diff --git a/_articles/writing-hub/writing-contest-2026/kubernetes-runtimeclass.md b/_articles/writing-hub/writing-contest-2026/kubernetes-runtimeclass.md
new file mode 100644
index 0000000..486cb06
--- /dev/null
+++ b/_articles/writing-hub/writing-contest-2026/kubernetes-runtimeclass.md
@@ -0,0 +1,327 @@
+---
+layout: post
+title: "Kubernetes RuntimeClass: Isolate Workloads and Schedule AI/GPU Resources the Right Way"
+date: 2026-04-30
+author: "Chung Ngoc Nguyen"
+tags: [writing-contest-2026-term1, kubernetes, cri, oci, runtimeclass, containerd, cri-o, gvisor, nvidia, gpu, multi-runtime, workload-isolation]
+excerpt: "RuntimeClass is the Kubernetes API object that lets you declare, at the pod level, which runtime should execute a workload one cluster, multiple runtimes, each workload gets exactly what it needs."
+---
+
+## 1. The Problem: Lack of Runtime Isolation in Kubernetes
+
+By default, every workload in a Kubernetes cluster shares a single container runtime - typically containerd with the runc handler. This works fine when all workloads are similar, but breaks down as soon as you need to run different types of workloads in the same cluster at the same time. For example: an AI inference job needs GPU access, a payment service needs strict isolation from untrusted code, and a batch job just needs to run fast and cheap, all on the same cluster, all with different requirements.
+
+Three problems emerge immediately:
+- **No isolation by trust level:** runc shares the host kernel - a compromised container can escape via syscalls and affect the entire node. In multi-tenant or untrusted-code environments, the blast radius of a single breach is the whole node.
+- **GPU resources are wasted:** Without the right runtime handler, nvidia-container-runtime never gets wired in. The scheduler sees GPUs as available, but pods silently fall back to CPU , expensive nodes sit idle while the bill keeps running.
+
+- **Runtime overhead is one-size-fits-all:** You either apply a heavy sandbox like gVisor to everything (unnecessary overhead on simple workloads), or use runc everywhere (insufficient protection for sensitive ones). No per-workload tuning without splitting clusters
+
+RuntimeClass solves this. It is the Kubernetes API object that lets you declare, at the pod level, which runtime should execute a workload and lets the scheduler automatically route pods to nodes that support it. One cluster. Multiple runtimes. Each workload gets exactly what it needs.
+
+## 2. Runtime Stack: From kubelet to OCI
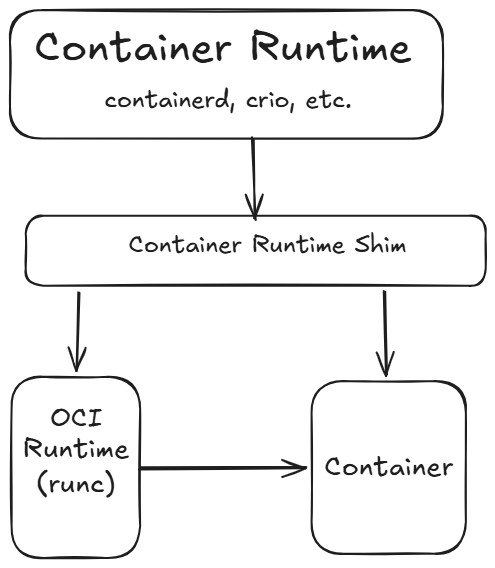
+### Container Runtime vs OCI Runtime
+
+Before working with RuntimeClass, it is important to understand that "container runtime" refers to two different layers in the stack, and confusing them leads to mistakes when configuring handler names.
+
+**Container runtimes** (also called high-level runtimes or CRI runtimes) are responsible for the full container management lifecycle: pulling and storing images, setting up networking via CNI plugins, managing volumes, and coordinating container execution. The major examples are `containerd`, `CRI-O`, and `cri-dockerd`. These are what kubelet talks to.
