eight PSVR games worth considering. - “Rez Infinite” ($30) - - Beloved cult hit “Rez” gets the VR treatment to help launch the PSVR, and the results are terrific. It includes a fully remastered take on the original “Rez” – you zoom through a Matrix-like computer system, shooting down enemies to the steady beat of thumping electronica – but the VR setting makes it incredibly immersive. It gets better the more you play it, too; unlock the amazing Area X mode and you’ll find yourself flying, shooting and bobbing your head to some of the trippiest visuals yet seen in VR. - “Thumper” ($20) - - What would happen if Tron, the board game Simon, a Clown beetle, Cthulhu and a noise band met in VR? Chaos, for sure, and also “Thumper.” Called a “violent rhythm game” by its creators, “Thumper” is, well, a violent rhythm game that’s also a gorgeous, unsettling and totally captivating assault on the senses. With simple controls and a straightforward premise – click the X button and the analog stick in time with the music as you barrel down a neon highway — it’s one of the rare games that works equally well both in and out of VR. But since you have PSVR, play it there. It’s marvelous. - “Until Dawn: Rush of Blood” ($20) - - Cheeky horror game “Until Dawn” was a breakout hit for the PS4 last year, channeling the classic “dumb teens in the woods” horror trope into an effective interactive drama. Well, forget all that if you fire up “Rush of Blood,” because this one sticks you front and center on a rollercoaster ride from Hell. Literally. You ride through a dimly-lit carnival of terror, dual-wielding pistols as you take down targets, hideous pig monsters and, naturally, maniac clowns. Be warned: If the bad guys don’t get you, the jump scares will. - “Headmaster” ($20) - - Soccer meets “Portal” in the weird (and weirdly fun) “Headmaster,” a game about heading soccer balls into nets, targets and a variety of other things while stuck in some diabolical training facility. While at first it seems a little basic, increasingly challenging shots and a consistently entertaining narrative keep it from running off the pitch. Funny, ridiculous and as easy as literally moving your head back and forth, it’s a pleasant PSVR surprise. - “RIGS: Mechanized Combat League” ($50) - - Giant mechs + sports? That’s the gist of this robotic blast-a-thon, which pits two teams of three against one another in gorgeous, explosive and downright fun VR combat. At its best, “RIGS” marries the thrill of fast-paced competitive shooters with the insanity of piloting a giant mech in VR. It can, however, be one of the barfier PSVR games. So pack your Dramamine, you’re going to have to ease yourself into this one. - “Batman Arkham VR” ($20) - - “I’m Batman,” you will say. And you’ll actually be right this time, because you are Batman in this detective yarn, and you know this because you actually grab the famous cowl and mask, stick it on your head, and stare into the mirrored reflection of Rocksteady Games’ impressive Dark Knight character model. It lacks the action of its fellow “Arkham” games and runs disappointingly short, but it’s a high-quality experience that really shows off how powerfully immersive VR can be. - “Job Simulator” ($30) - - There are a number of good VR ports in the PSVR launch lineup, but the HTC Vive launch game “Job Simulator” might be the best. Your task? Lots of tasks, actually, from cooking food to fixing cars to working in an office, all for robots, because did I mention you were in the future? Infinitely charming and surprisingly challenging, it’s a great showpiece for VR. - “Eve Valkyrie” ($60) - - Already a hit on the Oculus Rift, this space dogfighting game was one of the first to really show off how VR can turn a traditional game experience into something special. It’s pricey and not quite as hi-res as the Rift version, but “Eve Valkyrie” does an admirable job filling the void left since “Battlestar Galactica” ended. Too bad there aren’t any Cylons in it (or are there?) - More games news: - - ‘Skylanders Imaginators’ will let you create and 3D print your own action figures - Review: High-flying ‘NBA 2K17’ has a career year - Review: Race at your own speed in big, beautiful ‘Forza Horizon 3’ - Sony’s PlayStation 4 Pro shows promise, potential and plenty of pretty lighting - Review: ‘Madden NFL 17’ runs hard, plays it safe - - Ben Silverman is on Twitter at - ben_silverman. - - -
- - - - 1 / 5 - - - In this photo dated Tuesday, Nov, 29, 2016 the Soyuz-FG rocket booster with the Progress MS-04 cargo ship is installed on a launch pad in Baikonur, Kazakhstan. The unmanned Russian cargo space ship Progress MS-04 broke up in the atmosphere over Siberia on Thursday Dec. 1, 2016, just minutes after the launch en route to the International Space Station due to an unspecified malfunction, the Russian space agency said.(Oleg Urusov/ Roscosmos Space Agency Press Service photo via AP) - In this photo dated Tuesday, Nov, 29, 2016 the Soyuz-FG rocket booster with the Progress MS-04 cargo ship is installed on a launch pad in Baikonur, Kazakhstan. The unmanned Russian cargo space ship Progress MS-04 broke up in the atmosphere over Siberia on Thursday Dec. 1, 2016, just minutes after the launch en route to the International Space Station due to an unspecified malfunction, the Russian space agency said.