Hello, I have two questions about your loss functions.
In your paper, the Illumination-guided noise estimation loss is shown as:

But in your codes, wn(x) represents illumination and wr(x) is also computed using illumination instead of the whole image I(x).
def reflectance_smooth_loss(image, illumination, reflectance):
gray_tensor = 0.299image[0,0,:,:] + 0.587image[0,1,:,:] + 0.114image[0,2,:,:]
gradient_gray_h, gradient_gray_w = gradient(gray_tensor.unsqueeze(0).unsqueeze(0))
gradient_reflect_h, gradient_reflect_w = gradient(reflectance)
weight = 1/(illuminationgradient_gray_hgradient_gray_w+0.0001)
weight = normalize01(weight)
weight.detach()
loss_h = weight * gradient_reflect_h
loss_w = weight * gradient_reflect_w
refrence_reflect = image/illumination
refrence_reflect.detach()
return loss_h.sum() + loss_w.sum() + conf.reffactorch.norm(refrence_reflect - reflectance, 1)
So I want to know why the codes are different from the paper. Did you update it? Because Illumination-guided sounds like actually the illumination but not I(x).
The second question is why you compute I-(RS+N) and R-I/S as loss components at the same time. In my opinion, it's contradictory.
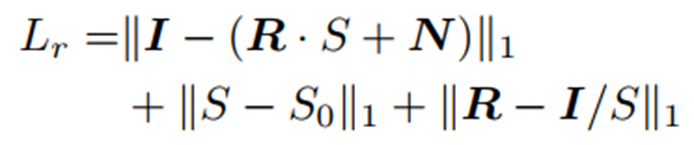
Thanks.
Hello, I have two questions about your loss functions.

In your paper, the Illumination-guided noise estimation loss is shown as:
But in your codes, wn(x) represents illumination and wr(x) is also computed using illumination instead of the whole image I(x).
So I want to know why the codes are different from the paper. Did you update it? Because Illumination-guided sounds like actually the illumination but not I(x).
The second question is why you compute I-(RS+N) and R-I/S as loss components at the same time. In my opinion, it's contradictory.
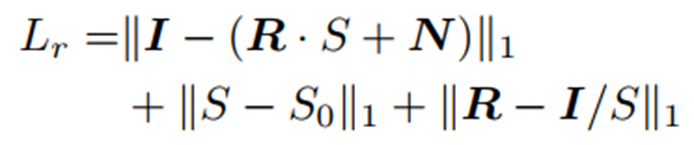
Thanks.