+
+**OCI runtimes** (low-level runtimes) do one thing: take an OCI bundle (a root filesystem and a config.json) and execute a container process according to the [OCI Runtime Specification](https://github.com/opencontainers/runtime-spec). They create Linux namespaces, set up cgroups, and exec the container's entrypoint. The major examples are `runc`, `crun`, `runsc`, and `nvidia-container-runtime`.
+
+
+  +
+
+
+
+
+Each OCI runtime has a distinct security and performance profile:
+
+- **runc (The Default):** Shares the host kernel. Offers zero overhead and maximum compatibility. Best for: Trusted, internal workloads.
+
+- **crun:** A faster, C-based alternative to runc. Shares the same security model but consumes less memory. Best for: High-density microservices.
+
+- **runsc (gVisor):** Intercepts syscalls via a user-space kernel, strictly isolating containers from the actual host kernel. Trades slight latency for robust security. Best for: Untrusted code, multi-tenant clusters, and strict compliance.
+
+- **nvidia-container-runtime:** A wrapper around runc that automatically injects GPUs and CUDA libraries into the container namespace. Best for: AI/ML inference and training.
+
+
+### Kubelet Talks to the Runtime
+
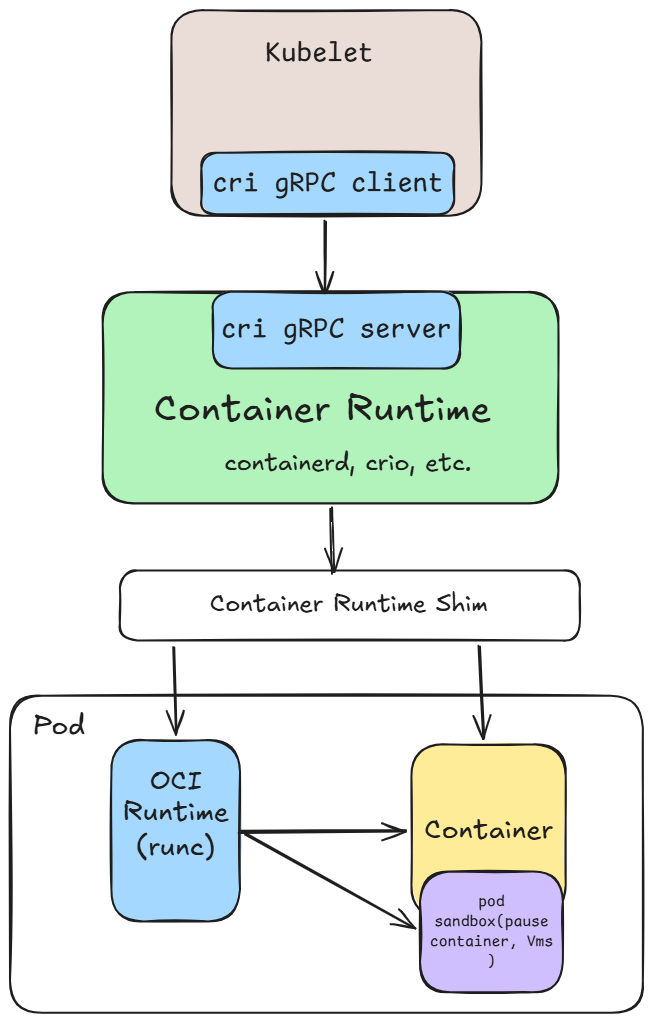
+kubelet does not run containers directly. Instead, it communicates with the container runtime through the **Container Runtime Interface (CRI)** a gRPC API that decouples kubelet from any specific runtime implementation.
+
+The CRI exposes two services:
+- **RuntimeService** - pod sandbox and container lifecycle (create, start, stop, remove)
+- **ImageService** - image operations (pull, list, remove)
+
+At startup, kubelet calls the CRI `Status()` RPC to discover which runtime handlers the node supports. The result is written into the Node's `.status.runtimeHandlers` field - this is what the scheduler reads when placing pods with a `runtimeClassName`.
