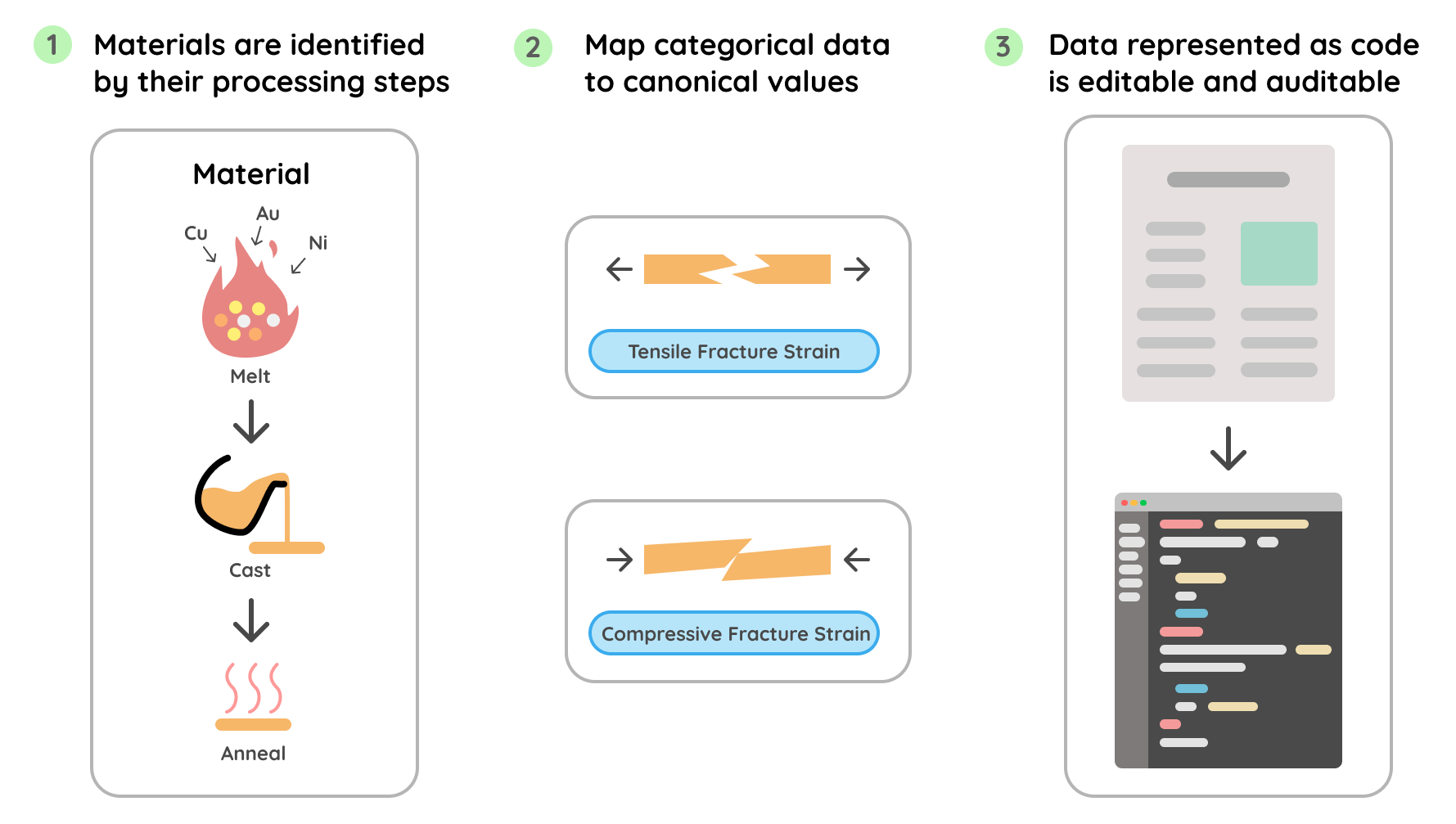
 +
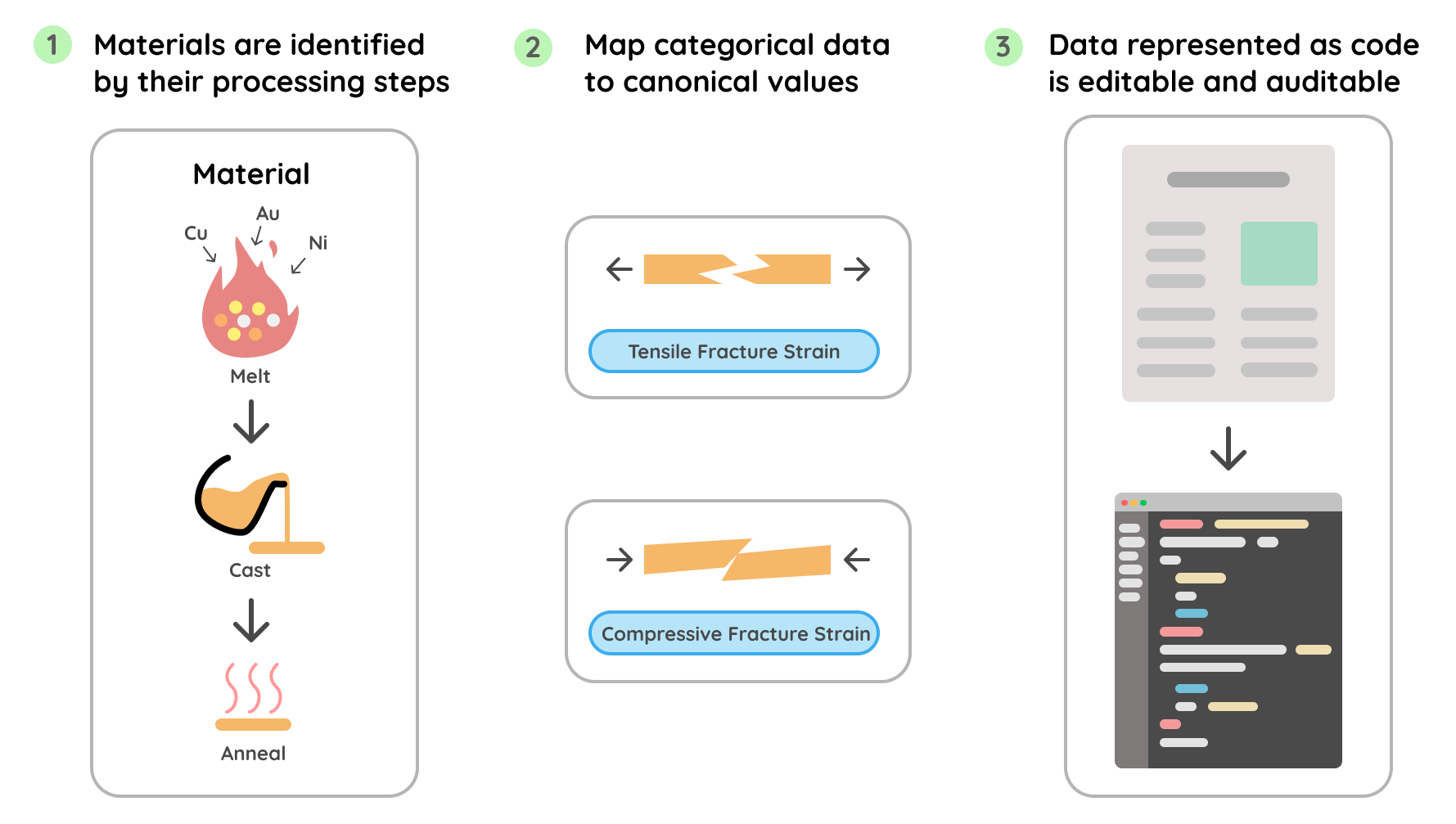
+ 
-
+
If you use LitXBench in your research, please cite:
@article{chong2026litxbench,
- title={LitXBench: A Benchmark for Extracting Experiments from Scientific Literature},
- author={Chong, Curtis and Colindres, Jorge},
- year={2026},
+ title = {LitXBench: A Benchmark for Extracting Experiments from Scientific Literature},
+ author = {Curtis Chong and Jorge Colindres},
+ year = {2026},
+ eprint = {2604.07649},
+ archivePrefix = {arXiv},
+ primaryClass = {cs.IR},
+ url = {https://arxiv.org/abs/2604.07649}
}