(Oleg Urusov/ Roscosmos Space Agency Press Service photo via AP) - - - - - - - MOSCOW (AP) — An unmanned Russian cargo spaceship heading to the International Space Station broke up in the atmosphere over Siberia on Thursday due to an unspecified malfunction, the Russian space agency said. - The Progress MS-04 cargo craft broke up at an altitude of 190 kilometers (118 miles) over the remote Russian Tuva region in Siberia that borders Mongolia, Roscosmos said in a statement. It said most of spaceship's debris burnt up as it entered the atmosphere but some fell to Earth over what it called an uninhabited area. - Local people reported seeing a flash of light and hearing a loud thud west of the regional capital of Kyzyl, more than 3,600 kilometers (2,200 miles) east of Moscow, the Tuva government was quoted as saying late Thursday by the Interfax news agency. - The Progress cargo ship had lifted off as scheduled at 8:51 p.m. (1451 GMT) from Russia's space launch complex in Baikonur, Kazakhstan, to deliver 2.5 metric tons of fuel, water, food and other supplies. It was set to dock with the space station on Saturday. - Roscosmos said the craft was operating normally before it stopped transmitting data 6 ½ minutes after the launch. The Russian space agency would not immediately describe the malfunction, saying its experts were looking into it. - This is the third botched launch of a Russian spacecraft in two years. A Progress cargo ship plunged into the Pacific Ocean in May 2015, and a Proton-M rocket carrying an advanced satellite broke up in the atmosphere in May 2014. - But both Roscosmos and NASA said the crash of the ship would have no impact on the operations of the orbiting space lab that is currently home to a six-member crew, including three cosmonauts from Russia, two NASA astronauts and one from the European Union. - Orbital ATK, NASA's other shipper, successfully sent up supplies to the space station in October, and a Japanese cargo spaceship is scheduled to launch a full load in mid-December. - NASA supplier SpaceX, meanwhile, has been grounded since a rocket explosion in September on the launch pad at Cape Canaveral, Florida. The company hopes to resume launches in December to deliver communication satellites. - ___ - This version corrects the spelling of the region to Tuva, not Tyva. - __ - Aerospace Writer Marcia Dunn in Cape Canaveral, Florida, and Vladimir Isachenkov in Moscow contributed to this report. - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1 / 5 - - - In this photo dated Tuesday, Nov, 29, 2016 the Soyuz-FG rocket booster with the Progress MS-04 cargo ship is installed on a launch pad in Baikonur, Kazakhstan. The unmanned Russian cargo space ship Progress MS-04 broke up in the atmosphere over Siberia on Thursday Dec. 1, 2016, just minutes after the launch en route to the International Space Station due to an unspecified malfunction, the Russian space agency said.(Oleg Urusov/ Roscosmos Space Agency Press Service photo via AP) - In this photo dated Tuesday, Nov, 29, 2016 the Soyuz-FG rocket booster with the Progress MS-04 cargo ship is installed on a launch pad in Baikonur, Kazakhstan. The unmanned Russian cargo space ship Progress MS-04 broke up in the atmosphere over Siberia on Thursday Dec. 1, 2016, just minutes after the launch en route to the International Space Station due to an unspecified malfunction, the Russian space agency said.(Oleg Urusov/ Roscosmos Space Agency Press Service photo via AP) - - - More - - - - MOSCOW (AP) — An unmanned Russian cargo spaceship heading to the International Space Station broke up in the atmosphere over Siberia on Thursday due to an unspecified malfunction, the Russian space agency said. - The Progress MS-04 cargo craft broke up at an altitude of 190 kilometers (118 miles) over the remote Russian Tuva region in Siberia that borders Mongolia, Roscosmos said in a statement. It said most of spaceship's debris burnt up as it entered the atmosphere but some fell to Earth over what it called an uninhabited area. - Local people reported seeing a flash of light and hearing a loud thud west of the regional capital of Kyzyl, more than 3,600 kilometers (2,200 miles) east of Moscow, the Tuva government was quoted as saying late Thursday by the Interfax news agency. - The Progress cargo ship had lifted off as scheduled at 8:51 p.m. (1451 GMT) from Russia's space launch complex in Baikonur, Kazakhstan, to deliver 2.5 metric tons of fuel, water, food and other supplies. It was set to dock with the space station on Saturday. - Roscosmos said the craft was operating normally before it stopped transmitting data 6 ½ minutes after the launch. The Russian space agency would not immediately describe the malfunction, saying its experts were looking into it. - This is the third botched launch of a Russian spacecraft in two years. A Progress cargo ship plunged into the Pacific Ocean in May 2015, and a Proton-M rocket carrying an advanced satellite broke up in the atmosphere in May 2014. - But both Roscosmos and NASA said the crash of the ship would have no impact on the operations of the orbiting space lab that is currently home to a six-member crew, including three cosmonauts from Russia, two NASA astronauts and one from the European Union. - Orbital ATK, NASA's other shipper, successfully sent up supplies to the space station in October, and a Japanese cargo spaceship is scheduled to launch a full load in mid-December. - NASA supplier SpaceX, meanwhile, has been grounded since a rocket explosion in September on the launch pad at Cape Canaveral, Florida. The company hopes to resume launches in December to deliver communication satellites. - ___ - This version corrects the spelling of the region to Tuva, not Tyva. - __ - Aerospace Writer Marcia Dunn in Cape Canaveral, Florida, and Vladimir Isachenkov in Moscow contributed to this report. - - -


