+
+
+  +
+
+
+Every pod runs inside a sandbox - a shared environment that holds Linux namespaces (network, IPC, UTS) for all containers in that pod. The runtime determines what the sandbox actually is:
+
+
+- `runc` / `crun` using `pause` container on the host kernel
+- `gVisor` using sentry process with a user-space kernel
+- `Kata Containers` using lightweight VM with an isolated guest kernel
+
+
+Because RuntimeClass controls the sandbox type, it applies to the entire pod - not individual containers within it. You cannot mix runtimes inside a single pod.
+
+### RuntimeClass
+
+RuntimeClass is a cluster-scoped Kubernetes API object that maps a name to a specific OCI runtime handler on the node. When a pod sets runtimeClassName, kubelet looks up the handler and passes it to the CRI which delegates to the correct OCI runtime.
+
+```yaml
+apiVersion: node.k8s.io/v1
+kind: RuntimeClass
+metadata:
+ name: gvisor
+handler: runsc
+scheduling:
+ nodeSelector:
+ runtime/gvisor: "true"
+```
+The `scheduling.nodeSelector` field is the key detail: it automatically routes any pod using this RuntimeClass to nodes that have `runsc` installed.
+
+```yaml
+# No nodeSelector needed here,RuntimeClass handles it
+spec:
+ runtimeClassName: gvisor
+ containers:
+ - name: app
+ image: nginx
+```
+The `handler` value must exactly match what is configured in the container runtime on the node. Below are the handler configurations for common runtimes:
+
+**containerd** - `/etc/containerd/config.toml`:
+```yaml
+version = 3
+
+[plugins."io.containerd.cri.v1.runtime".containerd]
+default_runtime_name = "runc"
+
+[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.runc]
+runtime_type = "io.containerd.runc.v2"
+
+[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.runc.options]
+BinaryName = "/usr/local/sbin/runc"
+SystemdCgroup = true
+
+[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.crun]
+runtime_type = "io.containerd.runc.v2"
+
+[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.crun.options]
+BinaryName = "/usr/local/sbin/crun"
+SystemdCgroup = true
+
+[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.runsc]
+runtime_type = "io.containerd.runsc.v1"
+
+[plugins."io.containerd.cri.v1.runtime".containerd.runtimes.runsc.options]
+TypeUrl = "io.containerd.runsc.v1.options"
+ConfigPath = "/etc/containerd/runsc.toml"
+```
+
+**CRI-O** - `/etc/crio/crio.conf`:
+```yaml
+[crio.image]
+signature_policy = "/etc/crio/policy.json"
+
+[crio.runtime]
+default_runtime = "crun"
+
+[crio.runtime.runtimes.crun]
+runtime_path = "/usr/libexec/crio/crun"
+runtime_root = "/run/crun"
+monitor_path = "/usr/libexec/crio/conmon"
+allowed_annotations = [
+ "io.containers.trace-syscall",
+]
+
+[crio.runtime.runtimes.runc]
+runtime_path = "/usr/libexec/crio/runc"
+runtime_root = "/run/runc"
+monitor_path = "/usr/libexec/crio/conmon"
+```
+
+## 3. Architecture Multi-Runtime Cluster and Hands-on Lab
+
+
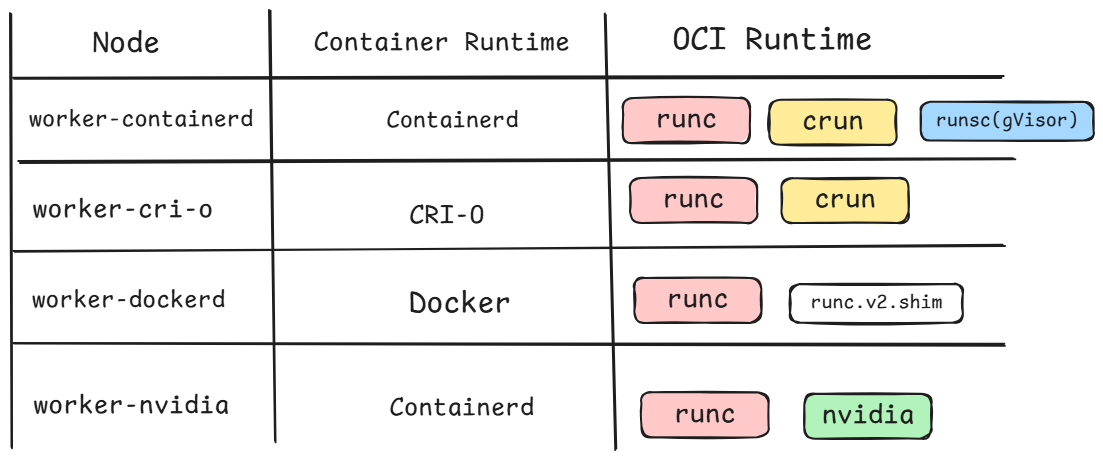
+This lab runs on a 5-node cluster one control plane and four workers, each configured with a different CRI and OCI runtime handlers to cover the full RuntimeClass spectrum
+
+
+  +
+
+
+
+  +
+
+
+**Verify handlers before creating RuntimeClasses:**
+
+```bash
+kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{range .status.runtimeHandlers[*]}{"\""}{.name}{"\", "}{end}{"\n"}{end}'
+```
+
+  +
+
+
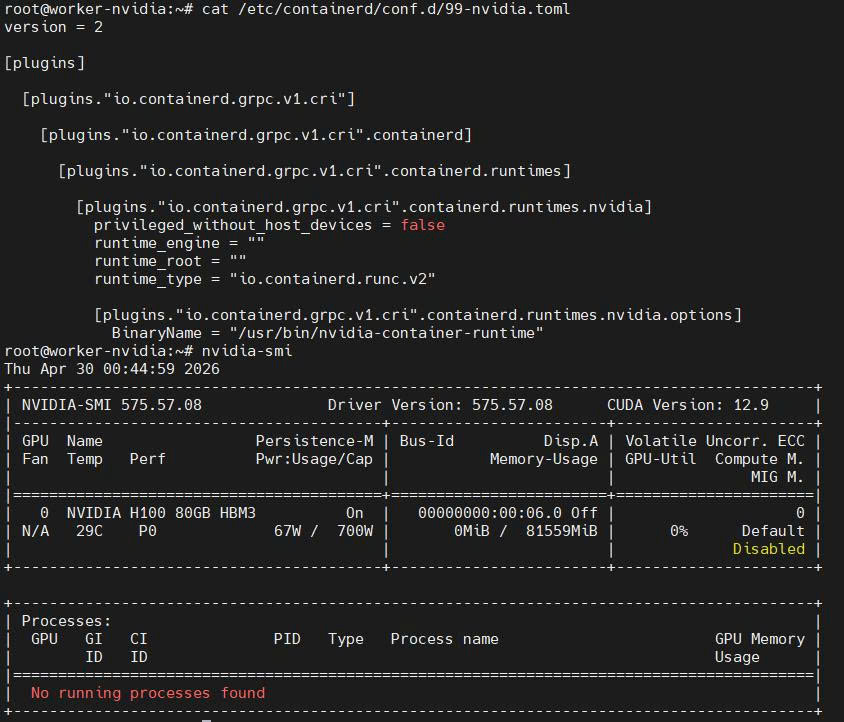
+If a handler is missing, check back through the chain: verify the OCI runtime binary is installed on the node, confirm the handler block exists in the CRI config file (`/etc/containerd/config.toml` for `containerd`, `/etc/crio/crio.conf` for `CRI-O`)
+
+
+  +
+
+### Scheduling RuntimeClass with Node Selector
+
+```crun``` is available on ```worker-containerd``` and ```worker-cri-o```. Label the compatible nodes first:
+
+```bash
+kubectl label node worker-containerd crun=true
+kubectl label node worker-cri-o crun=true
+```
+The RuntimeClass declares the nodeSelector pointing to that label:
+
+```yaml
+# runtimeclass-crun.yaml
+apiVersion: node.k8s.io/v1
+kind: RuntimeClass
+metadata:
+ name: crun
+handler: crun
+scheduling:
+ nodeSelector:
+ crun: "true"
+```
+The Deployment sets ```runtimeClassName: crun``` and uses ``topologySpreadConstraints`` to distribute the 3 replicas evenly across compatible nodes, ```maxSkew: 1``` ensures no node ends up with more than one extra pod compared to others, and ```whenUnsatisfiable: DoNotSchedule``` keeps pods pending rather than violating the spread.