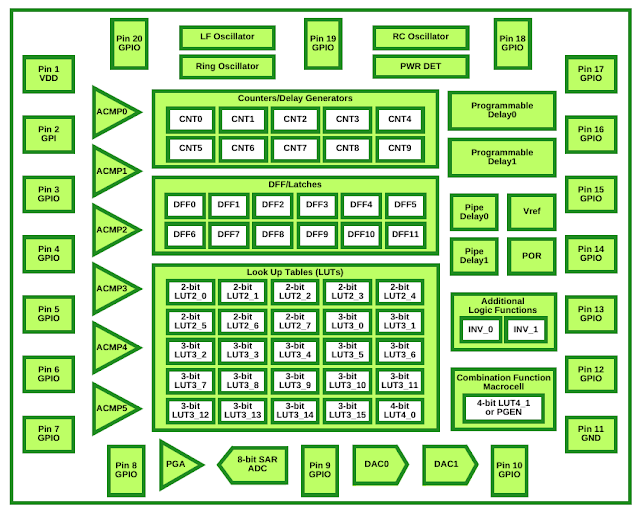










 -
-
-
-
-
-
-
-
-
-
-
-  -
- 









































































































 -
-
-
-
-
-  -
- 

























![[QGIS main interface]](http://fakehost/images/2015/03-qgis-map-sm.png)
![[QGIS query builder]](http://fakehost/images/2015/03-qgis-query-sm.png)
![[QGIS simplify tool]](http://fakehost/images/2015/03-qgis-simplify-sm.png)
![[QGIS style editing]](http://fakehost/images/2015/03-qgis-style-sm.png)

![[QGIS main interface]](/images/2015/03-qgis-map-sm.png)
![[QGIS query builder]](/images/2015/03-qgis-query-sm.png)
![[QGIS simplify tool]](/images/2015/03-qgis-simplify-sm.png)
![[QGIS style editing]](/images/2015/03-qgis-style-sm.png)



































































































![[ up ]](http://fakehost/test/../compass1.gif)
![[ up ]](../compass1.gif)