+
+```yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ labels:
+ app: podinfo-crun
+ name: podinfo-crun
+spec:
+ replicas: 3
+ selector:
+ matchLabels:
+ app: podinfo-crun
+ strategy: {}
+ template:
+ metadata:
+ labels:
+ app: podinfo-crun
+ spec:
+ containers:
+ - image: ghcr.io/stefanprodan/podinfo
+ name: podinfo
+ ports:
+ - containerPort: 9898
+ resources: {}
+ runtimeClassName: crun
+ topologySpreadConstraints:
+ - maxSkew: 1
+ topologyKey: kubernetes.io/hostname
+ whenUnsatisfiable: DoNotSchedule
+ labelSelector:
+ matchLabels:
+ app: podinfo-crun
+status: {}
+```
+
+  +
+
+
+3 replicas are running and correctly placed, 2 pods on worker-containerd and 1 on worker-cri-o, exactly as expected from the RuntimeClass nodeSelector. No pods landed on worker-docker.
+
+
+### Scheduling RuntimeClass with Tolerations
+
+Tolerations are used when a node has been tainted to reserve it for a specific workload type. A tainted node repels all pods that do not explicitly tolerate the taint, this prevents standard workloads from consuming capacity on a dedicated node. For GPU nodes, this is essential: without a taint, any pod can land on the GPU node and consume its resources before the AI workload gets scheduled.
+
+
+Label and taint the GPU node:
+
+```bash
+kubectl label node worker-nvidia nvidia=true
+kubectl taint node worker-nvidia nvidia:NoExecute
+```
+Create RuntimeClass nvidia
+
+```yaml
+cat <
+ 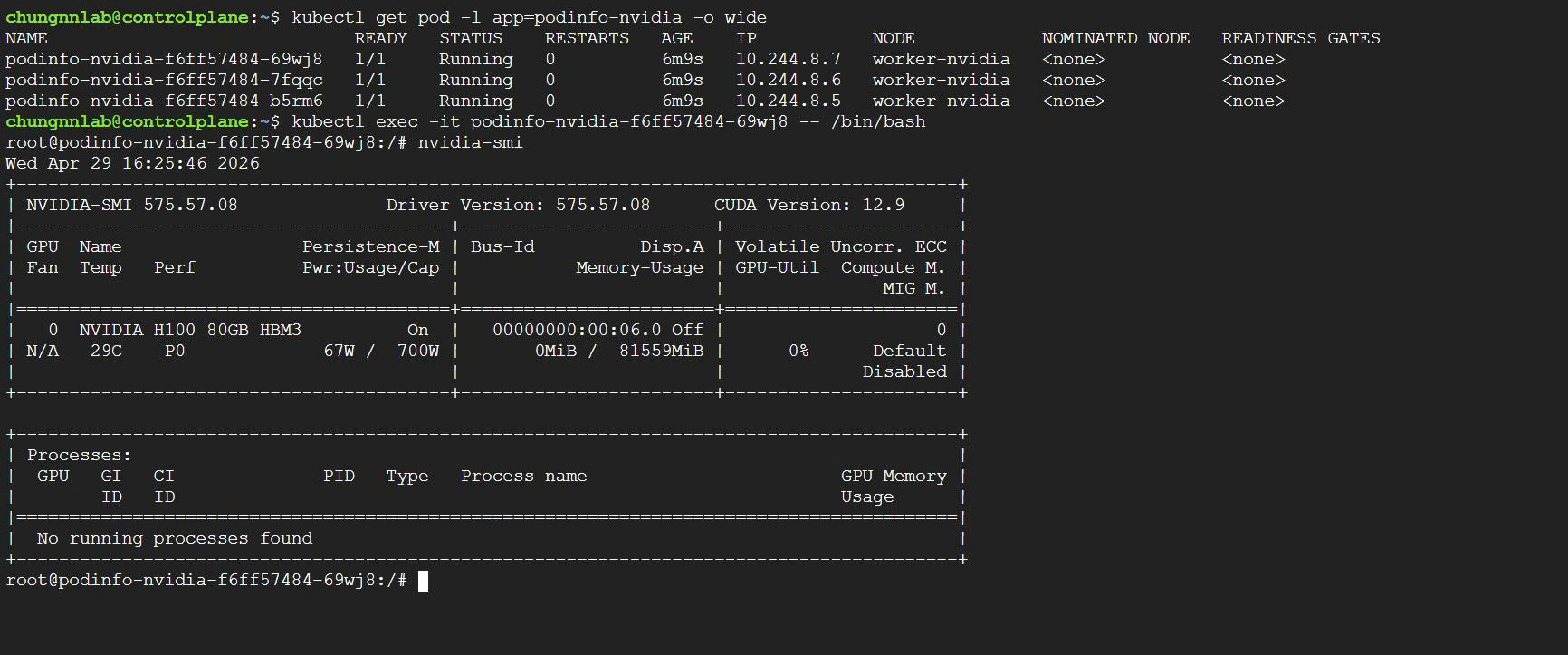 +
+All 3 replicas are running on worker-nvidia as expected. nvidia-smi inside the pod confirms GPU access.
+
+## 4. Key Takeaways
+- One cluster, many runtimes. RuntimeClass lets each pod declare exactly what it needs, runc for trusted workloads, gVisor for untrusted code, nvidia for AI/GPU jobs all coexisting without splitting your infrastructure.
+- Two layers, one contract. CRI runtimes (containerd, CRI-O) manage the full container lifecycle; OCI runtimes (runc, runsc…) handle the actual process execution. The handler name bridges them it must exactly match what is registered in the CRI config, or the pod will never start.
+- Put scheduling logic in the RuntimeClass, not the Deployment. Embedding ```scheduling.nodeSelector``` in the RuntimeClass object automatically routes every pod that references it to a compatible node no need to repeat node selectors across every manifest.
+- Taint first, tolerate selectively. A NoExecute taint on GPU or specialized nodes keeps general workloads off expensive hardware. Embedding the matching tolerations directly in the RuntimeClass ensures only pods using that runtime can ever be scheduled there
+
+## 5. Going Further
+This blog has covered the core concepts and practical patterns of RuntimeClass, but there is still plenty more to explore:
+
+- Scheduling real AI/ML workloads with GPU resource limits (nvidia.com/gpu) alongside the NVIDIA Device Plugin to fully unlock hardware capacity.
+- Hardening multi-tenant platforms by running customer workloads under gVisor while keeping internal services on runc all within the same cluster.
+- Adopting emerging runtimes like WebAssembly (runwasi) or confidential computing (Intel TDX, AMD SEV), where RuntimeClass is already the natural integration point.
+- Layering RuntimeClass with Pod Security Admission and OPA/Gatekeeper policies to build a complete, defense-in-depth workload isolation strategy.
+
+### References
+
+- [Kubernetes RuntimeClass - Official Docs](https://kubernetes.io/docs/concepts/containers/runtime-class/)
+- [Container Runtime Interface (CRI)](https://kubernetes.io/docs/concepts/architecture/cri/)
+- [Medium - Kubernetes RuntimeClass tutorial](https://alibaba-cloud.medium.com/getting-started-with-kubernetes-understanding-kubernetes-runtimeclass-and-using-multiple-33428ee4cae5)
+- [iximiuz Labs - Kubernetes RuntimeClass tutorial](https://labs.iximiuz.com/tutorials/kubernetes-runtime-class-61506808)
+- [OCI Runtime Specification](https://github.com/opencontainers/runtime-spec)
+- [gVisor - runsc](https://gvisor.dev/)
+- [cri-dockerd releases](https://github.com/Mirantis/cri-dockerd/releases)
+- [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)
+- [NVIDIA Device Plugin for Kubernetes](https://github.com/NVIDIA/k8s-device-plugin)
+
+
+All 3 replicas are running on worker-nvidia as expected. nvidia-smi inside the pod confirms GPU access.
+
+## 4. Key Takeaways
+- One cluster, many runtimes. RuntimeClass lets each pod declare exactly what it needs, runc for trusted workloads, gVisor for untrusted code, nvidia for AI/GPU jobs all coexisting without splitting your infrastructure.
+- Two layers, one contract. CRI runtimes (containerd, CRI-O) manage the full container lifecycle; OCI runtimes (runc, runsc…) handle the actual process execution. The handler name bridges them it must exactly match what is registered in the CRI config, or the pod will never start.
+- Put scheduling logic in the RuntimeClass, not the Deployment. Embedding ```scheduling.nodeSelector``` in the RuntimeClass object automatically routes every pod that references it to a compatible node no need to repeat node selectors across every manifest.
+- Taint first, tolerate selectively. A NoExecute taint on GPU or specialized nodes keeps general workloads off expensive hardware. Embedding the matching tolerations directly in the RuntimeClass ensures only pods using that runtime can ever be scheduled there
+
+## 5. Going Further
+This blog has covered the core concepts and practical patterns of RuntimeClass, but there is still plenty more to explore:
+
+- Scheduling real AI/ML workloads with GPU resource limits (nvidia.com/gpu) alongside the NVIDIA Device Plugin to fully unlock hardware capacity.
+- Hardening multi-tenant platforms by running customer workloads under gVisor while keeping internal services on runc all within the same cluster.
+- Adopting emerging runtimes like WebAssembly (runwasi) or confidential computing (Intel TDX, AMD SEV), where RuntimeClass is already the natural integration point.
+- Layering RuntimeClass with Pod Security Admission and OPA/Gatekeeper policies to build a complete, defense-in-depth workload isolation strategy.
+
+### References
+
+- [Kubernetes RuntimeClass - Official Docs](https://kubernetes.io/docs/concepts/containers/runtime-class/)
+- [Container Runtime Interface (CRI)](https://kubernetes.io/docs/concepts/architecture/cri/)
+- [Medium - Kubernetes RuntimeClass tutorial](https://alibaba-cloud.medium.com/getting-started-with-kubernetes-understanding-kubernetes-runtimeclass-and-using-multiple-33428ee4cae5)
+- [iximiuz Labs - Kubernetes RuntimeClass tutorial](https://labs.iximiuz.com/tutorials/kubernetes-runtime-class-61506808)
+- [OCI Runtime Specification](https://github.com/opencontainers/runtime-spec)
+- [gVisor - runsc](https://gvisor.dev/)
+- [cri-dockerd releases](https://github.com/Mirantis/cri-dockerd/releases)
+- [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)
+- [NVIDIA Device Plugin for Kubernetes](https://github.com/NVIDIA/k8s-device-plugin)
+